Questo file è la rielaborazione delle slide 07_Pipelining.pdf
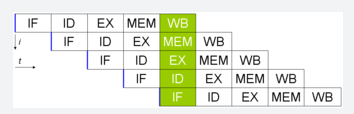
Per svolgere compiti sempre più complessi in tempi ridotti è stata introdotta nei processori la tecnologia del pipelining (idea presa dalle catene di montaggio delle fabbriche) l’obbiettivo di questa tecnica è quello di parallelizzare quante più istruzioni possibili, ricordando la suddivisione delle istruzioni in 5 fasi diverse (Prelievo – Decodifica – Elaborazione – Memoria - Scrittura) nel caso migliore avremo 5 istruzioni eseguite in parallelo. Per gestire l’esecuzione in pipeline di più istruzioni abbiamo bisogno di mantenere le istruzioni tra uno stadio e l’altro, queste istruzioni vengono conservate dai buffer interstadio. Di seguito una pipeline perfetta dove ad un certo punto vengono eseguite 5 istruzioni contemporaneamente.
 Non è sempre possibile avere la situazione ideale infatti possono avvenire delle problematiche di seguito discusse che rallentano l’esecuzione della pipeline.
Non è sempre possibile avere la situazione ideale infatti possono avvenire delle problematiche di seguito discusse che rallentano l’esecuzione della pipeline.
Data Hazard
Questo tipo di conflitto avviene quando un’istruzione richiede un dato da un registro e quel dato non è stato ancora aggiornato dalle istruzioni precedenti.
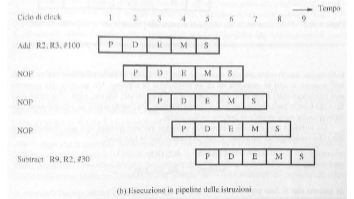
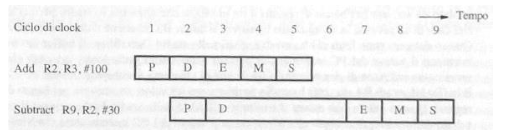 Date le due istruzioni in foto capiamo che l’istruzione Substract dovrà aspettare che l’istruzione Add abbia finito, questo allunga inevitabilmente la durata della pipeline perché Substract resta in stallo aspettando l’aggiornamento del registro R2, per porre un’istruzione in stallo vengono generate delle istruzioni nulle (NOP) che sostanzialmente creano un ciclo di inattività da parte del processore, queste istruzioni vengono generate dal compilatore o via hardware, di seguito le istruzioni dell’esempio precedente ma con l’introduzioni di istruzioni NOP
Date le due istruzioni in foto capiamo che l’istruzione Substract dovrà aspettare che l’istruzione Add abbia finito, questo allunga inevitabilmente la durata della pipeline perché Substract resta in stallo aspettando l’aggiornamento del registro R2, per porre un’istruzione in stallo vengono generate delle istruzioni nulle (NOP) che sostanzialmente creano un ciclo di inattività da parte del processore, queste istruzioni vengono generate dal compilatore o via hardware, di seguito le istruzioni dell’esempio precedente ma con l’introduzioni di istruzioni NOP
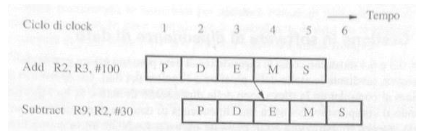
 In questo modo l’istruzione Substract inizia solo quando Add ha finito. Per evitare cicli della CPU a vuoto (ovvero le istruzioni NOP) si fa uso della tecnica dell’operand forwarding, il risultato viene salvato nei registri interstadio sin dalla fase di execute in questo modo l’istruzione che ha bisogno di quel dato non deve aspettare che l’istruzione dalla quale dipende finisca tutte le fasi ma basta che arrivi alla fase di execute.
In questo modo l’istruzione Substract inizia solo quando Add ha finito. Per evitare cicli della CPU a vuoto (ovvero le istruzioni NOP) si fa uso della tecnica dell’operand forwarding, il risultato viene salvato nei registri interstadio sin dalla fase di execute in questo modo l’istruzione che ha bisogno di quel dato non deve aspettare che l’istruzione dalla quale dipende finisca tutte le fasi ma basta che arrivi alla fase di execute.
 altre dipendenze del dato affrontate nei capitoli precedenti
altre dipendenze del dato affrontate nei capitoli precedenti
Ritardi nell’accesso alla memoria
Gli accessi alla memoria alcune volte necessitano di diversi cicli di clock infatti nel caso un dato/istruzione non si trovi nella cache si possono avere ritardi di 10 o più cicli di clock che sarebbe il tempo che ci mette il processore a prendere i dati necessari dalla RAM, questo crea chiaramente dei grandi ritardi nella pipeline.
Control hazards
Si verifica un problema nella pipeline quando vengono eseguiti salti condizionali. Durante l’elaborazione di un’istruzione di salto, l’indirizzo di destinazione viene caricato nel Program Counter (PC) solo al terzo stadio della pipeline (fase di esecuzione). Di conseguenza, le istruzioni già caricate negli stadi successivi della pipeline, che si trovano dopo il salto, risultano errate e devono essere scartate
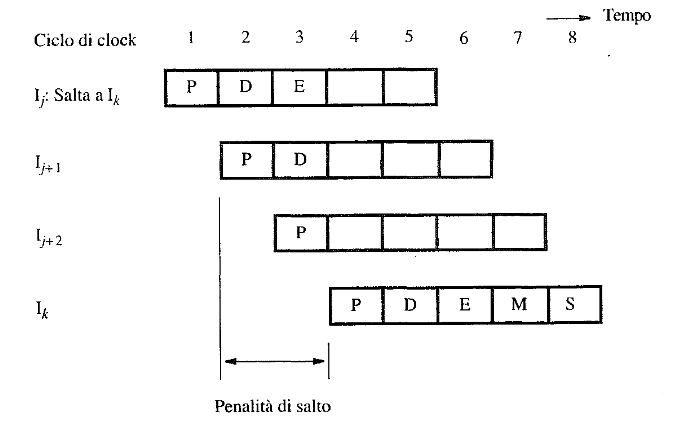 Per mitigare l’impatto dei salti condizionali e migliorare l’efficienza, si possono adottare diverse strategie:
Per mitigare l’impatto dei salti condizionali e migliorare l’efficienza, si possono adottare diverse strategie:
- Salto in fase di decodifica: si può modificare l’hardware in modo da effettuare il salto direttamente nello stadio di decodifica
- Tecnica di salto differito: dove le istruzioni successive al salto vengono eseguite in ogni caso, sarà il compilatore a modificare l’ordine di esecuzione delle istruzioni in modo da eseguire delle istruzioni che vanno eseguite a prescindere negli slice saltati, se non trova istruzioni valide inserisce delle NOP.
Branch penalties
I salti vengono chiamati Branch, i ritardi che accadono a causa dei salti vengono chiamati Branch Delays oppure Branch Penalties questi problemi vengono risolti attraverso le Branch Prediction, se la predizione non va a buon fine abbiamo un Branch Misprediction quando accada questa cosa viene avviato un flush della pipeline dopo la quale la pipeline verrà riempita nel modo giusto. Esistono 2 tipi di branch prediction:
- Predizione statica: usa regole semplici basate su informazioni statiche come la posizione dell’istruzione nel codice o il tipo di istruzione di salto, questo approccio statico è molto rapido e semplice ma può essere meno preciso in situazioni complesse.
- Predizione dinamica: una tecnica che si basa sulla storia dei branch eseguiti in precedenza. Questo approccio sfrutta i buffer di branch prediction (BPB), che fungono da memoria storica per migliorare l’accuratezza della predizione. Più grande è il buffer, maggiore è la precisione della predizione. Ogni branch analizzato viene associato a uno stato, che varia a seconda dell’architettura della macchina:
- In alcune macchine, gli stati possibili sono due:
- PS (Probabilmente Salta)
- PNS (Probabilmente Non Salta)
- In altre macchine, il modello può essere più complesso e utilizzare quattro stati:
- MPS (Molto Probabilmente Salta)
- PS (Probabilmente Salta)
- PNS (Probabilmente Non Salta)
- MPNS (Molto Probabilmente Non Salta) Questo sistema consente di migliorare significativamente la predizione, adattandosi dinamicamente al comportamento dei branch.
- In alcune macchine, gli stati possibili sono due:
Per poter iniziare a fare la predizione dalla fase di Fetch si ha bisogno di una memoria piccola e veloce chiamata Buffer di destinazione di salto questo buffer contiene una tabella con tutte le istruzioni di salto del programma. Per ogni istruzione saranno salvate le seguenti informazioni:
- Indirizzo dell’istruzione
- Uno o due bit di stato per l’algoritmo di predizione
- Indirizzo di destinazione del salto Usando questa tabella ogni volta che viene prelevata un’istruzione, il suo indirizzo verrà cercato nella tabella, se l’istruzione prelevata è un salto si useranno le informazioni in tabella per aggiornare il program counter. In grandi programmi la tabella non contiene tutte le istruzioni di salto, ma viene aggiornata man mano.
Structural Hazards
La pipeline va in stallo quando una risorsa viene richiesta da più istruzioni, per evitare questo problema l’unica soluzione è quella di avere cache separate per istruzione e dati.
Valutazione delle prestazioni
La valutazione delle prestazioni di un processore viene fatta sia per i processori che usano la pipeline sia per quelli che non la usano, la formula chiaramente cambia. Di seguito la legenda per capire le formule successive:
- : Numero di istruzioni macchina
- : Numero di cicli di clock per istruzione (CPI - Cycles Per Instruction)
- : Durata di un ciclo di clock ()
- frequenza di clock del processore
TIP
La formula per calcolare (tempo di esecuzione) di istruzioni in un processore con pipeline è la seguente:
TIP
La formula per calcolare il throughput di un processore è la seguente: Senza pipeline: Con pipeline: nel caso ottimale con pipeline il throughput è uguale ad R
Come già detto la pipeline soffre di conflitti, prendendo in considerazione questi conflitti la formula per il calcolo del throughput diventa:
Formula calcolo del throughput
Ogni tipologia di conflitto indipendente aumenta S di un delta δ dato dal numero di occorrenze del conflitto per il numero medio di cicli di stallo introdotti per evitarlo:
- Conflitti di dipendenza di dato: = ·
- Conflitti di salto: = ·
- Conflitti di cache miss: = ·
Processori superscalari
I processori con più unita di elaborazione vengono chiamati superscalari, nel caso di un processore con 2 unità di elaborazione:
- Unità aritmetica: esegue le istruzione aritmetico-logiche
- Unità Load/Store: esegue le istruzioni di accesso alla memoria
Nel seguente caso la pipeline di questo tipo di processore è diversa da quella di un normale processore, in specifico cambia così:
 Le istruzioni aritmetiche e di accesso alla memoria possono essere eseguite in parallelo a coppie e quindi nei primi due cicli di clock si possono mandare in esecuzione le quattro istruzioni. All’entrata di ogni unità di esecuzione troviamo una stazione di prenotazione dove sono presenti:
Le istruzioni aritmetiche e di accesso alla memoria possono essere eseguite in parallelo a coppie e quindi nei primi due cicli di clock si possono mandare in esecuzione le quattro istruzioni. All’entrata di ogni unità di esecuzione troviamo una stazione di prenotazione dove sono presenti: - Tutte le istruzioni in attesa di esecuzione
- Informazioni e operandi rilevanti per ogni istruzione che troviamo Un’istruzione viene mandata in esecuzione solo quando tutti i suoi operandi sono disponibili
Fase di smistamento nei processori superscalari
Nella fase di smistamento il processore deve assicurarsi che tutte le risorse necessarie ad un’istruzione siano disponibili, in specifico si occupa di verificare la disponibilità dei registri temporanei per contenere i risultati, che ci sia abbastanza spazio nella stazione di prenotazione dell’unità di esecuzione desiderata, e che ci sia una locazione disponibile nel buffer di riordino, inoltre si occupa di prevenire i deadlock (casi in cui due istruzioni rimangono bloccate a causa di dipendenze reciproche)
Esecuzione fuori ordine nei processori superscalari
L’esecuzione fuori ordine nei processori superscalari migliora l’efficienza eseguendo istruzioni non appena pronte, ma può causare conflitti o eccezioni imprecise. Per evitare errori, i risultati vengono salvati in registri temporanei tramite il register renaming. L’unità di commitment, supportata dal buffer di riordino, trasferisce poi i risultati ai registri permanenti rispettando l’ordine originale delle istruzioni, garantendo coerenza e correttezza nell’esecuzione.
Pipeline con i processori CISC
I processori CISC hanno diverse difficoltà nell’utilizzare le pipeline a causa della complessità delle istruzioni, per risolvere questo problema quasi tutti i processori odierni sono si basati su CISC ma le istruzioni vengono dinamicamente convertite in micro-istruzioni RISC che posso essere eseguite nella pipeline in modo più agevole.