Questo file è la rielaborazione delle slide 05_Processore, approfondimento con codice assembly qui: 08_Struttura-base-del-processore
Un processore è un singolo circuito integrato in grado di effettuare operazioni decisionali, di solito viene indicato con la sigla CPU (Central Processing Unit), il processore viene concettualmente diviso in 3 unità funzionali:
- UC (Control Unit): si affaccia sul bus e lo arbitra impostando i valori nelle linee ABus, DBus e CBus
- Registri: sono delle memorie di lavoro dove vengono conservati i dati presi dall’UC sul bus per poi poterli far usare dalla ALU durante l’esecuzione
- ALU (Arithmetic logic unit): è l’unita di esecuzione effettiva del processore
Ogni processore viene progettato con un set di istruzioni specifico denominato ISA (Instruction Set Architecture) o IS (Instruction Set), ogni istruzione dell’ISA è contraddistinta da un numero specifico denominato Operation Code(OP) ad ogni OP si associa una breve descrizione in lingua naturale che ne ricorda la funzione.
L’ALU, i registri e molti bus costituiscono il data path, che si presenta in questo modo:
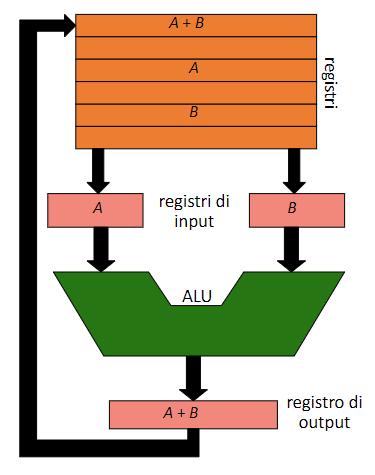 Le istruzioni che devono essere usate dalla ALU, vengono caricate nei registri di input (che solitamente sono 2), la ALU fornisce il suo risultato nel registro di output (che solitamente è 1), infine il risultato verrà memorizzato nei registri, quello appena descritto è il ciclo del data path, ovvero la sequenza di passaggi che il computer esegue per eseguire un’operazione tramite la ALU (corrisponde alla fase di execute del ciclo macchina)
Le istruzioni che devono essere usate dalla ALU, vengono caricate nei registri di input (che solitamente sono 2), la ALU fornisce il suo risultato nel registro di output (che solitamente è 1), infine il risultato verrà memorizzato nei registri, quello appena descritto è il ciclo del data path, ovvero la sequenza di passaggi che il computer esegue per eseguire un’operazione tramite la ALU (corrisponde alla fase di execute del ciclo macchina)
In base al tipo di Instruction set vengono definiti vari tipi di processore
- CISC (Complex Istruction Set Computer): basati su molte istruzioni complicate
- RISC (Reduced Istruction Set Computer): basati su poche e semplici istruzioni
- CRISC (Complex Reduced Instruction Set Code): quello più usato attualmente, è un architettura ibrida tra CISC e RISC
Nota
Il Program Counter (PC) è un registro della CPU che contiene l’indirizzo della prossima istruzione da eseguire.
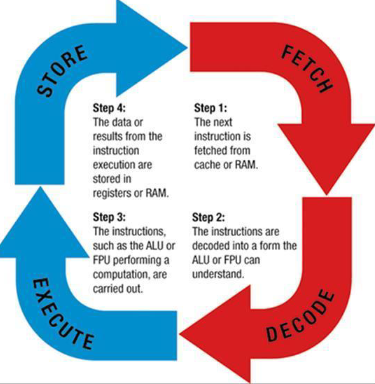
Un tipico processore opera seguendo una sequenza rigida di passi, che si ripetono fino all’arresto della macchina. Questi passi sono i seguenti:
- Fetch: L’Unità di Controllo (UC) carica nel bus degli indirizzi (ABus) il valore del Program Counter, attivando la lettura dalla memoria e caricando l’OpCode dell’istruzione corrente.
- Decode: L’UC, interpretando l’OpCode appena letto, determina la lunghezza dell’istruzione e quanti parametri sono necessari. Inizia quindi una fase intermedia, chiamata Operand Fetch, per caricare gli operandi, che si trovano in indirizzi consecutivi a quello dell’OpCode. Gli operandi vengono quindi memorizzati nei registri.
- Execute: L’UC avvia il microprogramma corrispondente all’OpCode, utilizzando i parametri precedentemente caricati nei registri. La frequenza con cui vengono eseguiti questi microprogrammi è regolata dal clock della CPU, cioè la frequenza del microprocessore.
- Store: Al termine dell’operazione di Execute, i risultati, ora memorizzati nei registri, vengono trasferiti sul bus dall’UC. Questi possono essere scritti in memoria o inviati a dispositivi di input/output (PIO).
Questa sequenza continua a ripetersi per ogni istruzione fino al completamento o arresto del programma.
 Questo ciclo può interrompersi se arriva alla CPU un segnale di INTR (della quale abbiamo parlato qui 04_InputOutput)
Questo ciclo può interrompersi se arriva alla CPU un segnale di INTR (della quale abbiamo parlato qui 04_InputOutput)
Ogni singola istruzione dell’IS di un processore è contraddistinta da un proprio Op. Code, una determinata lunghezza e un preciso numero di cicli di bus per il suo completamento, il tempo effettivo di esecuzione dell’istruzione è poco influente sulla durata totale di un’istruzione, infatti il bus è un’ordine di grandezza più lento rispetto alla CPU (questo va a creare il già discusso collo di bottiglia)
CISC vs RISC
CISC Le CPU CISC dispongono di un set di istruzioni ampio e complesso, progettato per eseguire operazioni di alto livello con un numero ridotto di istruzioni. Questo comporta però che ogni istruzione sia relativamente più lunga da eseguire, poiché richiede più cicli di clock e implica molteplici passaggi nel data path della CPU.
RISC Le CPU RISC sono progettate con un set di istruzioni più semplice e costante, con comandi che richiedono un solo ciclo di clock per essere eseguiti. Questo approccio rende il data path della CPU molto più lineare e veloce, facilitando una rapida esecuzione delle istruzioni.
| Caratteristica | CISC | RISC |
|---|---|---|
| Pro | - Flessibilità: istruzioni complesse eseguono operazioni elaborate con poche istruzioni. - Compatibilità: architettura comune (es. x86), ampio supporto software. - Efficienza di memoria: istruzioni più complesse possono ridurre il numero complessivo di istruzioni necessarie. | - Alta velocità: istruzioni semplici eseguite in un singolo ciclo di clock, maggiore rapidità. - Efficienza energetica: consumo energetico ridotto per via della semplicità delle istruzioni. - Facilità di ottimizzazione: progettazione più semplice per prestazioni ottimali. |
| Contro | - Bassa efficienza: esecuzione più lenta per il numero elevato di cicli di clock necessari per ogni istruzione. - Maggiore consumo energetico: istruzioni complesse richiedono più energia. - Difficoltà di ottimizzazione: architettura complessa, meno ottimizzabile per velocità e prestazioni. | - Maggiore carico di programmazione: servono più istruzioni per compiti complessi. - Maggiore consumo di memoria: necessità di più istruzioni, che occupano più spazio. - Minor compatibilità software: adattamenti necessari per software sviluppato su CISC. |
| I processori moderni sono ibridi, ovvero usano un tipo di architettura chiamata CRISC (Complex Reduced Instruction Set Computer) cercando di ottenere i vantaggi di uno e dell’altro. |
Come abbiamo capito il problema principale che causa un rallentamento della CPU è l’accesso alle risorse dal bus, per diminuire questi accessi e quindi aumentare il throughput si fa uso delle cache, una memoria “tampone” sulla quale vengono caricate le istruzioni più utilizzate dal processore, ad ogni operazione di lettura che fa il processore, controlla se l’informazione che gli serve è già nella cache in modo da poterci accedere in maniere più veloce, se non c’è il processore la richiede tramite il bus e sovrascrive l’istruzione meno usata che si trova nella cache con quella che ha appena richiesto. Esistono 3 tipi di cache:
- L-1: che si trova all’interno del processore
- L-2: che è collegata al processore
- L-3: sulla motherboard Si può dire che la cache sia genericamente più veloce del bus, ma più si alza il livello di cache più questa differenza diminuisce.
Prefetch
Per aumentare il parallelismo di esecuzione viene usata la tecnica del prefetching che dice alla CPU che anziché limitarsi a caricare dalla memoria l’istruzione o il dato richiesto al momento, recuperi in anticipo anche le istruzioni o i dati immediatamente successivi. A questo scopo, i processori dispongono di una “coda di prefetch”, un buffer interno che può contenere una certa quantità di dati consecutivi (ad esempio, i 6 o 8 byte successivi a quello appena caricato). In questo modo, il processore effettua un singolo accesso alla memoria per caricare una serie di valori che possono essere utilizzati subito dopo, sia come istruzioni che come operandi.
Esistono 4 tipi di prefetch
- Prefetching hardware: le CPU hanno un componente hardware al loro interno che rileva automaticamente i data pattern (dati che servono molte volte e seguono quindi una sorta di pattern nel loro utilizzo) nella memoria e li carica preventivamente nella cache.
- Prefetching software: nel prefetching software si usano delle variabili per suggerire alla CPU che certi dati saranno utilizzati molto spesso, quindi cosi la CPU li caricherà nella cache senza passare ogni volta dal BUS.
- Tecnica di ottimizzazione in fase di compilazione : è un metodo che in fase di compilazione identifica le linee di codice e i dati che vanno utilizzati di più. Questo è un modo per ottimizzare il codice. Funziona con compilatori moderni (C,C++ ecc…)
- Prefetching con accesso alla linee di cache: utilizza le linee di cache per l’accesso alla memoria, quindi trasporta dei blocchi fissi, da 64 byte solitamente, direttamente alla cache.
L’elaborazione di un’istruzione
L’elaborazione di un’istruzione da parte di un processore con pipeline si articola in cinque fasi principali:
- IF (Instruction Fetch): Recupero dell’istruzione dalla memoria.
- ID (Instruction Decode): Decodifica dell’istruzione e lettura degli operandi dai registri.
- EX (Execution): Esecuzione dell’istruzione.
- MEM (Memory Access): Interazione con la memoria (valida solo per alcune istruzioni).
- WB (Write Back): Scrittura del risultato nel registro.
Queste fasi, sequenziali e talvolta sovrapposte, permettono al processore di eseguire le operazioni previste dalle istruzioni.
Pipeline
Alla coda di prefetch, è stato affiancato un sistema detto pipeline che ha lo scopo di sfruttare il concetto di catena di montaggio e quindi di parallelizzare più istruzioni possibili invece di eseguire un’istruzione completamente prima di eseguire la sua successiva. Basta che la prima istruzione sia in fase di decode che la seconda possa essere portata in fase di fetch.
-
Senza pipeline

-
Con pipeline
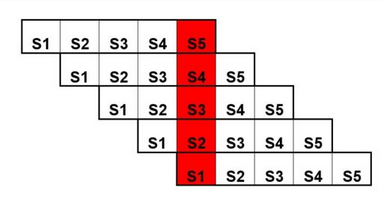
Come possiamo ben notare una pipeline a 5 stadi esegue 5 fasi contemporaneamente, questa tecnica sopperisce al problema dell’accesso alla memoria precedentemente discusso. L’uso della pipeline introduce anche delle problematiche:
- Data hazards: si verifica quando un istruzione richiede dei dati che vengono forniti da un altra istruzione che non ha ancora finito (ritardi di elaborazione o blocchi)
- Control hazards: si verifica quando la pipeline deve gestire dei salti condizionali (tipo il go-to)
- Structural hazards: si verifica quando più istruzioni cercano di accedere alla stessa risorsa (problemi dei filosofi a cena)
Dopo aver dotato i primi processori di pipeline si ci è resi conto che la fase più lenta diventava la fase di execute (quella implementata nella ALU) per sopperire a questo problema si montano più ALU dentro ad un singolo processore. Un processore con più ALU è detto Superscalare
I problemi del prefetching e della pipeline
Tutte queste tecniche vengono vanificate da 2 situazioni:
- Istruzioni di salto: la pipeline viene del tutto persa se il salto ci porta ad un’istruzione lontana da quella che si trova attualmente in pipeline
- Dipendenza dei dati tra le istruzioni: la pipeline viene interrotta Esempio:
- Istruzione1: A = B + C.
- Istruzione2: D = A + 1.
- La pipeline che sta servendo l’Istruzione 2 deve interrompersi allo stadio di operand fetch, dato che A non è disponibile se non quando l’Istruzione 1 non è del tutto terminata.
Per cercare di arginare il problema delle istruzioni di salto sono stati introdotti nel processore dei moduli chiamati Dynamic Branch Prediction che si occupano di implementare l’esecuzione predicativa, una tecnica che fa uso di tabelle simili a memorie cache, per cercare di capire se un’istruzione di salto avverrà o meno (questa tecnica non è deterministica infatti si basa solo su una statistica storica), il problema principale di questa tecnica si ha quando la previsione fatta è sbagliata, infatti in quel caso la pipeline va ripristinata. L’esecuzione predicativa è anche nota come esecuzione speculativa quando va a fare una predizione sul codice che potrebbe non essere mai utilizzato.
Per cercare di arginare il problema delle dipendenze da dato si usa l’esecuzione fuori ordine(out of order execution) ovvero: quando il processore individua una dipendenza in un pipeline al posto di buttarla salta l’istruzione dipendente per eseguire istruzioni future, in questo modo la pipeline viene quasi del tutto conservata (un solo stadio rimane fermo fino all’arrivo del dato mancante), alla risoluzione della dipendenza saranno già state eseguite altre istruzioni (quelle che avevamo chiamato istruzioni «future»), con conseguente risalita delle prestazioni. Ci sono però delle condizioni critiche:
- Le istruzioni “future” possono essere eseguite solo se non sono dipendenti a loro volta
- Quando il processore si trova fuori ordine e arriva un interrupt, il processore deve ripristinare il suo stato e riordinare anche il giusto flusso di esecuzione
Per poter riordinare il giusto flusso di esecuzione dopo aver saltato e ricalcolato una istruzione con dipendenza, i processori utilizzano una serie di registri d’appoggio (interni e invisibili al programmatore) su cui memorizzare i calcoli temporanei delle istruzioni fuori ordine. All’atto del riordinamento, per evitare di spostare i valori dai registri interni a quelli effettivamente usati nel data path, i processori sono in grado di rinominare i registri interni nei nomi dei registri effettivi, risparmiando il tempo del trasferimento (register renaming).
Esistono 3 tipi di dipendenza del dato:
-
RAW (Read After Write): Si verifica quando un’istruzione legge un dato che è stato scritto da una precedente istruzione. È chiamata anche dipendenza vera o data dependency, perché un dato deve essere prodotto prima di essere letto.
- Esempio:
Istruzione 1: A = 5,Istruzione 2: B = A + 1. L’istruzione 2 dipende dal valore diAprodotto dalla prima.
- Esempio:
-
WAW (Write After Write): Si verifica quando due istruzioni scrivono nello stesso dato. La seconda scrittura deve avvenire dopo la prima per non sovrascrivere accidentalmente il valore prodotto dalla prima. Questa è una dipendenza anti o di output.
- Esempio:
Istruzione 1: A = 5,Istruzione 2: A = 10. Qui la seconda scrittura sovrascrive il valore diAdella prima istruzione.
- Esempio:
-
WAR (Write After Read): Si verifica quando una istruzione scrive su un dato che viene letto da una precedente istruzione. Questa dipendenza è detta anti-dipendenza, perché la scrittura deve avvenire solo dopo la lettura per evitare che il valore letto sia alterato.
- Esempio:
Istruzione 1: B = A + 1,Istruzione 2: A = 3. La seconda istruzione deve aspettare che la prima leggaAprima di scrivere su di esso.
- Esempio:
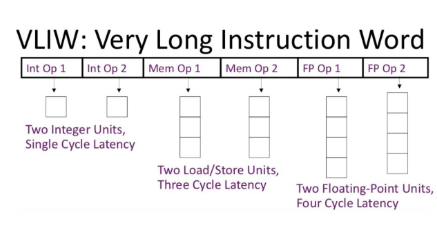
Anche se non esplicitamente, tutte queste innovazioni (pipeline, super-scalarità, predicazione, esecuzione fuori ordine) cercano di implementare un modello di esecuzione parallelo molto studiato nei centri di calcolo, e denominato VLIW (Very Long Instruction Word). In questo modello, oltre alla parallelizzazione dell’esecuzione ottenuta in hardware, si presuppone che lo stesso codice esecutivo generato dai compilatori sia «pre-cucinato» per essere parallelizzato ottimamente dalle CPU.