La CPU è un circuito elettronico integrato che ha il ruolo di cervello del calcolatore, e capace di eseguire istruzioni elementari necessarie per eseguire i programmi. É formato da diversi componenti:
- La ALU (Unità logico-aritmetica): esegue le operazioni aritmetiche e logiche necessarie ad eseguire un programma
- CU (Control Unit): genera i bit di controllo per gestire il funzionamento della CPU
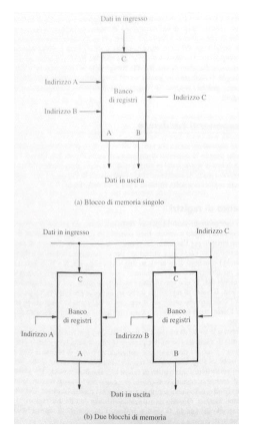
- Banco di registri: blocchi di memoria usati dalla CPU durante l’esecuzione delle istruzioni
- PC (Program counter): un registro che contiene l’indirizzo della prossima istruzione da eseguire
- IR (Istruction Register): un registro che contiene l’indirizzo dell’istruzione in esecuzione
- Generatore di indirizzi: un componente che si occupa di aggiornare il contenuto del PC
- Interfaccia processore memoria: gestisce il trasferimento dei dati tra memoria e CPU
Di seguito i componenti in specifico:
Banco di registri: un blocco di memoria piccolo e veloce, consiste in vari registri con un circuito per l’accesso in scrittura e lettura. È possibile leggere contemporaneamente i dati da due registri diversi, invece la lettura può avvenire da un registro alla volta, per selezionare il registro da leggere o scrivere, si utilizzano specifici ingressi di indirizzo.
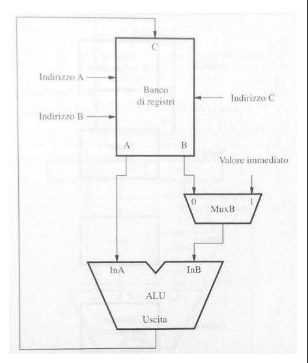
 ALU: un componente della CPU che esegue operazioni aritmetiche e logiche quali la somma, sottrazione, AND, OR, XOR, ecc. É formato da 2 porte di input che rappresentano gli operandi in ingresso collegate direttamente al banco dei registri, una porta di uscita contenente il risultato dell’operazione anche questa collegata al banco dei registri. Insieme alla ALU viene usato il MUX (un multiplexer) che è in grado di introdurre un altro valore all’interno della ALU (come vedi nell’immagine di seguito)
ALU: un componente della CPU che esegue operazioni aritmetiche e logiche quali la somma, sottrazione, AND, OR, XOR, ecc. É formato da 2 porte di input che rappresentano gli operandi in ingresso collegate direttamente al banco dei registri, una porta di uscita contenente il risultato dell’operazione anche questa collegata al banco dei registri. Insieme alla ALU viene usato il MUX (un multiplexer) che è in grado di introdurre un altro valore all’interno della ALU (come vedi nell’immagine di seguito)
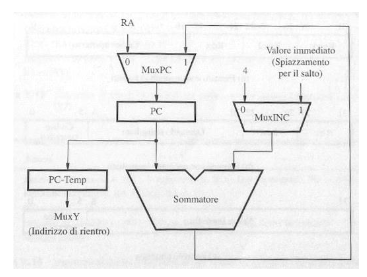
 Generatore di indirizzi delle istruzioni: questo circuito è usato per generare l’indirizzo della prossima istruzione da inserire nel PC. In questo componente troviamo un sommatore che incrementa il valore del PC di una word solitamente (4 byte) o anche di più in caso di salto. Sarà il MuxINC seleziona che tipo di incremento effettuare, il MUXPC seleziona se aggiornare il PC con l’incremento calcolato dal MuxINC o con un indirizzo specifico, inoltre abbiamo PC-Temp che viene usato per salvare il valore di PC da inserire nel LR durante una chiamata a sottoprogramma.
Generatore di indirizzi delle istruzioni: questo circuito è usato per generare l’indirizzo della prossima istruzione da inserire nel PC. In questo componente troviamo un sommatore che incrementa il valore del PC di una word solitamente (4 byte) o anche di più in caso di salto. Sarà il MuxINC seleziona che tipo di incremento effettuare, il MUXPC seleziona se aggiornare il PC con l’incremento calcolato dal MuxINC o con un indirizzo specifico, inoltre abbiamo PC-Temp che viene usato per salvare il valore di PC da inserire nel LR durante una chiamata a sottoprogramma.
 Per eseguire un istruzione il processore esegue i seguenti passi:
Per eseguire un istruzione il processore esegue i seguenti passi:
- Prelievo dell’istruzione della memoria (all’indirizzo puntato da PC)
- Incremento di PC di una word (per farlo puntare all’istruzione successiva)
- Esecuzione dell’istruzione prelevata i primi due passi si chiamano fase di prelievo e il terzo fase di esecuzione, durante la fase di esecuzione si possono svolgere diverse azioni sono molteplici tra cui troviamo: lettura/scrittura da una locazione di memoria, lettura da registri, esecuzione di operazioni aritmetiche, ecc… Esempio con delle istruzioni assembly:
- LOAD R5, X(R7)
questa istruzione carica il valore del registro con indirizzo in R5 e viene eseguita in questo modo:
- Prelievo dell’istruzione ed incremento del PC: Il processore legge l’istruzione dalla memoria e incrementa il Program Counter (PC) per puntare all’istruzione successiva.
- Decodifica dell’istruzione e lettura del contenuto del registro R7: Il processore decodifica l’istruzione per capire quale operazione deve eseguire e legge il valore contenuto nel registro R7.
- Calcolo dell’indirizzo effettivo: Il processore somma il valore contenuto in R7 con l’offset X per ottenere l’indirizzo di memoria esatto da cui leggere il dato.
- Lettura dell’operando sorgente dalla memoria: Il processore accede alla memoria all’indirizzo calcolato al punto precedente e legge il valore che trova in quella locazione.
- Caricamento dell’operando nel registro di destinazione R5: Il valore letto dalla memoria viene copiato nel registro R5, sovrascrivendo qualsiasi valore precedentemente presente in quel registro.
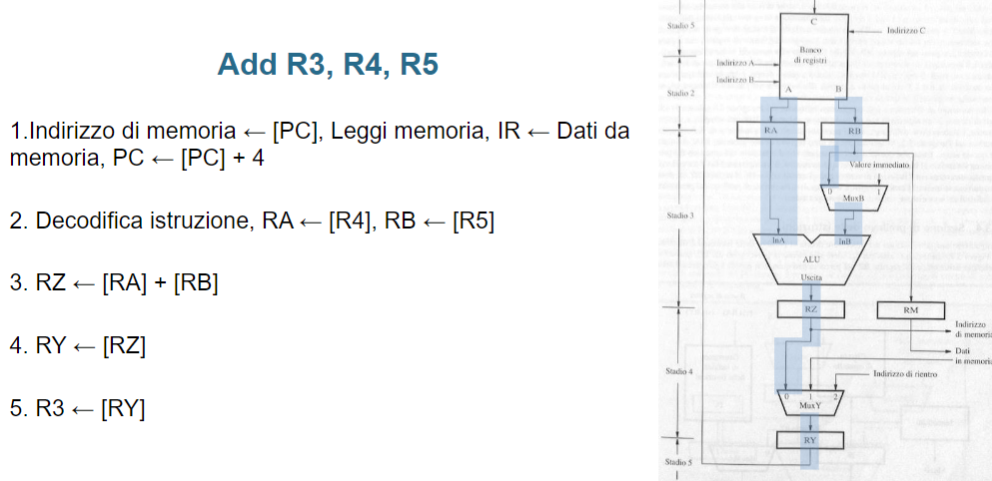
- ADD R3, R4, R5
- Prelievo dell’istruzione ed incremento del PC
- Decodifica dell’istruzione e lettura dei contenuti dei registri sorgenti R4 e R5
- Calcolo della somma R4 + R5
- Caricamento del risultato nel registro di destinazione R3
In generale qualsiasi istruzione può essere eseguita in 5 stadi distinti:
- Preleva un istruzione e incrementa il contatore del programma
- Decodifica l’istruzione e leggi registri dal banco dei registri
- Esegui un’operazione dell’ALU
- Leggi o scrivi dati in memoria
- Scrivi il risultato nel registro di destinazione
Per temporizzare il processore è necessario un segnale elettrico periodico che scandisce il tempo all’interno del processore che viene comunemente chiamato segnale di clock. Quest’ultimo come un metronomo, indica ai vari componenti quando eseguire una determinata operazione. Il clock sincronizza il movimento dei dati all’interno del processore, assicurando che ogni componente riceva e elabori i dati nel momento giusto. La divisione in stadi introdotta precedentemente viene ripresa di seguito con degli approfondimenti sul perché la preferiamo. Calcolo in un solo stadio:
- Svantaggi: Se si volesse eseguire un’intera operazione in un singolo ciclo di clock, il ciclo dovrebbe essere molto lungo. Questo perché il circuito dovrebbe avere il tempo sufficiente per completare tutte le fasi dell’operazione, dalla lettura dei dati, all’esecuzione dei calcoli, fino alla scrittura del risultato.
- Limiti di performance: Un ciclo di clock lungo limita la frequenza di funzionamento del processore, riducendone le prestazioni. Divisione in più stadi:
- Vantaggio: Dividendo l’esecuzione in più stadi più semplici, è possibile accorciare la durata di ciascun ciclo di clock.
- Pipeline: con l’introduzione della pipeline otteniamo dei grandi vantaggi dalla parallelizzazione dei singoli stadi.
- Registri temporanei: Tra uno stadio e l’altro vengono inseriti dei registri temporanei che memorizzano i dati intermedi, consentendo il passaggio fluido da uno stadio all’altro.
Questa è la rappresentazione grafica del data path in modo approfondito (qui la spiegazione semplificata)
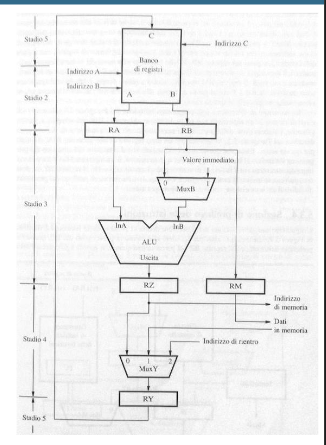 Quello che vediamo in questa immagine può essere riassunto in questo modo:
Stadio 2:
Quello che vediamo in questa immagine può essere riassunto in questo modo:
Stadio 2:
- Testo: Le porte di uscita
AeBdel banco di registri copiano i dati nei registri temporaneiRAeRB. - Nel diagramma:
- Il banco di registri fornisce i valori richiesti dalle porte
AeB. - Questi valori vengono copiati rispettivamente nei registri
RAeRB. Stadio 3:
- Il banco di registri fornisce i valori richiesti dalle porte
- Testo:
RAviene usato come primo ingresso dell’ALU.MuxBdecide se il secondo ingresso dell’ALU proviene daRBo da un valore immediato.- Il risultato dell’ALU è copiato in
RZ. - Il valore di
RBè copiato inRM.
- Nel diagramma:
RAè connesso direttamente al primo ingresso dell’ALU.MuxBseleziona traRBe un valore immediato per il secondo ingresso dell’ALU.- Il risultato dell’ALU (
RZ) viene memorizzato. - Parallelamente, il contenuto di
RBè inviato al registro temporaneoRM. Stadio 4:
- Testo:
- Se necessario, l’indirizzo contenuto in
RZè inviato all’interfaccia del processore con la memoria. - Se richiesto, i dati in
RMsono salvati in memoria. MuxYseleziona il valore da memorizzare inRY: può essere il risultato dell’ALU, un dato dalla memoria, o un indirizzo di ritorno da subroutine.
- Se necessario, l’indirizzo contenuto in
- Nel diagramma:
RZpuò essere utilizzato come indirizzo per accedere alla memoria.- I dati temporanei in
RMpossono essere scritti in memoria, se necessario. - Il
MuxYdecide quale valore salvare inRY. Stadio 5:
- Testo: Il contenuto di
RYviene salvato nel banco di registri. - Nel diagramma:
- L’uscita di
RYè connessa alla porta di ingressoCdel banco di registri. - Il dato è quindi memorizzato nel registro corrispondente.
Stadio 1 (non visibile in foto):
in questo stadio il datapath si occupa di prelevare i dati dalla memoria, in questo stadio troviamo un multiplexer che decide se prendere l’indirizzo di memoria o da un registro oppure dal PC, fatto ciò mette decodifica l’istruzione e la mette in esecuzione.
Esempio:
 Non sempre gli accessi alla memoria possono essere eseguiti in un singolo ciclo di clock, infatti se una risorsa non si trova dentro la cache (cache miss) ci voglio molteplici cicli di clock per recuperarla, quando questo succede la CU dei processori si mette in ascolto aspettando un segnale chiamato MFC (memory function completed) che indica il coretto caricamento in memoria di un dato.
Non sempre gli accessi alla memoria possono essere eseguiti in un singolo ciclo di clock, infatti se una risorsa non si trova dentro la cache (cache miss) ci voglio molteplici cicli di clock per recuperarla, quando questo succede la CU dei processori si mette in ascolto aspettando un segnale chiamato MFC (memory function completed) che indica il coretto caricamento in memoria di un dato.
- L’uscita di
Per eseguire le istruzioni macchina il processore deve generare le sequenze di segnali di controllo per ogni stadio, questi segnali si dividono in:
- Segnali di selezione per i multiplatori
- Segnali di attivazione di alcuni registri
- Segnali di condizione
- Segnali per la gestione della memoria
Un approccio per generare i segnali di controllo consiste nel controllo cablato formato dai seguenti componenti:
- Contatore dei passi: modulo 5 che scandisce gli stadi di esecuzione, questo contatore all’inizio dell’esecuzione di un’istruzione ha come valore 0 che aumenta fino a 5 per ogni stadio di esecuzione
- Decodificatore di istruzione: genera un vettore lungo m mettendo a 1 solo il bit corrispondente all’istruzione letta su IR
- Generatore dei segnali di controllo: produce i segnali di controllo sulla base dell’istruzione in esecuzione, dello stadio attuale (letto dal contatore), dei segnali di condizione e di segnali esterni come le interruzioni. I segnali generati sono predefiniti a livello hardware
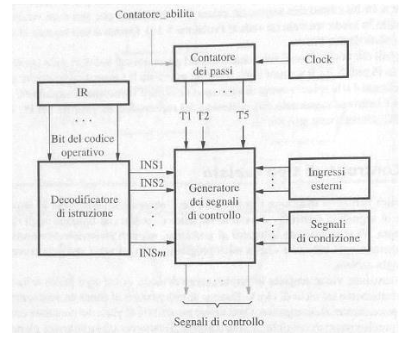
Durante l’accesso alla memoria che richiede svariati cicli di clock il contatore dei passi deve essere bloccato (per garantire la sincronizzazione) per bloccare il contatore dei passi viene generato un segnale WMFC (Wait for memory function completed) quando il fetch dalla memoria è finito viene generato un segnale MFC (memory function completed), quindi il segnale di abilitazione del contatore dei passi è questo:
- AbilitaContattore =
Tutto quello che abbiamo descritto fino ad adesso vale solo per i processori RISC infatti quest’ultimi sono gestibili in più stadi grazie alla lunghezza delle istruzioni che è ridotta.
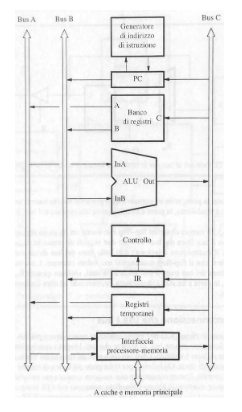
Interconnessione
All’interno di un processore tutti i componenti vengono messi in contatto attraverso il blocco di interconnessione, quest’ultimo è un insieme di bus, la porta logica che invia un segnale su una linea di bus è chiamata BUS DRIVER, i dispositivi sono collegati al bus tramite le porte tri-state, a differenza delle normali porte logiche che hanno solo due stati (0 e 1), le porte tri-state possono assumere un terzo stato: l’alta impedenza. In pratica, quando una porta è in questo stato, si comporta come se fosse scollegata dal circuito, non influenzando il segnale presente sul bus. Il bus verrà influenzato solo dalle porta non in alta impedenza.
Di solito tutte le componenti usate per l’esecuzione di una istruzione vengono collegate attraverso 3 BUS (Bus A,B usati per i dati in input e il Bus C per i dati in output), il generatore di indirizzi è collegato direttamente al PC.
 Esempio:
Passo 1:
Esempio:
Passo 1:
 Passo 2:
Passo 2:
 Passo 3:
Passo 3:

Controllo microprogrammato
I segnali di controllo di ogni passo vengono raccolti in una word di memoria chiamata microistruzione. L’insieme di microistruzioni rappresentanti i passi di un’istruzione macchina si chiamano microroutine. Le microistruzioni di ciascuna microroutine vengono immagazzinate in locazioni consecutive della memoria di controllo, il registro contiene l’istruzione della prossima microistruzione da caricare. All’inizio di un istruzione macchina il generatore di indirizzi delle microistruzioni carica sul μPC la prima istruzione della microroutine corrispondente ad ogni passo μPC viene incrementato di un passo per puntare alla microistruzione corretta.
Microprogrammato vs Microcablato
Controllo microcablato:
- Implementazione: I segnali di controllo sono generati attraverso un circuito logico cablato.
- Velocità: È generalmente più veloce poiché non dipende dall’accesso a una memoria di controllo.
- Flessibilità: È meno flessibile, perché le modifiche al set di istruzioni richiedono un aggiornamento fisico dell’hardware.
- Complessità: La complessità cresce rapidamente con il numero di istruzioni e segnali di controllo. Controllo microprogrammato:
- Implementazione: I segnali di controllo sono memorizzati in una memoria di controllo sotto forma di “microistruzioni” organizzate in “microroutine”.
- Velocità: Più lento rispetto al microcablato a causa dei tempi di accesso alla memoria di controllo.
- Flessibilità: Molto più flessibile, perché le modifiche al set di istruzioni possono essere apportate cambiando le microistruzioni nella memoria.
- Complessità: È più scalabile, particolarmente utile per architetture complesse.
É difficile determinare quale sia la migliore infatti questo dipende dall’applicazione:
- Il microcablato è preferibile in sistemi con requisiti di alte prestazioni e dove il set di istruzioni è stabile, come nelle applicazioni embedded o nei processori ad alta velocità.
- Il microprogrammato è ideale per processori generici o complessi (ad esempio, con molte istruzioni) dove è necessaria flessibilità, come nei primi sistemi CISC.
Ulteriori informazioni
Link Register: un registro essenziale per la gestione delle chiamate a sottoprogrammi. Quando un programma chiama una funzione o una procedura, l’indirizzo dell’istruzione successiva alla chiamata viene salvato nel link register. Una volta terminata l’esecuzione della sotto procedura, il valore contenuto nel link register viene caricato nel program counter (PC) per far riprendere l’esecuzione del programma principale dal punto esatto in cui era stato interrotto. Ad esempio, se un programma principale chiama una funzione per calcolare il fattoriale di un numero, il link register conterrà l’indirizzo dell’istruzione successiva alla chiamata. Al termine del calcolo del fattoriale, il programma tornerà a eseguire l’istruzione successiva alla chiamata iniziale.