01_Architettura
Questo file è la rielaborazione delle slide 01_Architettura.pdf Questo file è la rielaborazione delle slide 01_Architettura.pdf
Un’algoritmo è un insieme finito di istruzioni usate per la risoluzione di un certo lavoro. Quest’ultimo molte volte viene definito come una particolare funzione parziale di una macchina di Turing (Alan Turing, matematico britannico) oppure come un programma di una macchina di Von Neumann (matematico statunitense).
Le funzioni di base di un’elaboratore possono essere riassunte in 4 macro aree:
- memorizzazione dei dati
- elaborazione dei dati
- trasferimento dei dati
- controllo
Un’esempio di elaboratore è il computer, il computer è una macchina che computa ovvero che esegue un certo algoritmo (ovviamente scritto in modo che la macchina stessa lo possa interpretare). Esistono vari tipi di computer:
- Laptop
- Server
- Desktop
- Tablet/Smartphone
Un qualsiasi computer moderno segue l’architettura della macchina di Von Neumann
Macchina di Von Neumann
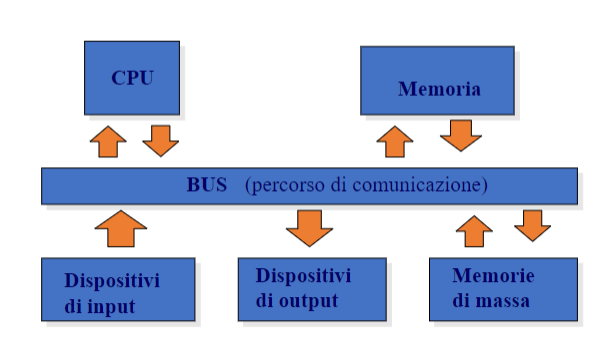 Questo tipo di architettura viene chiamata Macchina di Von Neuman (questa è l’architettura alla quale fa riferimento la definizione di algoritmo sopracitata). Di seguito una descrizione di tutti i componenti:
Questo tipo di architettura viene chiamata Macchina di Von Neuman (questa è l’architettura alla quale fa riferimento la definizione di algoritmo sopracitata). Di seguito una descrizione di tutti i componenti:
- La ==CPU, o Central Processing Unit==, è l’unità centrale di elaborazione di un computer. È il componente principale che esegue le istruzioni dei programmi, gestisce le operazioni logiche e aritmetiche, e coordina il funzionamento delle altre parti del sistema. Come memoria di lavoro usa i registri e la cache. La sua velocita si misura in numero di cicli al secondo (MHz o GHz). La CPU è formata da 4 parti fondamentali:
- il program counter: una locazione di memoria che contiene l’indirizzo dell’istruzione da eseguire
- il registro delle istruzioni: una locazione di memoria contenente l’istruzione da eseguire
- ALU (Arithmetic logic unit): un sistema che esegue le operazioni aritmetiche e logiche
- CU (Control Unit): Il sistema di controllo gestisce il flusso di esecuzione delle istruzioni. Fa sì che ogni parte del processore faccia il suo lavoro nel momento giusto, attraverso una serie di cambiamenti di stato.
- La ==memoria==, è un deposito di dati e di istruzioni da eseguire, ne esistono di 3 tipi:
- ROM, o Read Only Memory, è una memoria di sola lettura non volatile dove si trovano tutte varie informazioni come le istruzioni usate per l’avvio del pc, o dei parametri necessari per il corretto funzionamento del dispositivo
- RAM, o Random Access Memory, è una memoria volatile utilizzata per immagazzinare tutte quelle istruzioni che poi vengono eseguite dal processore
- La cache è una memoria ad alta velocità che si trova all’interno o vicino alla CPU e viene utilizzata per immagazzinare temporaneamente i dati e le istruzioni più frequentemente utilizzate. La sua funzione principale è quella di ridurre i tempi di accesso alla RAM migliorando così le prestazioni del sistema e quindi riducendo il Bottleneck tra CPU e RAM. Approfondimento qui
- ==Dispositivi di input==: come un tastiera ed un mouse
- ==Dispositivi di output==: come un monitor o una stampante
- ==Memoria di massa==: un tipo di memoria non volatile che viene usata per immagazzinare grandi file, e ovviamente molto più lenta di qualsiasi altro tipo di memoria sopracitata. La memoria di massa è fondamentale per garantire l’archiviazione stabile di software, documenti, immagini e altri dati digitali, rendendoli accessibili nel tempo. Degli esempi sono:
- Hard disk drive (HDD): basato su dischi magnetici rotanti.
- Solid State Drive (SSD): usa chip di memoria flash, più veloce e resistente rispetto agli HDD.
- ==BUS==, tutte queste componenti comunicano tra di loro attraverso i bus. I principali tipi di bus vengono usati per inviare dati o segnali di controllo. Approfondimento qui
La macchina di von Neumann viene definita logicamente come una terna, ovvero un’insieme di 3 elementi:
- N = {0,1,2,3} ovvero l’insieme dei numeri naturali (l’alfabeto della macchina)
- IS = {ZERO, INC, SOM, SOT, MOL, DIV, UGUALE, MINORE, SALCOND, ALT} è l’Instruction Set set ovvero un’insieme di istruzioni che la macchina può usare
- P = {I0, I1, I2, I3, … , I|P| – 1} è una sequenza finita di istruzioni prese dall’insieme IS, questo insieme si chiama programma Come possiamo ben notare un programma eseguibile dalla macchina von Neumann consiste in una lista di istruzioni che devono essere eseguite dal processore. Ogni istruzione viene sottoposta al ciclo macchina ovvero una serie di passaggi impiegati per l’esecuzione dell’istruzione stessa, di seguito i passaggi appena citati:
- ==Legge il contenuto del program counter==: ovvero l’indirizzo della prossima istruzione da eseguire.
- ==Caricamento nel registro delle istruzioni (fetch)==: Il processore va a recuperare l’istruzione dalla memoria, utilizzando l’indirizzo letto da program counter. Questa istruzione viene quindi inserita nel registro delle istruzioni.
- ==Decodifica dell’istruzione==: Una volta che l’istruzione è stata caricata, il processore la decodifica, per capire di che tipo di istruzione si tratta
- ==Invio all’ALU==: Se l’istruzione richiede un’operazione aritmetica o logica, la unità logico-aritmetica (ALU) riceve l’istruzione e i dati necessari per eseguire l’operazione.
- ==Accesso ai dati==: Se l’istruzione da eseguire richiede dei dati la control unit li recupera dalla memoria. Se l’istruzione è del tipo SOM(M1, M2) ad esempio, significa che M1 e M2 sono indirizzi in memoria da cui vengono presi i dati.
- ==Esecuzione==: L’ALU effettua l’operazione richiesta (ad esempio, somma o confronto) utilizzando i dati forniti.
- ==Memorizzazione del risultato==: Una volta ottenuto il risultato, viene registrato nella locazione di memoria specificata dall’istruzione.
- ==Aggiornamento del contatore==: Il program counter viene incrementato per puntare all’istruzione successiva.
- ==Ripetizione del ciclo==: Questo ciclo continua fino a quando non viene incontrata un’istruzione speciale che ferma o altera l’esecuzione, come un’istruzione ALT o un salto condizionato che modifica il flusso del programma.
Un altro modello di elaboratore dalla quale Von Neumann prese spunto fu la macchina di Turing
Macchina di Turing
Una macchina di Turing (o MdT) è stata inventata da Alan Turing nel 1936. Questo modello è fondamentale nella teoria della computabilità e fornisce una rappresentazione astratta di come funzionano i calcolatori. Formalmente viene definita in questo modo:
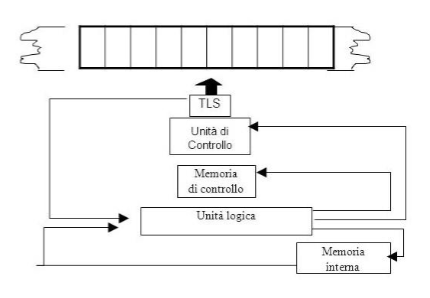 Di seguito una descrizione di tutti i componenti:
Di seguito una descrizione di tutti i componenti:
- ==Nastro==: Un’unità di memoria esterna infinita, suddivisa in celle, ogni cella contiene un simbolo oppure è vuota.
- ==Testina di lettura/scrittura (TLS)== : Un dispositivo che interagisce direttamente con il nastro.
- ==Unità di memoria interna==: Una struttura che memorizza lo stato interno della macchina.
- ==Unità di calcolo==: Un componente che esegue le operazioni di base.
- ==Unità di controllo==: Il “cervello” della macchina, che coordina le altre unità.
- ==Unità di logica==: Un componente che si occupa delle operazioni logiche. Il comportamento di una MdT può essere programmata definendo un’insieme di regole, o quintuple di questo tipo:
- (stato-interno-corrente, simbolo-letto, prossimo-stato-interno, simbolo-scritto, direzione) di seguito degli esempi:
- (0, A, 1, B, -) se la macchina si trova nello stato 0 e legge il simbolo A passa allo stato 1 e scrive sul nastro B e sta ferma
- (1, B, 0, A, >) se si trova nello stato 1 e legge il simbolo B passa allo stato 0 e scrive sul nastro A e si muove di una posizione a destra
È importante sottolineare come l’attenzione di Turing sia rivolta al processo di calcolo, indipendentemente da come esso avviene fisicamente. Una M.d.T è un dispositivo ideale, cioè indipendente da ogni sua possibile realizzazione fisica. Una funzione si dice Tuing-computabile se almeno una MdT è in grado di computarla con un numero finito di passi.
Condizioni di finitezza
Una MdT per essere tale deve rispettare le condizioni di finitezza che sono:
- il numero di simboli che usa deve essere fissato e finito
- il numero di caselle del nastro osservabili in una volta è finito
- è possibile ricordare solo un numero finito di stadi precedenti
- le operazioni che può compiere sono:
- Cambiare il contenuto di alcune caselle osservate
- Cambiare le caselle osservate
- Cambiare il proprio stato
- Osservare nuove caselle che si trovano ad una distanza prefissata dalla casella osservata
Macchina di Turing universale
Se supponiamo di avere una macchina di Turing senza limiti di spazio, di tempo e che non possa commettere errori quest’ultima sarà in grado di calcolare tutte le funzioni calcolabili in ogni singola macchina di Turing, questa macchina la chiamiamo Macchina di Turing Universale (MdTU), inoltre deve rispettare sia la condizione di finitezza sopracitata ma anche la condizione di determinatezza spiegata di seguito
Condizione di determinatezza
le azioni di una MdTU devono dipendere solo dai simboli contenuti nella casella osservata in quell’instante e dallo “Stato mentale” corrente, cioè da quello che ricorda dei calcoli precedenti
Da tutto questo Turing formula la seguente Tesi: “ogni funzione parziale calcolabile con un algoritmo è una funzione parziale calcolabile da una macchina di Turing.” (appunto per questo all’inizio si parla dell’algoritmo come una funzione parziale della macchina di Turing). Questa tesi ci dice che ogni Funzione parziale calcolabile da un algoritmo può essere calcolata da una macchina di Turing, poiché ogni algoritmo può essere descritto in termini di un insieme finito di regole.
Bottleneck
La CPU è progettata per operare a velocità estremamente elevate, elaborando milioni di istruzioni al secondo. Tuttavia, la RAM, sebbene veloce, ha tempi di accesso più lunghi quando la CPU richiede dati o istruzioni deve attendere che questi vengano recuperati dalla RAM. Questo processo di attesa genera un rallentamento, poiché la CPU rimane inattiva in attesa dei dati necessari per continuare l’elaborazione. Per mitigare questo problema, le CPU fanno uso della cache, una memoria più veloce e più vicina al processore, dove vengono conservati i dati e le istruzioni più frequentemente utilizzati. Tuttavia, anche con l’uso della cache, il bottleneck rimane una preoccupazione, specialmente in scenari di carico elevato o quando vengono eseguiti più processi contemporaneamente. In questi casi, se la RAM non è in grado di tenere il passo con le richieste della CPU, si crea un rallentamento significativo, influenzando negativamente l’efficienza complessiva del sistema.
Il test di Turing
Turing cercò di rispondere alla domanda “can machines think?”, per fare ciò formulo quello che viene chiamato test di Turing ovvero un giudice umano comunica con due interlocutori nascosti: uno è un essere umano, e l’altro è una macchina. Se il giudice non riesce a distinguere chi è la macchina e chi è l’umano basandosi solo sulle risposte fornite, allora si dice che la macchina ha superato il test e può essere considerata “intelligente”. Fino a qualche mese fa nessuno era riuscito a superarlo tranne ChatGPT-4 di recente
Funzione parziale
Una funzione parziale è una funzione che non è necessariamente definita per ogni possibile input. Questo significa che per alcuni input, la funzione potrebbe non restituire alcun output. Quest’ultime vengono utilizzate nella definizione di una macchina di Turing universale perché riflettono la realtà infatti non tutte le computazioni terminano con successo. Questo rende il modello più realistico e potente perché è in grado di rappresentare qualsiasi tipo di computazione, sia quelle che vanno bene che quelle che vanno male
Processi sincroni/asincroni
- Processi sincroni: sono processi che hanno bisogno di essere “sincronizzati” perché sono propedeutici tra di loro.
- Processi asincroni: sono processi che non hanno bisogno di essere sincronizzati perché “lavorano da soli”. La maggior parte dei processi asincroni vengono eseguiti dalle GPU quest’ultime hanno moltissimi core rispetto alle CPU proprio perché devono svolgere solo processi asincroni e quindi parallelizzabili, un’esempio dove questa proprietà è fondamentale è nella renderizzazione dello schermo, quest’ultimo è formato da matrici (la risoluzione ci indica quanto sono grandi Es: 720x480) dalla quale è possibile creare delle sottomatrici che vengono lavorate da processi indipendenti (e quindi asincroni), tutte queste sottomatrici vengono riunite nella matrice finale che sarà l’immagine che visualizzeremo a schermo (lo schermo a colori è formato da 3 matrici Red, Green, Blue che definiscono lo standard RGB).
02_Memoria
Questo file è la rielaborazione delle slide 02_Memoria.pdf
La memoria dentro i nostri elaboratori ha una struttura piramidale, più si va in alto in questa piramide più la memoria diventa veloce ma si riduce di dimensione:
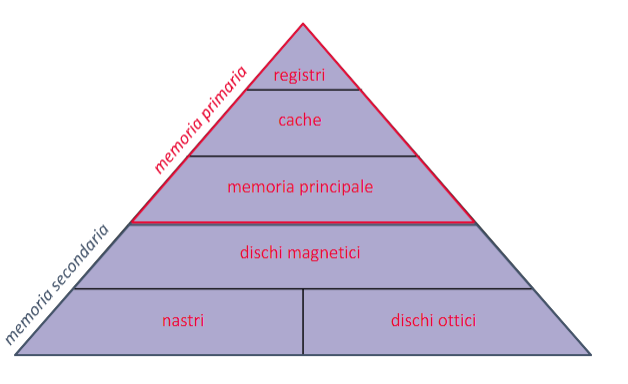
La memoria principale di un computer è costituita da un insieme di celle ordinate, ciascuna con una capacità di un byte e dotata di un indirizzo univoco. All’interno di queste celle vengono memorizzati sia le istruzioni dei software che i dati di input e output. Tuttavia, i contenuti delle celle vengono mantenuti solo finché la memoria è alimentata elettricamente, motivo per cui questa memoria viene definita volatile.
La maggior parte della memoria principale è realizzata con tecnologia RAM (Random Access Memory), e in particolare con una sua variante chiamata DRAM (Dynamic RAM). La DRAM è così denominata perché i dati in essa contenuti devono essere continuamente aggiornati. I tempi di lettura e scrittura della RAM, tuttavia, sono più lenti rispetto alle altre operazioni svolte da un elaboratore, creando quello che viene definito un collo di bottiglia (bottleneck).
Per mitigare questo problema, sono state sviluppate le SRAM (Static RAM), un tipo di RAM più veloce e stabile, ma anche più costoso. Per questo motivo, la SRAM viene utilizzata principalmente come memoria di transito tra la memoria principale e il processore, con il nome di cache.
Le memorie DRAM sono installate sulla scheda madre all’interno di slot chiamati DIMM (Dual Inline Memory Module), caratterizzati dalla presenza di circuiti su entrambe le facce del modulo.
Oltre alla RAM, la memoria principale include anche la ROM (Read Only Memory), una memoria di sola lettura utilizzata per conservare il BIOS (Basic Input/Output System). Il BIOS è fondamentale nella fase di avvio del computer, nota come bootstrap, durante la quale il dispositivo viene inizializzato correttamente. Successivamente, il BIOS esegue la fase di POST (Power On Self Test), che verifica il corretto funzionamento delle componenti hardware del sistema.
Anche se la ROM è progettata per essere di sola lettura, può essere riprogrammata in determinate circostanze, come durante le procedure di configurazione o aggiornamento del BIOS.
03_Bus
Questo file è la rielaborazione delle slide 03_Bus.pdf
Il bus è l’unità di interconnessione che permette la comunicazione tra i vari componenti della macchina di Von Neumann. Si presenta come un fascio ordinato di linee, ciascuna delle quali può rappresentare un bit. Il bus funziona quindi come un mezzo di trasporto per le informazioni tra la CPU (definita Master), la memoria e i dispositivi di I/O (detti Slave).
Tipologie di collegamenti
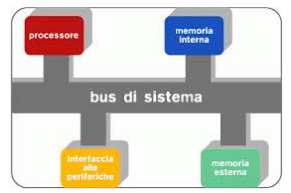 Dalla figura possiamo individuare diversi tipi di collegamenti che si instaurano nel sistema:
Dalla figura possiamo individuare diversi tipi di collegamenti che si instaurano nel sistema:
- Dal processore alla memoria
- Dalla memoria al processore
- Dal processore ai dispositivi di I/O
- Dai dispositivi di I/O al processore Quando il processore agisce come Master:
- Un’operazione che trasferisce un dato dal processore alla memoria si chiama Write.
- Un’operazione che trasferisce un dato dalla memoria al processore si chiama Read. Il tempo che intercorre tra il segnale di invio dell’operazione e la sua effettiva esecuzione è chiamato latenza.
Suddivisione del bus
Per gestire correttamente il trasferimento dei dati, il bus è suddiviso in tre diverse tipologie di linee:
- Address Bus (ABus): trasporta le informazioni sugli indirizzi da utilizzare per il trasferimento.
- Data Bus (DBus): viene utilizzato per trasferire i dati.
- Control Bus (CBus): comprende linee dedicate a controllare il tipo e la direzione del trasferimento.
Linee del Control Bus
Le linee del Control Bus hanno compiti specifici:
- I/O-Mem: indica la direzione del trasferimento:
- Dal processore alle periferiche I/O: valore impostato a 1.
- Dal processore alla memoria: valore impostato a 0.
- R/W: specifica il tipo di trasferimento:
- Read: valore impostato a 1.
- Write: valore impostato a 0.
- WAIT: segnala lo stato del trasferimento:
- Trasferimento completato: valore impostato a 1.
- Trasferimento in corso: valore impostato a 0.
Sincronizzazione e velocità
La velocità del bus è regolata da un “orologio” interno, chiamato clock, che scandisce il tempo in modo costante, sincronizzando tutte le operazioni sul bus. Le dimensioni dei bus variano e influiscono sulle prestazioni del sistema, contribuendo al collo di bottiglia (bottleneck):
- Address Bus (ABus): determina la quantità di memoria indirizzabile dai programmi. La memoria raggiungibile si calcola elevando 2 al numero di linee dell’ABus (es. un ABus a 32 bit permette di indirizzare 2³² byte di memoria).
- Data Bus (DBus): rappresenta il grado di parallelismo del processore, ovvero la quantità di dati che può elaborare simultaneamente. Nota Bene: ogni singolo bus trasporta un solo bit, ma la combinazione di più linee consente il trasferimento parallelo di più bit.
Chipset e bus principali
Sulla scheda madre i bus di sistema sono difficili da identificare visivamente; il loro funzionamento è gestito da linee fisiche e chip dedicati, noti con il nome di Chipset. Tra i vari tipi di bus, il più importante è il PCI (Peripheral Component Interconnect), ormai largamente utilizzato. La sua variante più recente, PCI Express, è progettata per gestire elevate velocità di trasferimento ed è particolarmente diffusa per l’uso con schede video.
04_InputOutput
Questo file è la rielaborazione delle slide 04_InputOutput.pdf
I dispositivi di input/output sono essenziali per acquisire dati dall’utente e per rappresentarli. Ogni dispositivo è associato a un proprio intervallo di indirizzi e utilizza linee di sincronizzazione, chiamate interrupt, per comunicare con il processore. Esistono due principali tipi di interrupt:
- INTR: segnala una richiesta di interruzione al processore.
- INTA: conferma l’avvenuta gestione dell’interruzione.
Quando il dispositivo invia un segnale INTR, richiede al processore di sospendere temporaneamente la sua esecuzione per gestire l’interrupt, eseguendo una specifica procedura chiamata Interrupt Service Routine (ISR). Esistono anche modalità che permettono agli interrupt di bypassare la CPU e accedere direttamente alla memoria, tramite una procedura chiamata Direct Memory Access (DMA). La circuiteria dedicata a collegare il dispositivo al bus e a sincronizzarlo con le altre periferiche è detta controller della periferica. Un tempo, questi dispositivi erano fisicamente visibili all’esterno del computer, mentre oggi si trovano integrati nei circuiti interni. In passato, indirizzi, canali e linee dovevano essere configurati manualmente dall’utente o da un tecnico. Tuttavia, grazie alla tecnologia Plug&Play il BIOS, il sistema operativo e il firmware cooperano per gestire automaticamente la configurazione delle periferiche, sia all’avvio del computer che durante l’installazione di nuovi dispositivi.
Tra gli standard di connessione più diffusi, troviamo: USB (Universal Serial Bus), FireWire (o IEEE 1394), e Ethernet (802.x).
05_Processore
Questo file è la rielaborazione delle slide 05_Processore.pdf, approfondimento con codice assembly qui: 08_Struttura-base-del-processore
Un processore è un singolo circuito integrato in grado di effettuare operazioni decisionali, di solito viene indicato con la sigla CPU (Central Processing Unit), il processore viene concettualmente diviso in 3 unità funzionali:
- UC (Control Unit): si affaccia sul bus e lo arbitra impostando i valori nelle linee ABus, DBus e CBus
- Registri: sono delle memorie di lavoro dove vengono conservati i dati presi dall’UC sul bus per poi poterli far usare dalla ALU durante l’esecuzione
- ALU (Arithmetic logic unit): è l’unita di esecuzione effettiva del processore
Ogni processore viene progettato con un set di istruzioni specifico denominato ISA (Instruction Set Architecture) o IS (Instruction Set), ogni istruzione dell’ISA è contraddistinta da un numero specifico denominato Operation Code(OP) ad ogni OP si associa una breve descrizione in lingua naturale che ne ricorda la funzione.
L’ALU, i registri e molti bus costituiscono il data path, che si presenta in questo modo:
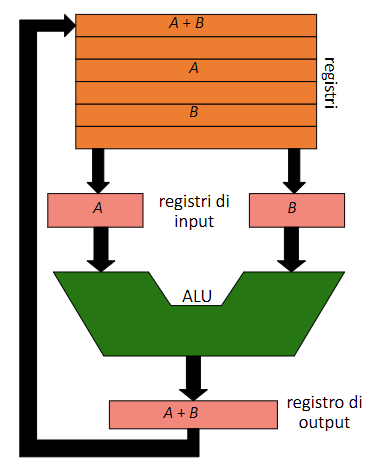 Le istruzioni che devono essere usate dalla ALU, vengono caricate nei registri di input (che solitamente sono 2), la ALU fornisce il suo risultato nel registro di output (che solitamente è 1), infine il risultato verrà memorizzato nei registri, quello appena descritto è il ciclo del data path, ovvero la sequenza di passaggi che il computer esegue per eseguire un’operazione tramite la ALU (corrisponde alla fase di execute del ciclo macchina)
Le istruzioni che devono essere usate dalla ALU, vengono caricate nei registri di input (che solitamente sono 2), la ALU fornisce il suo risultato nel registro di output (che solitamente è 1), infine il risultato verrà memorizzato nei registri, quello appena descritto è il ciclo del data path, ovvero la sequenza di passaggi che il computer esegue per eseguire un’operazione tramite la ALU (corrisponde alla fase di execute del ciclo macchina)
In base al tipo di Instruction set vengono definiti vari tipi di processore
- CISC (Complex Instruction Set Computer): basati su molte istruzioni complicate
- RISC (Reduced Instruction Set Computer): basati su poche e semplici istruzioni
- CRISC (Complex Reduced Instruction Set Code): quello più usato attualmente, è un architettura ibrida tra CISC e RISC
Nota
Il Program Counter (PC) è un registro della CPU che contiene l’indirizzo della prossima istruzione da eseguire.
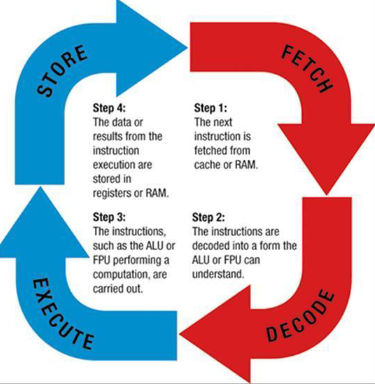
Un tipico processore opera seguendo una sequenza rigida di passi, che si ripetono fino all’arresto della macchina. Questi passi sono i seguenti:
- Fetch: L’Unità di Controllo (UC) carica nel bus degli indirizzi (ABus) il valore del Program Counter, attivando la lettura dalla memoria e caricando l’OpCode dell’istruzione corrente.
- Decode: L’UC, interpretando l’OpCode appena letto, determina la lunghezza dell’istruzione e quanti parametri sono necessari. Inizia quindi una fase intermedia, chiamata Operand Fetch, per caricare gli operandi, che si trovano in indirizzi consecutivi a quello dell’OpCode. Gli operandi vengono quindi memorizzati nei registri.
- Execute: L’UC avvia il microprogramma corrispondente all’OpCode, utilizzando i parametri precedentemente caricati nei registri. La frequenza con cui vengono eseguiti questi microprogrammi è regolata dal clock della CPU, cioè la frequenza del microprocessore.
- Store: Al termine dell’operazione di Execute, i risultati, ora memorizzati nei registri, vengono trasferiti sul bus dall’UC. Questi possono essere scritti in memoria o inviati a dispositivi di input/output (PIO).
Questa sequenza continua a ripetersi per ogni istruzione fino al completamento o arresto del programma.
 Questo ciclo può interrompersi se arriva alla CPU un segnale di INTR (della quale abbiamo parlato qui 04_InputOutput)
Questo ciclo può interrompersi se arriva alla CPU un segnale di INTR (della quale abbiamo parlato qui 04_InputOutput)
Ogni singola istruzione dell’IS di un processore è contraddistinta da un proprio Op. Code, una determinata lunghezza e un preciso numero di cicli di bus per il suo completamento, il tempo effettivo di esecuzione dell’istruzione è poco influente sulla durata totale di un’istruzione, infatti il bus è un’ordine di grandezza più lento rispetto alla CPU (questo va a creare il già discusso collo di bottiglia)
CISC vs RISC
CISC Le CPU CISC dispongono di un set di istruzioni ampio e complesso, progettato per eseguire operazioni di alto livello con un numero ridotto di istruzioni. Questo comporta però che ogni istruzione sia relativamente più lunga da eseguire, poiché richiede più cicli di clock e implica molteplici passaggi nel data path della CPU.
RISC Le CPU RISC sono progettate con un set di istruzioni più semplice e costante, con comandi che richiedono un solo ciclo di clock per essere eseguiti. Questo approccio rende il data path della CPU molto più lineare e veloce, facilitando una rapida esecuzione delle istruzioni.
| Caratteristica | CISC | RISC |
|---|---|---|
| Pro | - Flessibilità: istruzioni complesse eseguono operazioni elaborate con poche istruzioni. - Compatibilità: architettura comune (es. x86), ampio supporto software. - Efficienza di memoria: istruzioni più complesse possono ridurre il numero complessivo di istruzioni necessarie. | - Alta velocità: istruzioni semplici eseguite in un singolo ciclo di clock, maggiore rapidità. - Efficienza energetica: consumo energetico ridotto per via della semplicità delle istruzioni. - Facilità di ottimizzazione: progettazione più semplice per prestazioni ottimali. |
| Contro | - Bassa efficienza: esecuzione più lenta per il numero elevato di cicli di clock necessari per ogni istruzione. - Maggiore consumo energetico: istruzioni complesse richiedono più energia. - Difficoltà di ottimizzazione: architettura complessa, meno ottimizzabile per velocità e prestazioni. | - Maggiore carico di programmazione: servono più istruzioni per compiti complessi. - Maggiore consumo di memoria: necessità di più istruzioni, che occupano più spazio. - Minor compatibilità software: adattamenti necessari per software sviluppato su CISC. |
| I processori moderni sono ibridi, ovvero usano un tipo di architettura chiamata CRISC (Complex Reduced Instruction Set Computer) cercando di ottenere i vantaggi di uno e dell’altro. |
Come abbiamo capito il problema principale che causa un rallentamento della CPU è l’accesso alle risorse dal bus, per diminuire questi accessi e quindi aumentare il throughput si fa uso delle cache, una memoria “tampone” sulla quale vengono caricate le istruzioni più utilizzate dal processore, ad ogni operazione di lettura che fa il processore, controlla se l’informazione che gli serve è già nella cache in modo da poterci accedere in maniere più veloce, se non c’è il processore la richiede tramite il bus e sovrascrive l’istruzione meno usata che si trova nella cache con quella che ha appena richiesto. Esistono 3 tipi di cache:
- L-1: che si trova all’interno del processore
- L-2: che è collegata al processore
- L-3: sulla motherboard Si può dire che la cache sia genericamente più veloce del bus, ma più si alza il livello di cache più questa differenza diminuisce.
Prefetch
Per aumentare il parallelismo di esecuzione viene usata la tecnica del prefetching che dice alla CPU che anziché limitarsi a caricare dalla memoria l’istruzione o il dato richiesto al momento, recuperi in anticipo anche le istruzioni o i dati immediatamente successivi. A questo scopo, i processori dispongono di una “coda di prefetch”, un buffer interno che può contenere una certa quantità di dati consecutivi (ad esempio, i 6 o 8 byte successivi a quello appena caricato). In questo modo, il processore effettua un singolo accesso alla memoria per caricare una serie di valori che possono essere utilizzati subito dopo, sia come istruzioni che come operandi.
Esistono 4 tipi di prefetch
- Prefetching hardware: le CPU hanno un componente hardware al loro interno che rileva automaticamente i data pattern (dati che servono molte volte e seguono quindi una sorta di pattern nel loro utilizzo) nella memoria e li carica preventivamente nella cache.
- Prefetching software: nel prefetching software si usano delle variabili per suggerire alla CPU che certi dati saranno utilizzati molto spesso, quindi cosi la CPU li caricherà nella cache senza passare ogni volta dal BUS.
- Tecnica di ottimizzazione in fase di compilazione : è un metodo che in fase di compilazione identifica le linee di codice e i dati che vanno utilizzati di più. Questo è un modo per ottimizzare il codice. Funziona con compilatori moderni (C,C++ ecc…)
- Prefetching con accesso alla linee di cache: utilizza le linee di cache per l’accesso alla memoria, quindi trasporta dei blocchi fissi, da 64 byte solitamente, direttamente alla cache.
L’elaborazione di un’istruzione
L’elaborazione di un’istruzione da parte di un processore con pipeline si articola in cinque fasi principali:
- IF (Instruction Fetch): Recupero dell’istruzione dalla memoria.
- ID (Instruction Decode): Decodifica dell’istruzione e lettura degli operandi dai registri.
- EX (Execution): Esecuzione dell’istruzione.
- MEM (Memory Access): Interazione con la memoria (valida solo per alcune istruzioni).
- WB (Write Back): Scrittura del risultato nel registro.
Queste fasi, sequenziali e talvolta sovrapposte, permettono al processore di eseguire le operazioni previste dalle istruzioni.
Pipeline
Alla coda di prefetch, è stato affiancato un sistema detto pipeline che ha lo scopo di sfruttare il concetto di catena di montaggio e quindi di parallelizzare più istruzioni possibili invece di eseguire un’istruzione completamente prima di eseguire la sua successiva. Basta che la prima istruzione sia in fase di decode che la seconda possa essere portata in fase di fetch.
-
Senza pipeline

-
Con pipeline
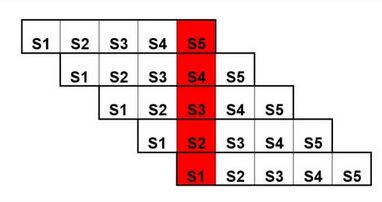
Come possiamo ben notare una pipeline a 5 stadi esegue 5 fasi contemporaneamente, questa tecnica sopperisce al problema dell’accesso alla memoria precedentemente discusso. L’uso della pipeline introduce anche delle problematiche:
- Data hazards: si verifica quando un istruzione richiede dei dati che vengono forniti da un altra istruzione che non ha ancora finito (ritardi di elaborazione o blocchi)
- Control hazards: si verifica quando la pipeline deve gestire dei salti condizionali (tipo il go-to)
- Structural hazards: si verifica quando più istruzioni cercano di accedere alla stessa risorsa (problemi dei filosofi a cena)
Dopo aver dotato i primi processori di pipeline si ci è resi conto che la fase più lenta diventava la fase di execute (quella implementata nella ALU) per sopperire a questo problema si montano più ALU dentro ad un singolo processore. Un processore con più ALU è detto Superscalare
I problemi del prefetching e della pipeline
Tutte queste tecniche vengono vanificate da 2 situazioni:
- Istruzioni di salto: la pipeline viene del tutto persa se il salto ci porta ad un’istruzione lontana da quella che si trova attualmente in pipeline
- Dipendenza dei dati tra le istruzioni: la pipeline viene interrotta
Per cercare di arginare il problema delle istruzioni di salto sono stati introdotti nel processore dei moduli chiamati Dynamic Branch Prediction che si occupano di implementare l’esecuzione predicativa, una tecnica che fa uso di tabelle simili a memorie cache, per cercare di capire se un’istruzione di salto avverrà o meno (questa tecnica non è deterministica infatti si basa solo su una statistica storica), il problema principale di questa tecnica si ha quando la previsione fatta è sbagliata, infatti in quel caso la pipeline va ripristinata. L’esecuzione predicativa è anche nota come esecuzione speculativa quando va a fare una predizione sul codice che potrebbe non essere mai utilizzato.
Per cercare di arginare il problema delle dipendenze da dato si usa una tecnica chiamata out of order execution ovvero una tecnica che permette l’esecuzione delle istruzioni non necessariamente nell’ordine in cui sono state emesse, ma eseguendo le istruzioni prive di dipendenze mentre si attende il completamento di quelle con dipendenze, in questo modo la pipeline viene quasi del tutto conservata e non è necessario eseguire un flush con conseguente perdita di prestazioni. Ci sono però delle condizioni critiche:
- Le istruzioni “future” possono essere eseguite solo se non sono dipendenti a loro volta
- Quando il processore si trova fuori ordine e arriva un interrupt, il processore deve ripristinare il suo stato e riordinare anche il giusto flusso di esecuzione
Per poter riordinare il giusto flusso di esecuzione i processori utilizzano una serie di registri d’appoggio (interni e invisibili al programmatore) su cui memorizzare i calcoli temporanei delle istruzioni fuori ordine. All’atto del riordinamento, per evitare di spostare i valori dai registri interni a quelli effettivamente usati nel data path, i processori sono in grado di rinominare i registri interni nei nomi dei registri effettivi, risparmiando il tempo del trasferimento questa tecnica si chiama register renaming.
Esistono 3 tipi di dipendenza del dato:
-
RAW (Read After Write): Si verifica quando un’istruzione legge un dato che è stato scritto da una precedente istruzione. È chiamata anche dipendenza vera o data dependency, perché un dato deve essere prodotto prima di essere letto.
- Esempio:
Istruzione 1: A = 5,Istruzione 2: B = A + 1. L’istruzione 2 dipende dal valore diAprodotto dalla prima.
- Esempio:
-
WAW (Write After Write): Si verifica quando due istruzioni scrivono nello stesso dato. La seconda scrittura deve avvenire dopo la prima per non sovrascrivere accidentalmente il valore prodotto dalla prima. Questa è una dipendenza anti o di output.
- Esempio:
Istruzione 1: A = 5,Istruzione 2: A = 10. Qui la seconda scrittura sovrascrive il valore diAdella prima istruzione.
- Esempio:
-
WAR (Write After Read): Si verifica quando una istruzione scrive su un dato che viene letto da una precedente istruzione. Questa dipendenza è detta anti-dipendenza, perché la scrittura deve avvenire solo dopo la lettura per evitare che il valore letto sia alterato.
- Esempio:
Istruzione 1: B = A + 1,Istruzione 2: A = 3. La seconda istruzione deve aspettare che la prima leggaAprima di scrivere su di esso.
- Esempio:
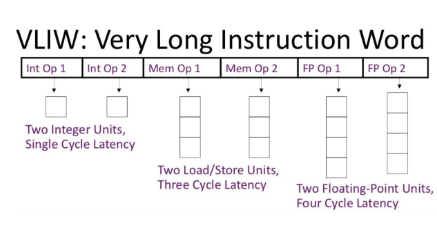
Very long Istruction Word
Anche se non esplicitamente, tutte queste innovazioni (pipeline, super-scalarità, predicazione, esecuzione fuori ordine) cercano di implementare un modello di esecuzione parallelo molto studiato nei centri di calcolo, e denominato VLIW (Very Long Instruction Word). In questo modello, oltre alla parallelizzazione dell’esecuzione ottenuta in hardware, si presuppone che lo stesso codice esecutivo generato dai compilatori sia «pre-cucinato» per essere parallelizzato ottimamente dalle CPU.
06_livello_software
Questo file è la rielaborazione delle slide 06_Livello-software.pdf
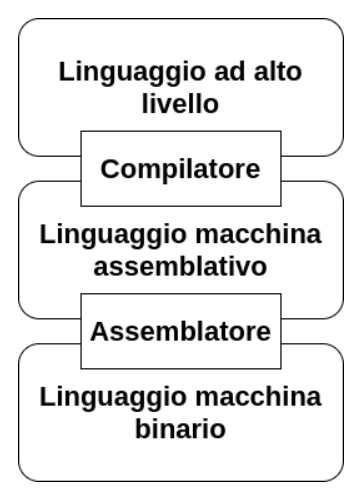
Il processo di programmazione consiste nel seguente paradigma:
- Il programmatore scrive il programma in linguaggio ad alto livello
- Il compilatore traduce il linguaggio ad alto in linguaggio macchina assemblativo
- trasforma una serie di file sorgenti di linguaggio ad alto livello in file sorgenti assembly
- L’assemblatore traduce il programma in linguaggio assemblativo in sequenze binarie
- trasforma una serie di file sorgenti assembly in file oggetto
- Il linker collega assieme vari file oggetto e file di libreria in un unico programma oggetto
Per generare il file oggetto l’assemblatore esegue i seguenti passi:
- Genera la codifica delle istruzioni espresse in assembly
- Riconosce le direttive di assemblatore per l’allocazione di memoria mettendo queste informazioni nell’header del file oggetto
- Riconosce le direttive che assegnano nomi a costanti
- Sostituisce il valore binario ad ogni occorrenza di etichette di indirizzi relativi nel codice
Nel caso in cui l’assemblatore fosse del tipo “a due passi”, man mano che incontra le etichette e dichiarazione di constanti, tiene traccia dei nomi dentro una tabella dei simboli, per poi sostituire ogni occorrenza di un nome con il valore indicato nella tabella. Questo tipo di assemblatore viene detto a 2 passate perché fa tutto ciò in 2 passi distinti:
- Passo 1: scorre il codice e raccoglie tutti i simboli
- Passo 2: scorre di nuovo il codice sostituendo i simboli con i valori in tabella
Loader
File sorgente, file oggetto e dati sono memorizzati nella memoria secondaria, per essere caricati in memoria facciamo uso del loader, per fare ciò esegue i seguenti step:
- Leggere le informazioni quali la lunghezza del programma e la locazione dell’header del file oggetto.
- Caricare il programma in memoria sulla base di tali informazioni
- Saltare alla prima istruzione del programma da eseguire
Linker
Nella maggior parte dei casi un programma è distribuito in più file sorgente, in questi casi l’assemblatore genera un file oggetto incompleto, il file oggetto completo lo genera il linker che si occupa di combinare più file oggetto separati risolvendo i riferimenti a nomi esterni, inoltre crea il file eseguibile e lo salva sul disco.
Librerie
i file sorgente esterni di cui parlavamo nel linker, molte volte fanno parte di librerie di file, ovvero degli archivi di file oggetto utilizzabili in programmi esterni, i riferimenti vengono risolti sempre dal linker che andrà a risolvere i vari riferimenti nel programma oggetto finale.
Compilatore
Questo programma si occupa di trasformare un file sorgente scritto in linguaggio ad alto livello in un file scritto in assembly, un compilatore che riorganizza le istruzioni per ottimizzare il codice viene detto ottimizzante. Un programma ad alto livello può chiamare sottoprogrammi presenti in altri file assembly o scritti in altri linguaggi (il linker gestirà i collegamenti). Il compilatore è in grado di rilevare errori sintattici e nomi sconosciuti nel codice sorgente, ma non errori di programmazione (bug)
Debugger
il debugger è un programma che ci permette di eseguire il programma oggetto ed interrompere la sua esecuzione in qualsiasi instante, in modo da poterne valutare il suo funzionamento. Esistono 2 tipi di debugger:
- Trace mode: il programma viene eseguito passo-passo, interrompendosi dopo ogni istruzione
- Si genera un’eccezione al termine dell’esecuzione di ogni istruzione del programma, il debugger viene lanciato come routine di servizio dell’istruzione cosicché il programmatore posso controllare il corretto funzionamento di quell’istruzione, una volta che il programmatore seleziona il comando per continuare l’esecuzione viene effettuato un rientro dall’interruzione e viene eseguita l’istruzione successiva
- breakpoint: l’esecuzione del programma si interrompe in punti di osservazione specifici
- Quando il Debugger è in esecuzione, il programmatore può scegliere dei punti di osservazione (breakpoint) dove interrompere il programma. il debugger sostituisce e mette da parte le istruzioni in corrispondenza dei breakpoint con speciali interruzioni software (Trap), il programma viene eseguito normalmente fino ad arrivare alla prima Trap, dove l’esecuzione passa al Debugger, una volta che il programmatore seleziona il comando per continuare l’esecuzione il Debugger riprende l’esecuzione del programma
Sistema operativo
Il sistema operativo gestisce il coordinamento generale di tutte le attività del calcolatore. Il SO è formato da un insieme di routine essenziali che risiedono nella memoria centrale e un insieme di programmi di utilità che risiedono su disco e vengono caricati in memoria centrale per essere eseguiti. Durante l’inizializzazione del sistema, un processo di avvio (boot-strapping) viene usato per caricare in memoria una porzione iniziale del SO. Sistemi operativi capaci di eseguire più istruzioni contemporaneamente sono chiamati concorrenti o multitasking, per fare ciò il sistema operativo divide il tempo di esecuzione di un programma in slice di tempo, sarà lo scheduler a scegliere quale slice eseguire. I programmi possono trovarsi in 3 stati: running, runnable e blocked
07_Pipelining
Questo file è la rielaborazione delle slide 07_Pipelining.pdf
Per svolgere compiti sempre più complessi in tempi ridotti è stata introdotta nei processori la tecnologia del pipelining (idea presa dalle catene di montaggio delle fabbriche) l’obbiettivo di questa tecnica è quello di parallelizzare quante più istruzioni possibili, ricordando la suddivisione delle istruzioni in 5 fasi diverse (Prelievo – Decodifica – Elaborazione – Memoria - Scrittura) nel caso migliore avremo 5 istruzioni eseguite in parallelo. Per gestire l’esecuzione in pipeline di più istruzioni abbiamo bisogno di mantenere le istruzioni tra uno stadio e l’altro, queste istruzioni vengono conservate dai buffer interstadio. Di seguito una pipeline perfetta dove ad un certo punto vengono eseguite 5 istruzioni contemporaneamente.
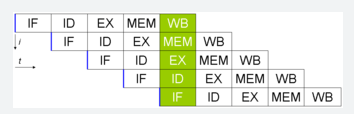 Non è sempre possibile avere la situazione ideale infatti possono avvenire delle problematiche di seguito discusse che rallentano l’esecuzione della pipeline.
Non è sempre possibile avere la situazione ideale infatti possono avvenire delle problematiche di seguito discusse che rallentano l’esecuzione della pipeline.
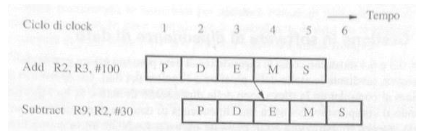
Data Hazard
Questo tipo di conflitto avviene quando un’istruzione richiede un dato da un registro e quel dato non è stato ancora aggiornato dalle istruzioni precedenti.
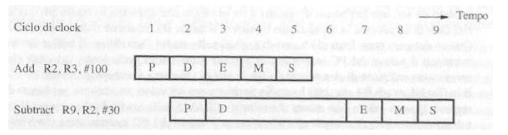 Date le due istruzioni in foto capiamo che l’istruzione Substract dovrà aspettare che l’istruzione Add abbia finito, questo allunga inevitabilmente la durata della pipeline perché Substract resta in stallo aspettando l’aggiornamento del registro R2, per porre un’istruzione in stallo vengono generate delle istruzioni nulle (NOP) che sostanzialmente creano un ciclo di inattività da parte del processore, queste istruzioni vengono generate dal compilatore o via hardware, di seguito le istruzioni dell’esempio precedente ma con l’introduzioni di istruzioni NOP
Date le due istruzioni in foto capiamo che l’istruzione Substract dovrà aspettare che l’istruzione Add abbia finito, questo allunga inevitabilmente la durata della pipeline perché Substract resta in stallo aspettando l’aggiornamento del registro R2, per porre un’istruzione in stallo vengono generate delle istruzioni nulle (NOP) che sostanzialmente creano un ciclo di inattività da parte del processore, queste istruzioni vengono generate dal compilatore o via hardware, di seguito le istruzioni dell’esempio precedente ma con l’introduzioni di istruzioni NOP
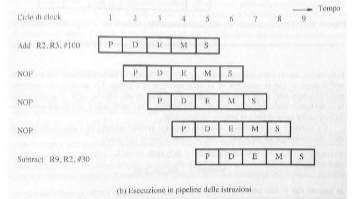 In questo modo l’istruzione Substract inizia solo quando Add ha finito. Per evitare cicli della CPU a vuoto (ovvero le istruzioni NOP) si fa uso della tecnica dell’operand forwarding, il risultato viene salvato nei registri interstadio sin dalla fase di execute in questo modo l’istruzione che ha bisogno di quel dato non deve aspettare che l’istruzione dalla quale dipende finisca tutte le fasi ma basta che arrivi alla fase di execute.
In questo modo l’istruzione Substract inizia solo quando Add ha finito. Per evitare cicli della CPU a vuoto (ovvero le istruzioni NOP) si fa uso della tecnica dell’operand forwarding, il risultato viene salvato nei registri interstadio sin dalla fase di execute in questo modo l’istruzione che ha bisogno di quel dato non deve aspettare che l’istruzione dalla quale dipende finisca tutte le fasi ma basta che arrivi alla fase di execute.
 altre dipendenze del dato affrontate nei capitoli precedenti
altre dipendenze del dato affrontate nei capitoli precedenti
Ritardi nell’accesso alla memoria
Gli accessi alla memoria alcune volte necessitano di diversi cicli di clock infatti nel caso un dato/istruzione non si trovi nella cache si possono avere ritardi di 10 o più cicli di clock che sarebbe il tempo che ci mette il processore a prendere i dati necessari dalla RAM, questo crea chiaramente dei grandi ritardi nella pipeline.
Control hazards
Si verifica un problema nella pipeline quando vengono eseguiti salti condizionali. Durante l’elaborazione di un’istruzione di salto, l’indirizzo di destinazione viene caricato nel Program Counter (PC) solo al terzo stadio della pipeline (fase di esecuzione). Di conseguenza, le istruzioni già caricate negli stadi successivi della pipeline, che si trovano dopo il salto, risultano errate e devono essere scartate
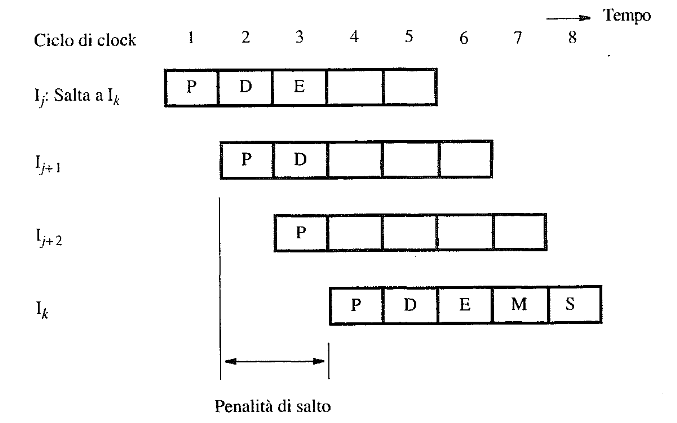 Per mitigare l’impatto dei salti condizionali e migliorare l’efficienza, si possono adottare diverse strategie:
Per mitigare l’impatto dei salti condizionali e migliorare l’efficienza, si possono adottare diverse strategie:
- Salto in fase di decodifica: si può modificare l’hardware in modo da effettuare il salto direttamente nello stadio di decodifica
- Tecnica di salto differito: dove le istruzioni successive al salto vengono eseguite in ogni caso, sarà il compilatore a modificare l’ordine di esecuzione delle istruzioni in modo da eseguire delle istruzioni che vanno eseguite a prescindere negli slice saltati, se non trova istruzioni valide inserisce delle NOP.
Branch penalties
I salti vengono chiamati Branch, i ritardi che accadono a causa dei salti vengono chiamati Branch Delays oppure Branch Penalties questi problemi vengono risolti attraverso le Branch Prediction, se la predizione non va a buon fine abbiamo un Branch Misprediction quando accada questa cosa viene avviato un flush della pipeline dopo la quale la pipeline verrà riempita nel modo giusto. Esistono 2 tipi di branch prediction:
- Predizione statica: usa regole semplici basate su informazioni statiche come la posizione dell’istruzione nel codice o il tipo di istruzione di salto, questo approccio statico è molto rapido e semplice ma può essere meno preciso in situazioni complesse.
- Predizione dinamica: una tecnica che si basa sulla storia dei branch eseguiti in precedenza. Questo approccio sfrutta i buffer di branch prediction (BPB), che fungono da memoria storica per migliorare l’accuratezza della predizione. Più grande è il buffer, maggiore è la precisione della predizione. Ogni branch analizzato viene associato a uno stato, che varia a seconda dell’architettura della macchina:
- In alcune macchine, gli stati possibili sono due:
- PS (Probabilmente Salta)
- PNS (Probabilmente Non Salta)
- In altre macchine, il modello può essere più complesso e utilizzare quattro stati:
- MPS (Molto Probabilmente Salta)
- PS (Probabilmente Salta)
- PNS (Probabilmente Non Salta)
- MPNS (Molto Probabilmente Non Salta) Questo sistema consente di migliorare significativamente la predizione, adattandosi dinamicamente al comportamento dei branch.
- In alcune macchine, gli stati possibili sono due:
Per poter iniziare a fare la predizione dalla fase di Fetch si ha bisogno di una memoria piccola e veloce chiamata Buffer di destinazione di salto questo buffer contiene una tabella con tutte le istruzioni di salto del programma. Per ogni istruzione saranno salvate le seguenti informazioni:
- Indirizzo dell’istruzione
- Uno o due bit di stato per l’algoritmo di predizione
- Indirizzo di destinazione del salto Usando questa tabella ogni volta che viene prelevata un’istruzione, il suo indirizzo verrà cercato nella tabella, se l’istruzione prelevata è un salto si useranno le informazioni in tabella per aggiornare il program counter. In grandi programmi la tabella non contiene tutte le istruzioni di salto, ma viene aggiornata man mano.
Structural Hazards
La pipeline va in stallo quando una risorsa viene richiesta da più istruzioni, per evitare questo problema l’unica soluzione è quella di avere cache separate per istruzione e dati.
Valutazione delle prestazioni
La valutazione delle prestazioni di un processore viene fatta sia per i processori che usano la pipeline sia per quelli che non la usano, la formula chiaramente cambia. Di seguito la legenda per capire le formule successive:
- : Numero di istruzioni macchina
- : Numero di cicli di clock per istruzione (CPI - Cycles Per Instruction)
- : Durata di un ciclo di clock ()
- frequenza di clock del processore
TIP
La formula per calcolare (tempo di esecuzione) di istruzioni in un processore con pipeline è la seguente:
TIP
La formula per calcolare il throughput di un processore è la seguente: Senza pipeline: Con pipeline: nel caso ottimale con pipeline il throughput è uguale ad R
Come già detto la pipeline soffre di conflitti, prendendo in considerazione questi conflitti la formula per il calcolo del throughput diventa:
Formula calcolo del throughput
Ogni tipologia di conflitto indipendente aumenta S di un delta δ dato dal numero di occorrenze del conflitto per il numero medio di cicli di stallo introdotti per evitarlo:
- Conflitti di dipendenza di dato: = ·
- Conflitti di salto: = ·
- Conflitti di cache miss: = ·
Processori superscalari
I processori con più unita di elaborazione vengono chiamati superscalari, nel caso di un processore con 2 unità di elaborazione:
- Unità aritmetica: esegue le istruzione aritmetico-logiche
- Unità Load/Store: esegue le istruzioni di accesso alla memoria
Nel seguente caso la pipeline di questo tipo di processore è diversa da quella di un normale processore, in specifico cambia così:
 Le istruzioni aritmetiche e di accesso alla memoria possono essere eseguite in parallelo a coppie e quindi nei primi due cicli di clock si possono mandare in esecuzione le quattro istruzioni. All’entrata di ogni unità di esecuzione troviamo una stazione di prenotazione dove sono presenti:
Le istruzioni aritmetiche e di accesso alla memoria possono essere eseguite in parallelo a coppie e quindi nei primi due cicli di clock si possono mandare in esecuzione le quattro istruzioni. All’entrata di ogni unità di esecuzione troviamo una stazione di prenotazione dove sono presenti: - Tutte le istruzioni in attesa di esecuzione
- Informazioni e operandi rilevanti per ogni istruzione che troviamo Un’istruzione viene mandata in esecuzione solo quando tutti i suoi operandi sono disponibili
Fase di smistamento nei processori superscalari
Nella fase di smistamento il processore deve assicurarsi che tutte le risorse necessarie ad un’istruzione siano disponibili, in specifico si occupa di verificare la disponibilità dei registri temporanei per contenere i risultati, che ci sia abbastanza spazio nella stazione di prenotazione dell’unità di esecuzione desiderata, e che ci sia una locazione disponibile nel buffer di riordino, inoltre si occupa di prevenire i deadlock (casi in cui due istruzioni rimangono bloccate a causa di dipendenze reciproche)
Esecuzione fuori ordine nei processori superscalari
L’esecuzione fuori ordine nei processori superscalari migliora l’efficienza eseguendo istruzioni non appena pronte, ma può causare conflitti o eccezioni imprecise. Per evitare errori, i risultati vengono salvati in registri temporanei tramite il register renaming. L’unità di commitment, supportata dal buffer di riordino, trasferisce poi i risultati ai registri permanenti rispettando l’ordine originale delle istruzioni, garantendo coerenza e correttezza nell’esecuzione.
Pipeline con i processori CISC
I processori CISC hanno diverse difficoltà nell’utilizzare le pipeline a causa della complessità delle istruzioni, per risolvere questo problema quasi tutti i processori odierni sono si basati su CISC ma le istruzioni vengono dinamicamente convertite in micro-istruzioni RISC che posso essere eseguite nella pipeline in modo più agevole.
08_Struttura-base-del-processore
Questo file è la rielaborazione delle slide 08_Struttura-base-del-processore.pdf
La CPU è un circuito elettronico integrato che ha il ruolo di cervello del calcolatore, e capace di eseguire istruzioni elementari necessarie per eseguire i programmi. É formato da diversi componenti:
- La ALU (Unità logico-aritmetica): esegue le operazioni aritmetiche e logiche necessarie ad eseguire un programma
- CU (Control Unit): genera i bit di controllo per gestire il funzionamento della CPU
- Banco di registri: blocchi di memoria usati dalla CPU durante l’esecuzione delle istruzioni
- PC (Program counter): un registro che contiene l’indirizzo della prossima istruzione da eseguire
- IR (Instruction Register): un registro che contiene l’indirizzo dell’istruzione in esecuzione
- Generatore di indirizzi: un componente che si occupa di aggiornare il contenuto del PC
- Interfaccia processore memoria: gestisce il trasferimento dei dati tra memoria e CPU
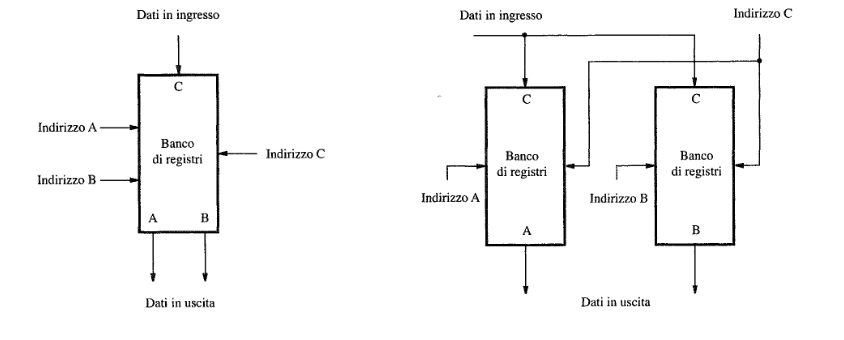
Banco di registri
Un blocco di memoria piccolo e veloce, consiste in vari registri con un circuito per l’accesso in scrittura e lettura. È possibile leggere contemporaneamente i dati da due registri diversi, invece la lettura può avvenire da un registro alla volta, per selezionare il registro da leggere o scrivere, si utilizzano specifici ingressi di indirizzo.
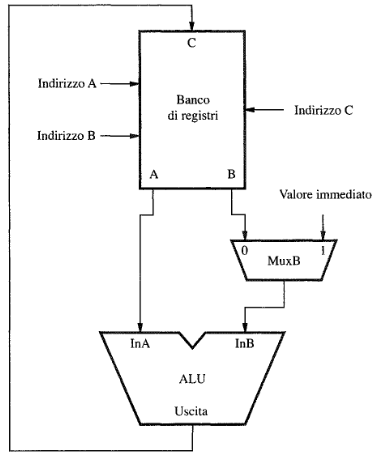
ALU
Un componente della CPU che esegue operazioni aritmetiche e logiche quali la somma, sottrazione, AND, OR, XOR, ecc. É formato da 2 porte di input che rappresentano gli operandi in ingresso collegate direttamente al banco dei registri, una porta di uscita contenente il risultato dell’operazione anche questa collegata al banco dei registri. Alla ALU viene collegato anche il MUX (un multiplexer) che è in grado di introdurre un altro valore all’interno della ALU
Link register
un registro essenziale per la gestione delle chiamate a sottoprogrammi. Quando un programma chiama una funzione o una procedura, l’indirizzo dell’istruzione successiva alla chiamata viene salvato nel link register. Una volta terminata l’esecuzione della sotto procedura, il valore contenuto nel link register viene caricato nel program counter (PC) per far riprendere l’esecuzione del programma principale dal punto esatto in cui era stato interrotto. Ad esempio, se un programma principale chiama una funzione per calcolare il fattoriale di un numero, il link register conterrà l’indirizzo dell’istruzione successiva alla chiamata. Al termine del calcolo del fattoriale, il programma tornerà a eseguire l’istruzione successiva alla chiamata iniziale.
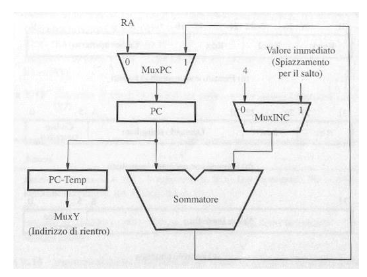
Generatore di indirizzi delle istruzioni
Questo circuito è usato per generare l’indirizzo della prossima istruzione da inserire nel PC. In questo componente troviamo un sommatore che incrementa il valore del PC di una word solitamente (4 byte) o anche di più in caso di salto. Il tipo di incremento da effettuare verra fatto dal MuxINC, il MUXPC seleziona se aggiornare il PC con l’incremento calcolato dal MuxINC o con un indirizzo specifico, inoltre abbiamo PC-Temp che viene usato per salvare il valore di PC da inserire nel LR durante una chiamata a sottoprogramma.
Temporizzazione del processore
Per il corretto funzionamento di un processore, è necessario un segnale elettrico periodico che scandisca il tempo al suo interno, comunemente noto come segnale di clock. Questo segnale, simile a un metronomo, coordina le operazioni dei vari componenti, indicando con precisione quando eseguire ciascuna operazione. Il clock ha il compito fondamentale di sincronizzare il flusso dei dati all’interno del processore, garantendo che ogni componente riceva ed elabori i dati al momento opportuno. Ogni operazione del processore avviene all’interno di un intervallo di tempo definito come ciclo di clock, che rappresenta la durata di un singolo impulso del segnale di clock. Durante un ciclo di clock, i dati vengono trasferiti, elaborati e memorizzati, con ogni fase dell’operazione che si svolge in maniera sequenziale e coordinata. La velocità del processore, comunemente espressa in Hertz (Hz), misura il numero di cicli di clock completati in un secondo, determinando così la rapidità con cui il processore può eseguire le istruzioni.
Esecuzione delle istruzioni
Il processore per mettere in esecuzione un’istruzione segue i seguenti step:
- Prelievo dell’istruzione della memoria (all’indirizzo puntato da PC)
- Incremento di PC di una word (per farlo puntare all’istruzione successiva)
- Esecuzione dell’istruzione prelevata I primi due passi compongono la fase di prelievo e il terzo la fase di esecuzione
Esempio con delle istruzioni assembly:
- LOAD R5, X(R7) questa istruzione carica il valore del registro con indirizzo in R5 e viene eseguita in questo modo:
- Prelievo dell’istruzione ed incremento del PC: Il processore legge l’istruzione dalla memoria e incrementa il Program Counter (PC) per puntare all’istruzione successiva.
- Decodifica dell’istruzione e lettura del contenuto del registro R7: Il processore decodifica l’istruzione per capire quale operazione deve eseguire e legge il valore contenuto nel registro R7.
- Calcolo dell’indirizzo effettivo: Il processore somma il valore contenuto in R7 con l’offset X per ottenere l’indirizzo di memoria esatto da cui leggere il dato.
- Lettura dell’operando sorgente dalla memoria: Il processore accede alla memoria all’indirizzo calcolato al punto precedente e legge il valore che trova in quella locazione.
- Caricamento dell’operando nel registro di destinazione R5: Il valore letto dalla memoria viene copiato nel registro R5, sovrascrivendo qualsiasi valore precedentemente presente in quel registro.
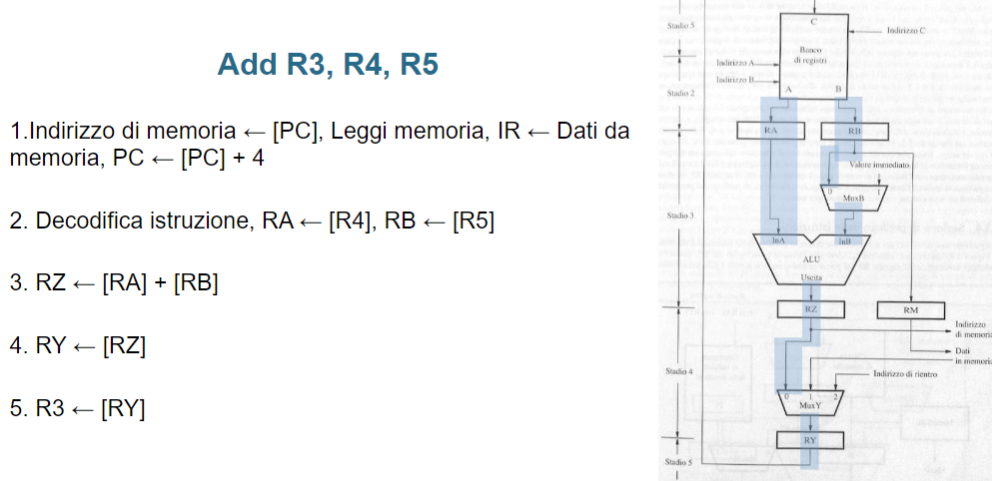
- ADD R3, R4, R5
- Prelievo dell’istruzione ed incremento del PC
- Decodifica dell’istruzione e lettura dei contenuti dei registri sorgenti R4 e R5
- Calcolo della somma R4 + R5
- Caricamento del risultato nel registro di destinazione R3
Più in generale qualsiasi istruzione può essere eseguita in 5 stadi distinti:
- Fetch: preleva un istruzione e incrementa il contatore del programma
- Decode: decodifica l’istruzione e leggi registri dal banco dei registri
- Execute: esegui un’operazione dell’ALU
- Memory: leggi o scrivi dati in memoria
- Write back: il risultato nel registro di destinazione
Calcolo in un solo stadio:
- Svantaggi: Se si volesse eseguire un’intera operazione in un singolo ciclo di clock, il ciclo dovrebbe essere molto lungo. Questo perché il circuito dovrebbe avere il tempo sufficiente per completare tutte le fasi dell’operazione, dalla lettura dei dati, all’esecuzione dei calcoli, fino alla scrittura del risultato.
- Limiti di performance: Un ciclo di clock lungo limita la frequenza di funzionamento del processore, riducendone le prestazioni. Divisione in più stadi:
- Vantaggio: Dividendo l’esecuzione in più stadi più semplici, è possibile accorciare la durata di ciascun ciclo di clock.
- Pipeline: con l’introduzione della pipeline otteniamo dei grandi vantaggi dalla parallelizzazione dei singoli stadi.
- Registri temporanei: Tra uno stadio e l’altro vengono inseriti dei registri temporanei che memorizzano i dati intermedi, consentendo il passaggio fluido da uno stadio all’altro.
Questa è la rappresentazione grafica del data path in modo approfondito (qui la spiegazione semplificata)
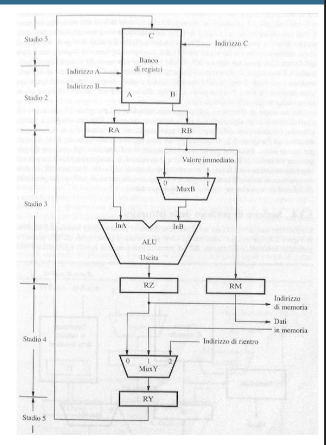 Quello che vediamo in questa immagine può essere riassunto in questo modo:
Quello che vediamo in questa immagine può essere riassunto in questo modo:
- Stadio 1 (non visibile in foto) in questo stadio il datapath si occupa di prelevare i dati dalla memoria, in questo stadio troviamo un multiplexer che decide se prendere l’indirizzo di memoria o da un registro oppure dal PC, fatto ciò mette decodifica l’istruzione e la mette in esecuzione.
- Stadio 2:
- Testo: Le porte di uscita
AeBdel banco di registri copiano i dati nei registri temporaneiRAeRB. - Nel diagramma:
- Il banco di registri fornisce i valori richiesti dalle porte
AeB. - Questi valori vengono copiati rispettivamente nei registri
RAeRB.
- Il banco di registri fornisce i valori richiesti dalle porte
- Testo: Le porte di uscita
- Stadio 3:
- Testo:
RAviene usato come primo ingresso dell’ALU.MuxBdecide se il secondo ingresso dell’ALU proviene daRBo da un valore immediato.- Il risultato dell’ALU è copiato in
RZ. - Il valore di
RBè copiato inRM.
- Nel diagramma:
RAè connesso direttamente al primo ingresso dell’ALU.MuxBseleziona traRBe un valore immediato per il secondo ingresso dell’ALU.- Il risultato dell’ALU (
RZ) viene memorizzato. - Parallelamente, il contenuto di
RBè inviato al registro temporaneoRM.
- Testo:
- Stadio 4:
- Testo:
- Se necessario, l’indirizzo contenuto in
RZè inviato all’interfaccia del processore con la memoria. - Se richiesto, i dati in
RMsono salvati in memoria. MuxYseleziona il valore da memorizzare inRY: può essere il risultato dell’ALU, un dato dalla memoria, o un indirizzo di ritorno da subroutine.
- Se necessario, l’indirizzo contenuto in
- Nel diagramma:
RZpuò essere utilizzato come indirizzo per accedere alla memoria.- I dati temporanei in
RMpossono essere scritti in memoria, se necessario. - Il
MuxYdecide quale valore salvare inRY.
- Testo:
- Stadio 5:
- Testo: Il contenuto di
RYviene salvato nel banco di registri. - Nel diagramma:
- L’uscita di
RYè connessa alla porta di ingressoCdel banco di registri. - Il dato è quindi memorizzato nel registro corrispondente.
- L’uscita di
- Testo: Il contenuto di
Esempio
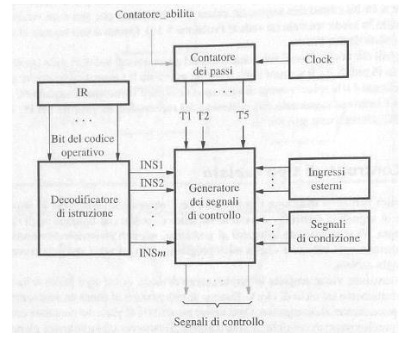
Segnali del processore
Per eseguire le istruzioni macchina il processore deve generare le sequenze di segnali di controllo per ogni stadio, questi segnali si dividono in:
- Segnali di selezione per i multiplatori
- Segnali di attivazione di alcuni registri
- Segnali di condizione
- Segnali per la gestione della memoria
Un approccio per generare i segnali di controllo consiste nel controllo cablato formato dai seguenti componenti:
- Contatore dei passi: che scandisce gli stadi di esecuzione, questo contatore all’inizio dell’esecuzione di un’istruzione ha come valore 0 che aumenta fino a 5 per ogni stadio di esecuzione
- Decodificatore di istruzione: genera un vettore lungo m mettendo a 1 solo il bit corrispondente all’istruzione letta su IR
- Generatore dei segnali di controllo: produce i segnali di controllo sulla base dell’istruzione in esecuzione, dello stadio attuale (letto dal contatore), dei segnali di condizione e di segnali esterni come le interruzioni. I segnali generati sono predefiniti a livello hardware
 Non sempre gli accessi alla memoria possono essere eseguiti in un singolo ciclo di clock, infatti se una risorsa non si trova dentro la cache (cache miss) ci voglio molteplici cicli di clock per recuperarla, quando questo succede la control unit dei processori si mette in ascolto aspettando un segnale chiamato MFC (memory function completed) che indica il coretto caricamento in memoria di un dato, è importante ricordare che durante l’accesso alla memoria il contatore dei passi deve essere bloccato per fare ciò viene generato un segnale WMFC (Wait for memory function completed) che dice al contatore dei passi di aspettare un segnale MFC (e quindi la fine della fase di fetch) per riprendere a contare.
Non sempre gli accessi alla memoria possono essere eseguiti in un singolo ciclo di clock, infatti se una risorsa non si trova dentro la cache (cache miss) ci voglio molteplici cicli di clock per recuperarla, quando questo succede la control unit dei processori si mette in ascolto aspettando un segnale chiamato MFC (memory function completed) che indica il coretto caricamento in memoria di un dato, è importante ricordare che durante l’accesso alla memoria il contatore dei passi deve essere bloccato per fare ciò viene generato un segnale WMFC (Wait for memory function completed) che dice al contatore dei passi di aspettare un segnale MFC (e quindi la fine della fase di fetch) per riprendere a contare. - AbilitaContatore =
DANGER
Tutto quello che abbiamo descritto fino ad adesso vale solo per i processori RISC infatti quest’ultimi sono gestibili in più stadi grazie alla lunghezza delle istruzioni ridotta.
Interconnessione
All’interno di un processore tutti i componenti vengono messi in contatto attraverso il blocco di interconnessione, quest’ultimo è un insieme di bus. La porta logica che invia un segnale su una linea di bus è chiamata bus driver, i dispositivi sono collegati al bus tramite le porte tri-state, a differenza delle normali porte logiche che hanno solo due stati (0 e 1), le porte tri-state possono assumere un terzo stato: l’alta impedenza. In pratica, quando una porta è in questo stato, si comporta come se fosse scollegata dal circuito, non influenzando il segnale presente sul bus. Il bus verrà influenzato solo dalle porte non in alta impedenza.
Interconnessione usando 3 bus
Il blocco di interconnessione può essere costruito usando 3 BUS il bus A, e il B usati per i dati in input e il Bus C per i dati in output, il generatore di indirizzi è collegato direttamente al PC. Con questo tipo di architettura possiamo eseguire un’istruzione in 3 cicli di clock.
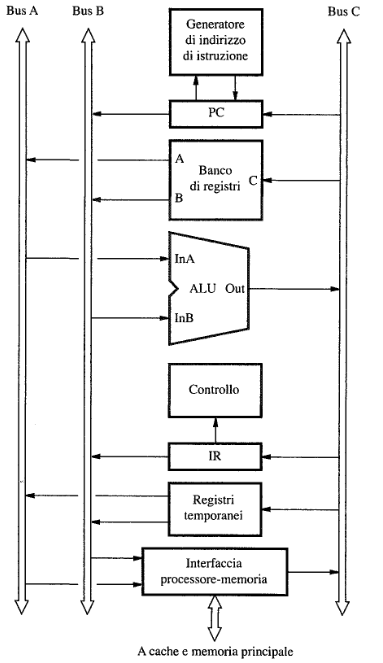
Primo ciclo:
 Secondo ciclo:
Secondo ciclo:
 Terzo ciclo:
Terzo ciclo:

Controllo microprogrammato
I segnali di controllo di ogni passo vengono raccolti in una word di memoria chiamata microistruzione. L’insieme di microistruzioni rappresentanti i passi di un’istruzione macchina si chiamano microroutine. Le microistruzioni di ciascuna microroutine vengono immagazzinate in locazioni consecutive della memoria di controllo, il registro contiene l’istruzione della prossima microistruzione da caricare. All’inizio di un istruzione macchina il generatore di indirizzi delle microistruzioni carica sul μPC la prima istruzione della microroutine corrispondente ad ogni passo μPC viene incrementato di un passo per puntare alla microistruzione corretta.
Microprogrammato vs Microcablato
Controllo microcablato:
- Implementazione: I segnali di controllo sono generati attraverso un circuito logico cablato.
- Velocità: È generalmente più veloce poiché non dipende dall’accesso a una memoria di controllo.
- Flessibilità: È meno flessibile, perché le modifiche al set di istruzioni richiedono un aggiornamento fisico dell’hardware.
- Complessità: La complessità cresce rapidamente con il numero di istruzioni e segnali di controllo. Controllo microprogrammato:
- Implementazione: I segnali di controllo sono memorizzati in una memoria di controllo sotto forma di “microistruzioni” organizzate in “microroutine”.
- Velocità: Più lento rispetto al microcablato a causa dei tempi di accesso alla memoria di controllo.
- Flessibilità: Molto più flessibile, perché le modifiche al set di istruzioni possono essere apportate cambiando le microistruzioni nella memoria.
- Complessità: È più scalabile, particolarmente utile per architetture complesse.
É difficile determinare quale sia la migliore infatti questo dipende dall’applicazione:
- Il microcablato è preferibile in sistemi con requisiti di alte prestazioni e dove il set di istruzioni è stabile, come nelle applicazioni embedded o nei processori ad alta velocità.
- Il microprogrammato è ideale per processori generici o complessi (ad esempio, con molte istruzioni) dove è necessaria flessibilità, come nei primi sistemi CISC.
09_Algebra-booleana
Questo file è la rielaborazione delle slide 09_Algebra-booleana.pdf
Operatori logici
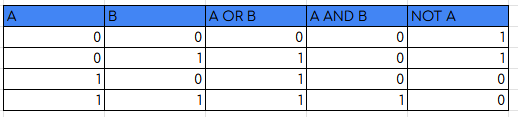
l’algebra booleana della commutazione è un sistema algebrico in cui ogni variabile può assumere solo 2 valori (0 o 1). Possiede operazioni basilari:
- Somma logica o OR
- ovvero una funzione che accetta 2 argomenti è vale 1 solo se almeno uno dei suoi ingressi è 1. Si denota tramite gli operatori a due argomenti “+” o “V”.
- Di seguito le proprietà:
- Commutativa: =
- Associativa:
- Elemento neutro:
- Prodotto logico o AND
- Una funzione che accetta 2 argomenti in input e vale 1 solo se tutti i suoi ingressi sono 1. Si denota tramite gli operatori a due argomenti “·” o “∧”
- Di seguito le proprietà: - Commutativa: = - Associativa: - Elemento neutro:
- Complementazione o NOT
- è una funzione che accetta un’argomento e ne inverte il valore. Si denota tramite l’operatore di sopra lineatura “¯” o di negazione “¬”
Di seguito la tabella di verità di tutte le espressioni
 OR (somma) e AND (prodotto) hanno le seguenti proprietà:
OR (somma) e AND (prodotto) hanno le seguenti proprietà:

- è una funzione che accetta un’argomento e ne inverte il valore. Si denota tramite l’operatore di sopra lineatura “¯” o di negazione “¬”
Di seguito la tabella di verità di tutte le espressioni
Varie definizioni
Funzione logica: definiamo funzione logica una funzione con più variabili binarie di ingresso ed una variabile binaria di uscita.
Tabella di verità: tutte le funzioni logiche possono essere espresse attraverso una tavola di verità, queste tabelle sono formate da righe ed colonne, dove è il numero di variabili in ingresso.
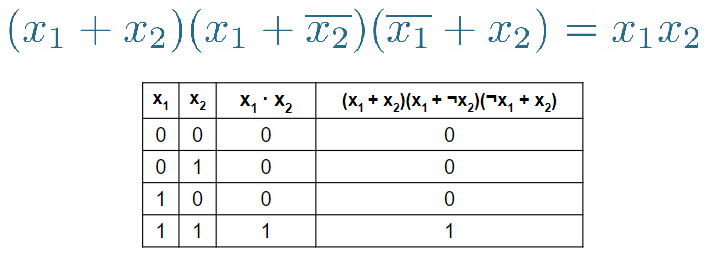
Espressioni logiche: Unendo più funzioni logiche si ottengono le espressioni logiche, esistono infinite espressioni logiche che danno come risultato la stessa funzione logica. Due espressioni logiche si dicono equivalenti se rappresentano la stessa funzione logica, come nell’esempio di seguito:
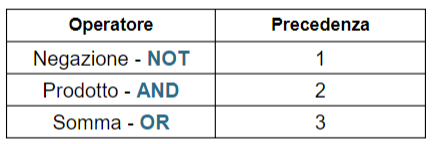
 Nel risolvere un’espressione logica dobbiamo stare attenti alla precedenza tra gli operatori, di seguito gli ordini di precedenza da seguire:
Nel risolvere un’espressione logica dobbiamo stare attenti alla precedenza tra gli operatori, di seguito gli ordini di precedenza da seguire:
TIP
Per calcolare i valori assunti da una funzione ci basta calcolare la sua tabella di verità
Mintermine: funzione ad variabili che vale solo per una specifica configurazione delle variabili.
Maxtermine: funzione ad variabili che vale 0 solo per una specifica configurazione delle variabili.
Forme canoniche: tutte le espressioni logiche possono essere rappresentate in delle forme dette “normali”
Forma minima: Un’espressione logica si dice in forma minima quando non esiste nessun’altra espressione equivalente con un costo inferiore, il costo di un’espressione logica è dato dal numero di comparse delle variabili nell’espressione stessa.
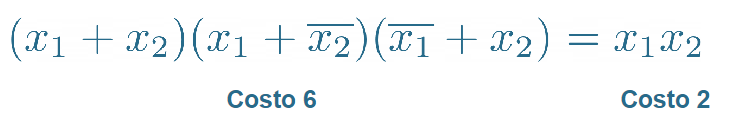
per passare da prima forma canonica a forma minima seguire i seguenti passi:

Porte logiche
Tutte le operazioni logiche citate possono essere eseguite da semplici circuiti elettronici, questo circuiti sono formati da delle porte logiche, ognuna va a rappresentare una delle operazioni logiche sopracitate.
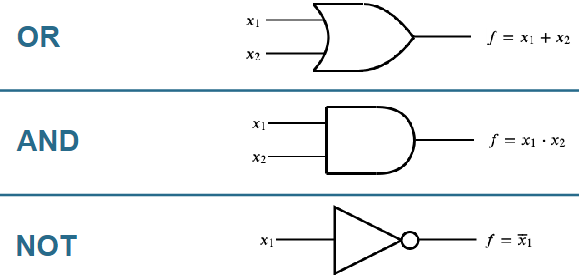 Queste porte godono di tutte le proprietà delle funzioni logiche. Inoltre abbiamo anche altre 3 porte molto importanti:
Queste porte godono di tutte le proprietà delle funzioni logiche. Inoltre abbiamo anche altre 3 porte molto importanti:
- XOR (anche detto OR esclusivo): funzione che vale 1 solo se gli 1 nei sono ingressi sono in numero dispari, si denota con il simbolo “⊕”
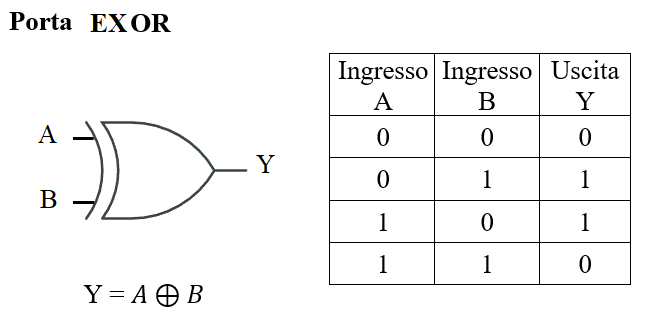
- NAND: porta che si denota con il simobolo "" e ha la seguente tabella di verità
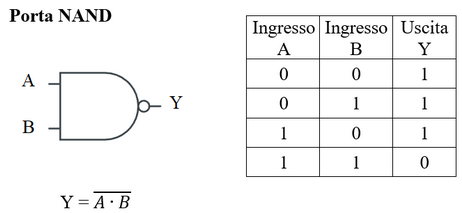
- NOR: porta che si denota con il simbolo "" e ha la seguente tabella di verità
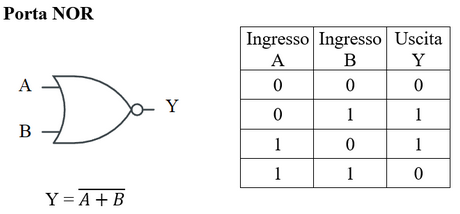 Le porte NAND e NOR sono considerate porte universali, usando queste porte si può realizzare qualsiasi funzione.
Le porte NAND e NOR sono considerate porte universali, usando queste porte si può realizzare qualsiasi funzione.
- una porta NAND con ingressi unificati si comporta come una porta NOT
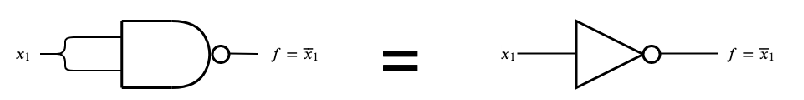
10_Circuiti-aritmetici
Questo file è la rielaborazione delle slide 10_Circuiti-aritmetici.pdf
La somma tra due numeri binari avviene in questo modo:
 Il riporto in uscita della somma precedente viene assegnato come riporto in entrata alla somma successiva. Questo tipo di addizioni vengono fatte continuamente all’interno della nostra macchina, e questo viene fatto attraverso gli addizionatori, esistono vari tipi di addizionatore:
Il riporto in uscita della somma precedente viene assegnato come riporto in entrata alla somma successiva. Questo tipo di addizioni vengono fatte continuamente all’interno della nostra macchina, e questo viene fatto attraverso gli addizionatori, esistono vari tipi di addizionatore:
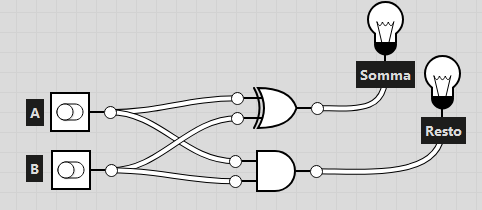
- Half adder: Un circuito molto semplice che fa la somma di 2 bit (calcolando il riporto in uscita) senza considerare alcun riporto in ingresso. Ha 2 uscite:
- Somma: ovvero l’uscita di una porta XOR
- Riporto: ovvero l’uscita di una porta AND
Di seguito la rappresentazione grafica di questo circuito:
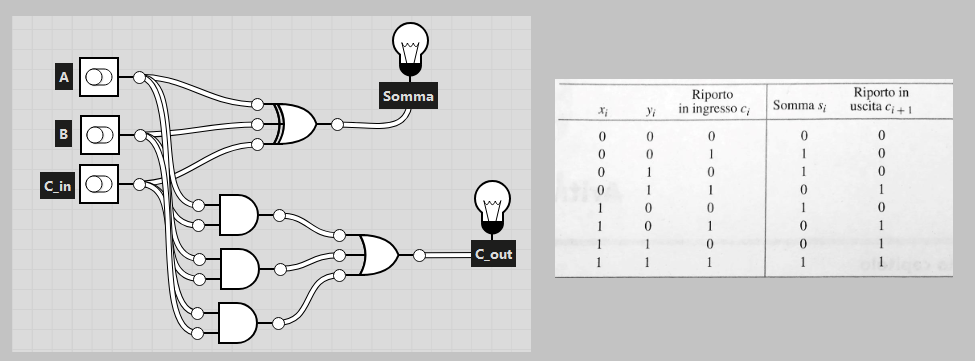
- Full adder: anche chiamato addizionatore ad 1 bit può essere espresso da 2 funzioni logiche a tre ingressi, i due bit da sommare (chiamati in seguito e ) e l’eventuale riporto in entrata (chiamato in seguito ):
- Somma: calcola la somma tra i 2 bit in entrata ed il riporto in ingresso, usando questa formula: praticamente una porta XOR a tre ingressi.
- Riporto: La seconda funzione logica calcola il riporto in uscita, usando questa formula:
Di seguito la tabella di verità e la rappresentazione grafica del circuito:
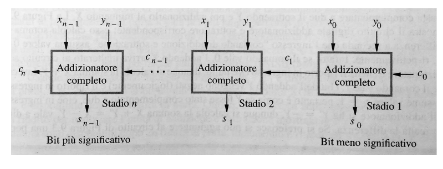
- Ripple carry adder: anche chiamato addizionatore con propagazione di riporto, si ottiene collegando tra di loro diversi full-adder in modo da propagare il riporto, di seguito la rappresentazione grafica:
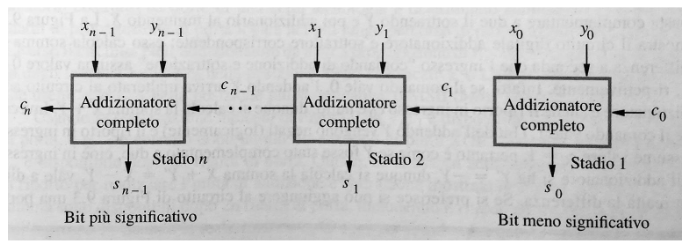 Il problema principale di questo addizionatore è che ogni full adder per andare avanti devo aspettare il calcolo del resto dell’adder precedente, questo crea dei rallentamenti. Il termine “ripple” indica che il riporto si propaga sequenzialmente da un bit al successivo, come un’onda.
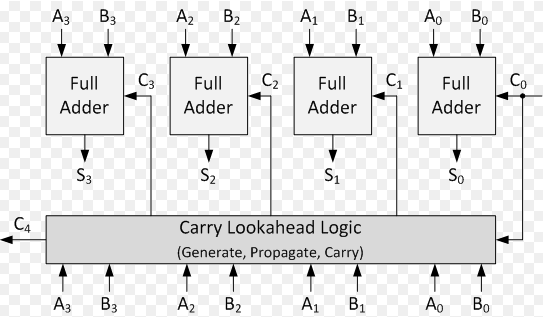
Il problema principale di questo addizionatore è che ogni full adder per andare avanti devo aspettare il calcolo del resto dell’adder precedente, questo crea dei rallentamenti. Il termine “ripple” indica che il riporto si propaga sequenzialmente da un bit al successivo, come un’onda. - Carry lookahaed adder: per risolvere il problema del ripple carry adder nasce questo tipo di addizionatore, che va a calcolare il resto in parallelo propagandolo in base a delle formule matematiche (funzioni e spiegato in seguito), tutto ciò lo rende più veloce e quindi viene ancora oggi usato dentro le ALU dei processori.
Trabocco (Overflow)
Si parla di trabocco quando andiamo a sommare dei bit e il risultato dell’operazione aritmetica è un numero che supera le capacità di rappresentazione del circuito. Il trabocco avviene molto spesso nelle operazioni algebriche dove si prendono in considerazioni numeri con segno.
- Addizionatore algebrico: è un circuito logico che somma due numeri binari a n bit, considerando anche il segno, la parte importante per questo circuito è la gestione dell’Overflow, infatti viene calcolato utilizzando questo formula: con che sarebbe il riporto generato dall’ultimo bit, e il riporto generatore dal penultimo bit, in pratica se il risultato di questa formula ci da 1 c’è stato un trabocco.
Ripple Carry Adder e Calcolo del Ritardo Il ritardo totale del circuito dipende dal percorso più lento.
- In un Full Adder (FA):
- La somma parziale è calcolata dopo 1 ritardo di porta:
- Il riporto è calcolato dopo 2 ritardi di porta:
- La somma parziale è calcolata dopo 1 ritardo di porta:
- In un Ripple Carry Adder a bit:
- L’ultimo riporto è calcolato dopo ritardi di porta.
- L’ultimo bit di somma è calcolato dopo ritardi di porta.
Funzioni di Generazione e Propagazione Riscrivendo: introduciamo:
- Funzione di generazione:
- Funzione di propagazione:
Il riporto diventa: questa formula ci avvantaggia perché e dipendono solo dagli ingressi e e possono essere calcolati in parallelo.
Carry lookahaed adder a 2 livelli: Per ridurre ulteriormente il tempo di calcolo si utilizza una struttura a più livelli logici, in pratica si prende la struttura di Carry lookahaed adder e la si estende su due livelli.
Circuito moltiplicatore sequenziale: gli addizionatori vengono anche utilizzati per fare le moltiplicazioni, infatti la moltiplicazioni di numeri senza segno può essere realizzata usando un addizionatore ad n bit e due registri.
A = 0
Q = Moltiplicatore
M = Moltiplicando
Per n cicli:
se q[0] = 1:
A = A + M
altrimenti:
A = A + 0
c = riporto
A scorre verso destra di una posizione
Q scorre verso destra di una posizione
c scorre verso destra di una posizione
Alla fine del ciclo concatenando i contenuti di A e Q si otterrà il prodotto finale
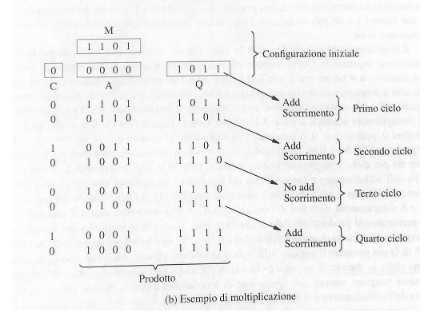
Moltiplicazione dei numeri con segno: per i numeri con il segno la situazione si complica un po’, usiamo l’algoritmo di Booth: L’algoritmo di Booth è un metodo efficiente per moltiplicare numeri binari con segno in complemento a due. L’idea chiave è ricodificare il moltiplicatore come somme e sottrazioni di potenze di 2. Nel caso semplice in cui il moltiplicatore contiene una sequenza contigua di 1, Il prodotto è uguale al moltiplicando fatto scorrere di 5 posizioni a sinistra + il complemento a 2 del moltiplicando fatto scorrere di 1 posizione a sinistra.
Ricodifica bit-pair Il ricodifica Bit-pair è una tecnica di compressione dei dati utilizzata per ridurre la lunghezza di una sequenza di bit senza perdere informazioni questo lo fa raggruppando i bit in coppia (bit pair) e li codifica in un nuovo formato.
Divisione con ripristino: anche questo tipo di circuito viene realizzato usando un addizionatore n+1 bit, un registro() e 2 shift register ( e ), questi componenti vengono usati dentro un ciclo che esegue volte i seguenti passaggi:
- Fare scorrere e a sinistra di una posizione
- Sottrarre da e porre il risultato in
- Se il segno di è 1, porre a 0 e sommare ad ; altrimenti, porre a 1 All’inizio contiene il Divisore, contiene 0 e contiene il Dividendo Alla fine contiene il Resto e contiene il Quoziente
Numeri in virgola mobile: un numero in binario con virgola mobile viene rappresentato da:
- Un segno per il numero
- La mantissa
- Un esponente con segno in base 2
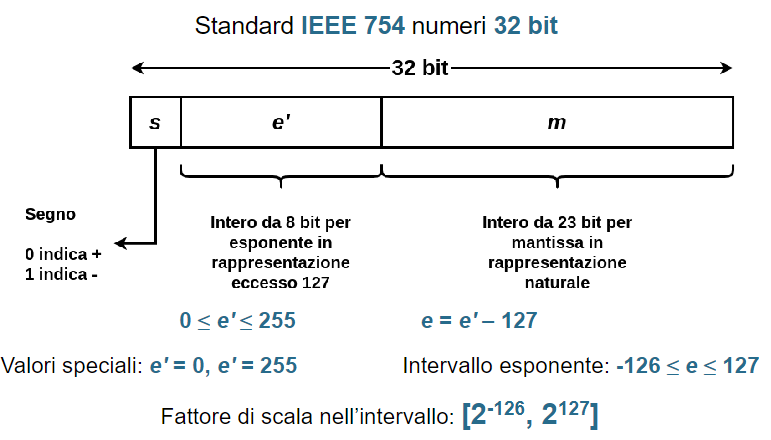
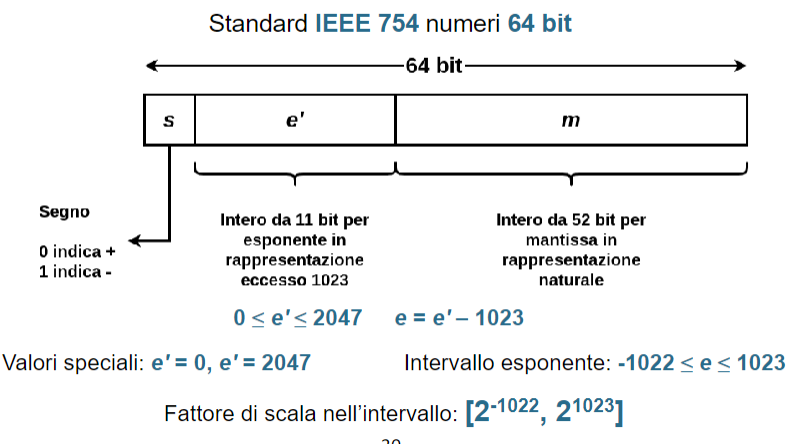
11_Insieme-di-istruzioni-macchina
Questo file è la rielaborazione delle slide 11_Insieme-di-istruzioni-macchina.pdf
ISA
Le istruzioni elementari che un processore è in grado di eseguire sono definite nell’ISA (Instruction Set Architecture), queste istruzioni elementari vengono definite attraverso un alfabeto binario. Il linguaggio assemblativo (assembly) è una rappresentazione simbolica del linguaggio macchina. Esistono 2 grandi famiglie di ISA:
- CISC (Complex Instruction Set Architecture): Basata su istruzioni complesse, che possono anche occupare più di una word di memoria.
- RISC(Reduced Instruction Set Architecture): Basata su istruzioni semplici, con le istruzioni che al massimo occupano una word, di solito sono molto efficienti grazie all’utilizzo della pipeline
Memoria
Il calcolatore lavora su gruppi di bit detti Parole(word), ogni parola nella nostra memoria è associata ad un indirizzo binario univoco, parole consecutive sono associate ad indirizzi consecutivi. Un numero binario con bit potrà indirizzare al massimo indirizzi. L’unità minima di informazione indirizzabile in memoria è il byte, di solito i dati vengono immagazzinati in 2 modi diversi:
- Big-endian(Crescente): memorizzazione/trasmissione che inizia dal byte più significativo (estremità più grande) per finire col meno significativo
- Little-endian(Decrescente): memorizzazione/trasmissione che inizia dal byte meno significativo (estremità più piccola) per finire col più significativo.
Programmare in assembly
Il programmatore scrive i programmi in linguaggio assemblativo (assembly), che vengono tradotti in linguaggio macchina dall’assemblatore. Il codice risultante in linguaggio macchina viene poi eseguito direttamente dal processore.
Registri e locazioni di memoria
All’interno del nostro processore abbiamo diverse locazioni di memoria usate per immagazzinare dati di lavoro usati dalla CPU durante l’esecuzione delle istruzioni. Di solito i registri generici del processore vanno da: R0 ad Rn, abbiamo anche dei registri speciali come il PC (Program Counter) e IR (Istruction Register)
Istruzioni di base in assembly:
LOAD destinazione sorgente
STORE sorgente destinazione
ADD destinazione sorgente1 sorgente2
SUB destinazione sorgente1 sorgente2
Queste istruzioni fanno:
- LOAD: carica un dato dalla memoria in un registro del processore
- STORE: carica un dato presente in un registro di un processore in memoria
- ADD: somma il contenuto di 2 registri
- SUB: sottrae il contenuto di 2 registri
Nel linguaggio assemblativo, gli operandi e il risultato delle istruzioni possono essere espressi in modi diversi, i metodi con cui specificare operandi e risultato vengono chiamati modi di indirizzamento, i modi di indirizzamento base sono:
- Modo immediato: specificando direttamente l’operando
- Add R4, R6, #200
- Modo di registro: indicando il nome del registro del processore
- Load R2, R5
- Modo assoluto: indicando l’indirizzo di una word in memoria
- Load R2,
- Indiretto da registro: indicando un registro con all’interno l’indirizzo della word in memoria
- Load R2,(R5)
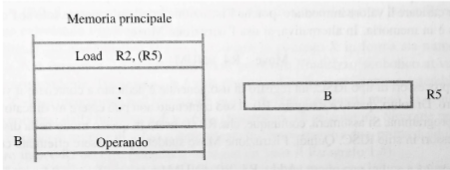
- Load R2,(R5)
- Con indice e spiazzamento: L’indirizzo effettivo di un operando è ottenuto prendendo l’indirizzo come nel caso “indiretto da registro” e sommandogli una costante
- LOAD R2,20(R5)

- LOAD R2,20(R5)
- Con base e indice: l’indirizzo effettivo è ottenuto sommando il contenuto di 2 registri.
Istruzione condizionale:
Branch_if condizione destinazione salto.
Branch_if_[R2]>0 CICLO
Istruzione usata per saltare all’esecuzione di un’istruzione specifica nel caso la condizione di salto sia vera
Direttive di assemblatore
Per aiutare l’assemblatore nella traduzione del nostro programma in codice binario esistono le direttive all’assemblatore, queste non vengono tradotte in vero e proprio codice binario ma servono per dare delle informazioni utili all’assemblatore. Ne esistono di vario tipo:
NOME EQU valore_numerico
ORIGIN indirizzo_memoria
RESERVE spazio_in_byte
DATAWORD contenuto_da_assegnare
- EQU: associa il valore numerico nome
- ORIGIN: indica l’indirizzo di partenza dove inserire le istruzioni
- RESERVE: indica all’assemblatore di riservare uno spazio di memoria espresso in byte
- DATAWORD: Inizializza una word di memoria con il contenuto passato
Generiche istruzioni assembly:
Di solito le istruzioni di assembly seguono la seguente struttura:
 Inoltre l’assemblatore ci permette di denotare i numeri in diversi formati:
Inoltre l’assemblatore ci permette di denotare i numeri in diversi formati:
- Binaria: %
- Add R2, R3, #%01011101
- Decimale: nessun prefisso
- Add R2, R3, #93
- Esadecimale: 0x
- Add R2, R3,
Pila(Stack)
Per gestire gli aspetti fondamentali di un programma (le chiamate a funzione, allocazione dinamica, ecc…)assembly usa lo stack, questa è una struttura dati basata sul paradigma LIFO (Last In First Out), abbiamo un registro speciale del processore chiamato SP(Stack pointer) che punta alla cima della lista, in questa struttura dati si possono fare solo 2 operazioni:
- PUSH: aggiunge un elemento in cima alla pila, di solito si implementa così:
Load Rj, (SP);prendo il valore dalla cima e lo salvo in Rj
Add SP, SP, #4;aumento l'indirizzo cosi da spostarmi alla nuova cima
- POP: preleva un elemento dalla cima, di solito si implementa così:
Load Rj, (SP)
Add SP, SP, #4
Funzioni
Una funzione anche detto sottoprogramma è una lista di istruzioni che eseguono un compito specifico e che possono essere richiamate in un qualsiasi momento durante l’esecuzione di un programma, la chiamata alla funzione viene fatta usando una funzione di salto detta Call Istruction, nella funzione invece per ritornare alla routine chiamate viene usata l’istruzione Return Istruction, l’indirizzo di rientro di una funzione viene salvato nel Link Register.
CALL Indirizzo
RETURN
- CALL: chiama la funzione specificata seguendo questi 2 passi:
- Salva il contenuto del registro PC nel Link register
- Salta all’indirizzo di destinazione indicato nell’istruzione di chiamata
- RETURN: salta all’indirizzo di rientro e lo fa salvando nel PC il contenuto del Link register
Per passare i parametri a queste funzioni ci sono 2 modi:
- Tramite registri: il numero di dati è limitato al numero di registri
- Tramite lo stack: il numero di dati è virtualmente illimitato
il blocco dello stack riservato ai sottoprogrammi si chiama Stack Frame, il Frame Pointer è il puntatore a questa area della memoria, dentro questa area dello stack troviamo molte informazioni come le variabili locali e i loro valori. Quando abbiamo delle chiamate a funzione annidate dobbiamo ricorda di salvare l’indirizzo del link register dentro la pila, in modo da sapere sempre dove ritornare. In alcune architetture questa cosa viene fatta in automatico.
Codifica delle istruzioni
Codice operativo
Il codice operativo o OpCode corrisponde alla procedura da mettere in esecuzione quando si deve eseguire un’istruzione
Le istruzioni in assembly possono cambiare in base all’architettura del processore, nel caso di una CPU a 32 bit possono essere usate le seguenti codifiche:
- Formato con operandi in registri: In questo caso parliamo di istruzioni di questo tipo: ADD R1,R2,R3 dove:
- I 15 bit più significativi vengono usati per gli indirizzi dei 3 registri (5 bit cadauno)
- I restanti 17 bit per il codice operativo

- Formato con operando immediato: in questo caso parliamo di istruzioni di questo tipo: ADD R1,R2,#5 dove:
- 10 bit vengono usati per gli indirizzi dei registri,
- 6 bit vengono usati per il codice operativo
- 16 bit vengono usati per operando immediato

- Formato per chiamata: in questo caso parliamo di istruzioni di questo tipo: CALL 0x00400010 dove:
- 6 bit vengono usati per il codice operativo
- 26 bit per rappresentare l’indirizzo della funzione da chiamare
Register Transfer Notation (RTN)
La notazione a trasferimento di registro serve a descrivere formalmente il trasferimento di informazioni tra memoria e registri. Il simbolo utilizzato è :
- A sinistra troviamo un indirizzo di memoria
- A destra troviamo un valore semplice o un’espressione

Istruzioni logiche
AND destinazione,sorgente1,sorgente2
OR destinazione,sorgente1,sorgente2
- AND: fa un and tra le sorgenti
- OR: fa un or tra le sorgenti
Scorrimenti e rotazioni
Scorrimento logico:
Le operazioni di scorrimento logico fanno scorrere i bit di un registro a destra o a sinistra di n posizioni, i bit in uscita vengono persi, ad eccezione dell’ultimo bit che viene memorizzato nel bit di riporto c
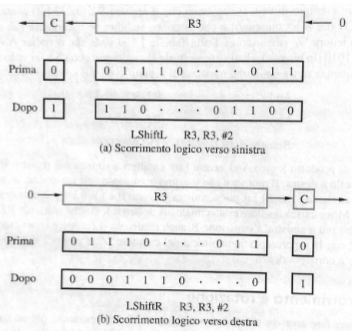 Scorrimento aritmetico:
Lo scorrimento aritmetico verso destra funziona come quello logico, ma riempie le posizioni lasciate libere con il valore del bit più significativo
Scorrimento aritmetico:
Lo scorrimento aritmetico verso destra funziona come quello logico, ma riempie le posizioni lasciate libere con il valore del bit più significativo
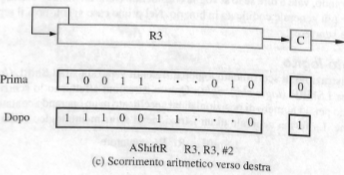 Rotazione
La rotazione è un’operazione di scorrimento dove i bit in uscita da un lato vengono fatti rientrare dall’altro. L’ultimo bit in uscita viene scritto nel bit di riporto c.
Rotazione
La rotazione è un’operazione di scorrimento dove i bit in uscita da un lato vengono fatti rientrare dall’altro. L’ultimo bit in uscita viene scritto nel bit di riporto c.
 Rotazione con riporto
Nella rotazione con riporto il bit di riporto viene incluso nella sequenza di bit da ruotare. Nel caso di rotazione a sinistra il bit di riporto viene aggiunto alla sinistra dei bit del registro da ruotare. Nel caso di rotazione a destra il bit di riporto viene aggiunto alla destra dei bit del registro da ruotare
Rotazione con riporto
Nella rotazione con riporto il bit di riporto viene incluso nella sequenza di bit da ruotare. Nel caso di rotazione a sinistra il bit di riporto viene aggiunto alla sinistra dei bit del registro da ruotare. Nel caso di rotazione a destra il bit di riporto viene aggiunto alla destra dei bit del registro da ruotare

Altre istruzioni dell’assembly
LoadByte Rdst, LOCBYTE
StoreByte Rsrc, LOCBYTE
Multiply Rk, Ri, Rj
Divide Rk, Ri, Rj
- LoadByte: legge un singolo byte dalla memoria e lo registra negli 8 bit meno significativi del registro destinazione mettendo a 0 gli altri bit
- StoreByte: salva gli 8 bit meno significativi del registro sorgente nella locazione di memoria specificata
- Multiply: effettua la moltiplicazione tra i due numeri contenuti nei registri
- Divide: effettua la divisione tra due numeri in complemento a due contenuti in due registri
Istruzioni esclusive delle architteture CISC

DANGER
Le istruzioni scritte di seguito sono istruzioni esclusive di un architettura CISC
Istruzioni aritmetiche Questo tipo di istruzioni hanno un formato a 2 indirizzi, dove l’indirizzo di destinazione servirà sia da ingresso che anche da risultato.
Operazione destinazione, sorgente
ADD B,A
MOVE
Move destinazione, sorgente
L’istruzione Move permette il trasferimento di dati tra registri ed indirizzi di memoria Indirizzamento per autoincremento Nell’indirizzamento per autoincremento, l’indirizzo dell’operando è contenuto in un registro il cui nome viene specificato nell’istruzione. Alla fine dell’istruzione il contenuto del registro viene incrementato di un’unità. Può essere usata per eseguire l’operazione di Pop:
Move ELEMENTO, (SP)+
Indirizzamento per autodecremento Nell’indirizzamento per autoincremento, l’indirizzo dell’operando è contenuto in un registro il cui nome viene specificato nell’istruzione. Prima di eseguire l’istruzione, il contenuto del registro viene decrementato di un’unità. Può essere usata per eseguire l’operazione di Push:
Move -(SP), NUOVOELEMENTO
Bit di esito
sono bit speciali immagazzinati a in un registro interno al processore, e vengono usati per tenere traccia dell’esito di svariate operazioni. Quelli più comuni sono:

12_Tecnologia-microelettronica
Questo file è la rielaborazione delle slide 12_Tecnologia-microelettronica.pdf
Rappresentazione delle variabili binarie
- Nei circuiti elettronici, i valori binari 0 e 1 sono rappresentati da livelli di tensione.
- La soglia separa gli 0 dagli 1. Ad esempio, in un sistema a 5V:
- Tensioni sotto 1,5V = 0.
- Tensioni sopra 3,5V = 1.
- Per evitare errori, esiste una “banda vietata” vicino alla soglia dove i valori non sono validi.
- La banda vietata riduce le incertezze causate da rumore e disturbi.
Cos’è un transistor?
- Un transistor è un semiconduttore usato per amplificare o commutare segnali elettronici.
- Materiali come il silicio sono drogati per creare zone positive e negative.
- Funziona come un interruttore che può essere in conduzione o in interdizione.
- Esistono due tipi principali di transistor:
- BJT (bipolare): La corrente è controllata da una corrente di base.
- FET (a effetto di campo): La corrente è controllata dalla tensione applicata al gate.
Tecnologia MOS (Metallo-Ossido-Semiconduttore)
- I transistor MOS sono i più comuni nei circuiti integrati.
- Valori tipici di tensione:
- ,
- ,
- Sopra la soglia = 1, sotto la soglia = 0.
- La tecnologia MOS consente di ridurre dimensioni e consumi, rendendo possibile l’integrazione di miliardi di transistor.
Tipi di transistor MOS
- NMOS:
- Conduzione con tensione alta in ingresso.
- Sorgente collegata a massa.
- PMOS:
- Conduzione con tensione bassa in ingresso.
- Sorgente collegata all’alimentazione.
Realizzazione di porte logiche con transistor
- NOT:
- Un singolo NMOS inverte il segnale.
- Es.: ingresso = 1 → uscita = 0.
- NOR:
- Due NMOS in parallelo.
- Es.: uscita = 1 solo se entrambi gli ingressi = 0.
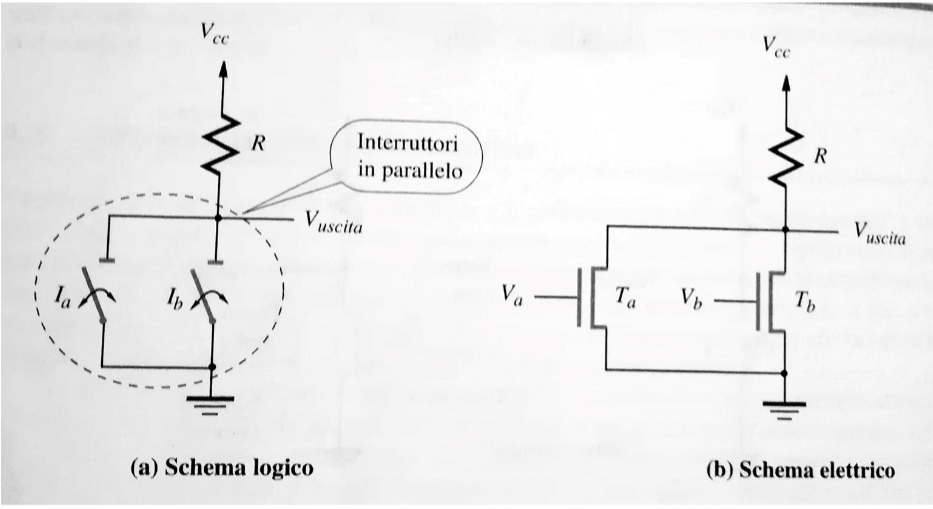
- NAND:
- Due NMOS in serie.
- Es.: uscita = 0 solo se entrambi gli ingressi = 1.
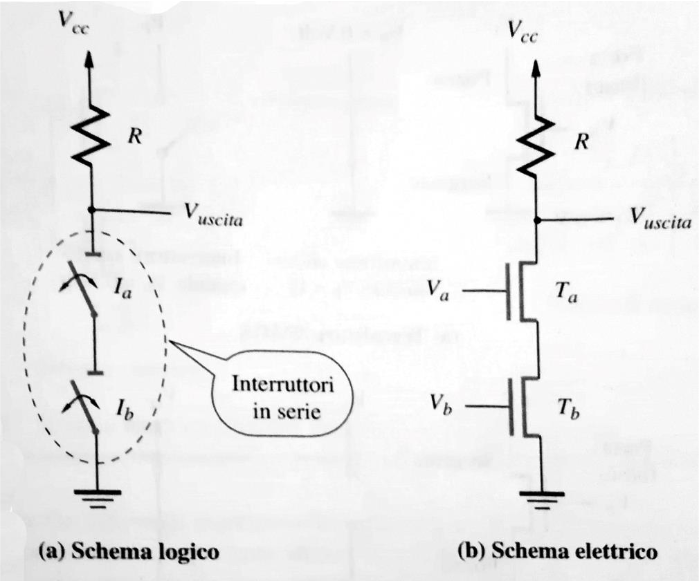
Tecnologia CMOS
- Combina NMOS e PMOS per migliorare efficienza e ridurre i consumi.
- Consumo di potenza solo durante la commutazione.
- Permette l’integrazione di miliardi di transistor su un chip.
- Offre alte frequenze di commutazione (nell’ordine dei GHz).
- Esempi:
- NOT CMOS:
- Un NMOS e un PMOS in serie.
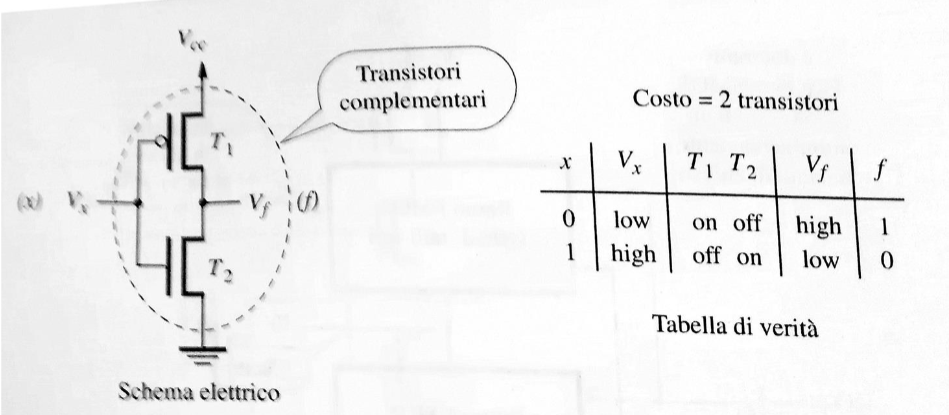
- Un NMOS e un PMOS in serie.
- NAND CMOS:
- Due NMOS in serie e due PMOS in parallelo.
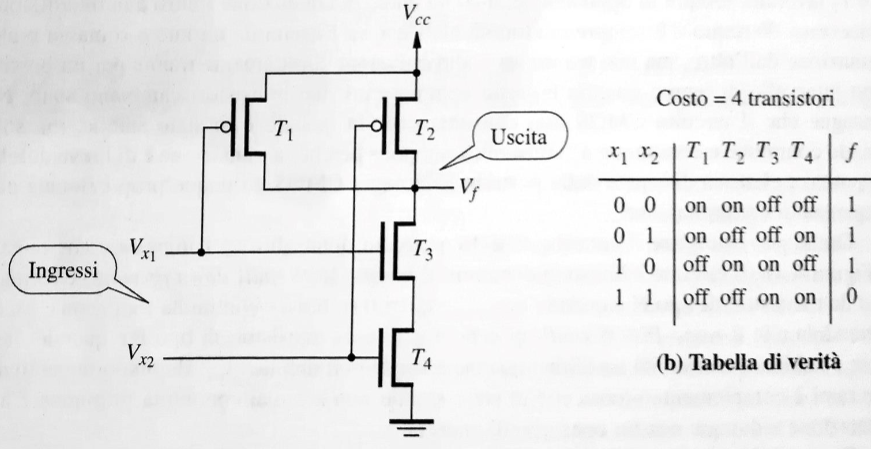
- Due NMOS in serie e due PMOS in parallelo.
- NOR CMOS:
- Due NMOS in parallelo e due PMOS in serie.
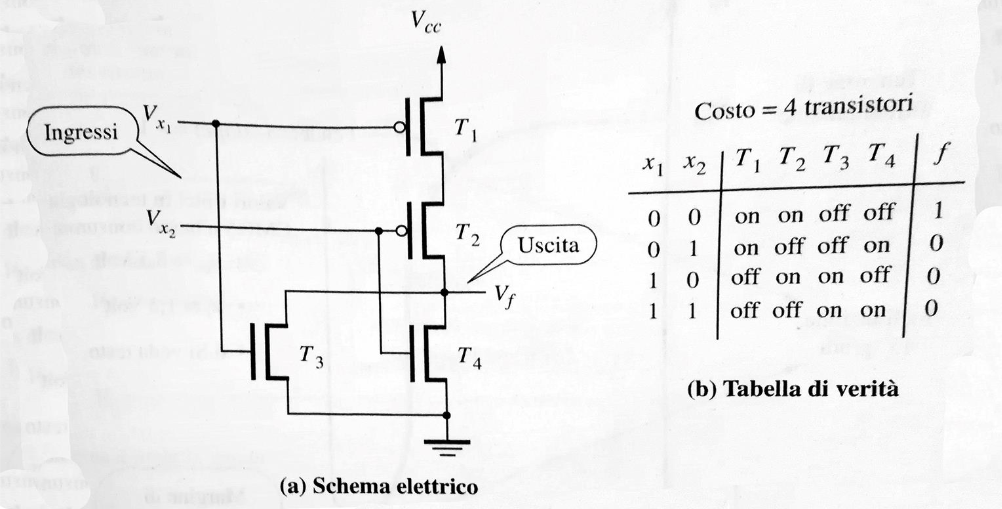
- Due NMOS in parallelo e due PMOS in serie.
- NOT CMOS:
Concetti avanzati nei circuiti logici
- Ritardi nei circuiti:
- Tempo di transizione: Cambio di stato del segnale.
- Ritardo di propagazione: Tempo necessario per aggiornare l’uscita.
- Percorso critico: Determina la frequenza massima di lavoro.
- Fan-in e Fan-out:
- Fan-in: Numero massimo di ingressi per una porta logica.
- Fan-out: Numero massimo di uscite che una porta può pilotare.
- Collegare più uscite a uno stesso ingresso può causare cortocircuiti o interferenze.
Circuiti integrati
- I circuiti integrati sono dispositivi in silicio che combinano componenti elettronici.
- Tipi di circuiti integrati:
- SSI: Poche porte logiche.
- MSI: Moduli funzionali (es. addizionatori).
- LSI: Piccoli processori come la ALU.
- VLSI: Processori potenti e memorie avanzate.
- Circuiti integrati possono essere:
- Analogici: Elaborano segnali continui.
- Digitali: Elaborano segnali discreti.
- Mixed: Combinano analogico e digitale.
Porta tri-state
Questo tipo di porta può assumere 3 stati:
- Acceso
- Spento
- Alta impendenza Quando la porta si trova in alta impedenza è come se fosse disconnessa, questa porta viene usata molto nei bus per permettere a più componenti di usare lo stesso bus ma senza influenzarsi tra di loro. Spiegazione correlata al bus
Decoder e Multiplexer
- Decoder: Converte un codice binario con ingressi in uscite. In pratica prende in input un segnale e lo decodifica in segnali di uscita leggibili anche da altre componenti.
- Multiplexer: è un circuito digitale che seleziona uno tra i diversi ingressi e lo invia in uscita, basandosi sui segnali di controllo che gli arrivano, ciò permette a più fonti di condividere la stessa linea di connessione.
13_Laboratorio
1. Sistemi di numerazione
Per contare noi usiamo un sistema posizionale in base 10, invece i nostri dispositivi elettronici usano un sistema posizionale in base 2.
Conversione da decimale a binario
- Sia il numero (in base 10) da convertire e in questo caso
- Si calcola la divisione intera e si mette da parte il resto della divisione
- Se si va al passo
- Se si riportano i vari RESTI da destra verso sinistra: essi rappresentano il numero convertito in base B.
 Lo stesso sistema può essere utilizzato per convertire un numero in base ottale(B=8) e anche esadecimale (B=16).
Lo stesso sistema può essere utilizzato per convertire un numero in base ottale(B=8) e anche esadecimale (B=16).
Numeri binari
I concetti on/off alla base dei nostri dispositivi possono essere rappresentati tramite i numeri binari:
- OFF = 0
- ON = 1 in generale un numero viene rappresentato tramite una stringa di bit, questi numeri binari possono essere rappresentati tramite 3 tecniche principali:
- Segno e valore assoluto: si commuta il bit di segno da 0 a 1, mentre gli altri bit restano invariati.
- Complemento a uno: si commuta qualsiasi bit da 0 a 1 e da 1 a 0
- Complemento a due: si aggiunge 1 al complemento a uno Queste 3 tecniche hanno in comune che il bit più a sinistra rappresenta il segno del numero:
- 0 se il numero è positivo
- 1 se il numero è negativo
Addizione e sottrazione di numeri in complemento a 2
Addizione: si applica il solito algoritmo di addizione
Sottrazione: si fa il complemento a 2 dei numeri che hanno il meno davanti e poi si calcola l’addizione algebrica
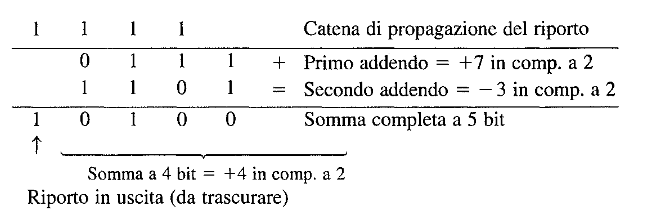
Estensione e riduzione
Accade spesso che i numeri vadano ridotti o estesi per adattarli a delle locazioni di memoria specifiche, per fare ciò seguiamo le seguenti regole:
- Estendere:
- Se aggiungiamo altri 0 a sinistra
- Se aggiungiamo altri 1 bit a sinistra
- Ridurre:
- Se togliere bit 0 da sinistra (smettere prima che emerge 1)
- Se togliere bit 1 da sinistra (smettere prima che emerge 1)
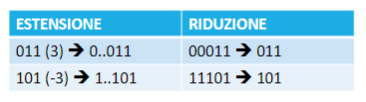
Overflow
Il risultato di addizione e sottrazione in complemento a due è corretto se è COMPRESO nell’intervallo in caso contrario si ha Overflow. Il trabocco si verifica se e solo se i due addendi hanno lo stesso segno, ma il bit di segno della somma risulta diverso dal bit di segno degli addendi. Esempio: +7+4 con n = 4 si ottiene 1011 (-5)
Numeri in virgola mobile
Un numero in virgola mobile può essere rappresentato usando:
- Un segno
- La mantissa
- Un esponente con segno in base 2
In base allo standard utilizzato abbiamo un numero di bit usati:
 per rappresentare i numeri in questo modo faccio così:
per rappresentare i numeri in questo modo faccio così:

Codice ASCII
Per rappresentare le lettere, i numeri e i simboli in generela viene utilizzato un alfabeto definito su 7 bit chiamato alfabeto ascii
2. Istruzioni macchina
| Istruzione | Sintassi | Descrizione |
|---|---|---|
| Load | R2, LOC | Legge i contenuti di una locazione di memoria il cui indirizzo è rappresentato simbolicamente dall’etichetta LOC e carica i contenuti nel registro R2. I contenuti originali della locazione LOC sono preservati mentre quelli del registro R2 sono sovrascritti. |
| Add | R4, R2, R3 | Somma i contenuti dei registri R2 e R3 e inserisce la loro somma nel registro R4. Gli operandi in R2 e R3 non sono alterati, ma il precedente valore in R4 è sovrascritto dalla somma. |
| Store | R4, LOC | Copia l’operando del registro R4 nella locazione di memoria LOC. I contenuti originali della locazione LOC sono sovrascritti mentre quelli del registro R4 sono preservati. |
| Move | R4, R3 | Carica il contenuto del registro R3 in R4. |
| Subtract | R4, R2, R3 | Sottrae i contenuti dei registri R2 e R3 e inserisce il risultato nel registro R4. |
Modi di indirizzamento
- Modo di registro: L’operando o il risultato è contenuto in un registro di processore, il cui nome (che è indirizzo) è dato nell’istruzione.
ES: ADD R4,R2,R3 - Modo assoluto: L’operando o il risultato è contenuto in una parola di memoria il cui indirizzo è dato nell’istruzione.
ES: LOAD R2,NUM1 - Modo immediato: L’operando è dato esplicitamente nell’istruzione.
ES: R4,R6,#200 - Modo indiretto: Il nome di un registro di processore contenente l’INDIRIZZO di memoria dell’operando o del risultato è dato nell’istruzione.
ES: Load R2, (R5)Il registro R5 agisce come puntatore - Modo con indice e spiazzamento: L’indirizzo effettivo di operando o risultato e ottenuto addizionando un valore costante (spiazzamento) al contenuto di un registro (indirizzo).
ES: LOAD R2,20(R5)
Istruzioni da usare su visual
| Istruzione | Descrizione |
|---|---|
LDR Ri, [Rj] | Carica nel registro Ri il contenuto della parola di memoria puntata da Rj. |
ADD Rd, Ri, Rj | Somma il contenuto di Ri e Rj e lo carica nel registro Rd. |
SUB Rd, Ri, Rj | Sottrae il contenuto di Rj da Ri e lo carica nel registro Rd. |
STR Ri, [Rj] | Salva nella parola di memoria puntata da Rj il contenuto di Ri. |
MOV Ri, Rj / MOV Ri, #Valore | Carica nel registro Ri il contenuto di Rj o il valore immediato. |
Direttive di assemblatore
Le direttive di assemblatore servono per dare informazioni utili all’assemblatore.
- EQU: associa il valore numerico nome (in visual: EQU)
- ORIGIN: indica l’indirizzo di partenza dove inserire le istruzioni
- RESERVE: indica all’assemblatore di riservare uno spazio di memoria espresso in byte (in visual: FILL)
- DATAWORD: Inizializza una word di memoria con il contenuto passato (in visual: DCD)
- END: indica all’assemblatore la fine del testo del programma sorgente (in visual: END)
Bit di esito
Il processore tiene traccia di alcune informazioni ausiliarie relative all’esito di svariate operazioni, che servono come condizioni per l’istruzione di salto. Tale informazioni sono espressi sotto forma di insiemi di bit detti bit di esito.
 Le istruzioni sottostanti aggiornano i bit di stato
Le istruzioni sottostanti aggiornano i bit di stato
| Istruzione | Descrizione |
|---|---|
ADDS Rd, Ri, Rj | Somma il contenuto di Ri e Rj e lo carica nel registro Rd (aggiorna i bit di stato NZCV). |
SUBS Rd, Ri, Rj | Sottrae il contenuto di Rj da Ri e lo carica nel registro Rd (aggiorna i bit di stato NZCV). |
CMP Ri, Rj | Sottrae Rj da Ri e aggiorna i bit di stato. Il risultato viene scartato. |
CMN Ri, Rj | Somma Ri e Rj e aggiorna i bit di stato. Il risultato viene scartato. |
Istruzione di salto condizionato
Branch_if_ condizione destinazione_salto
nel caso la condizione sia vera il programma salta alla destinazione_salto espressa come locazione di memoria contenente l’istruzione da eseguire nel caso la condizione sia vera.
 Le lettere usate sono le lettere dei corrispondenti bit di esito.
Le lettere usate sono le lettere dei corrispondenti bit di esito.
3. Algebra Booleana
Operatori logici
L’algebra booleana è un sistema algebrico in cui ogni variabile può assumere solo 2 valori ( e ) le principali operazioni definite sono:
- OR: che si denota con ”+” o “V” ed è una funzione che vale 1 se almeno uno dei suoi ingressi è 1
- AND: che si denota con "" o ”˄” ed è un funzione che vale 1 se entrambi i suoi ingressi valgono 1
- NOT: che si denota con “ˉ” o ”¬” ed è una funzione che inverte il valore del suo ingresso
- XOR: che si denota con "" è una funzione che vale 1 solo se il numero di uno nei suoi ingressi è dispari
 Abbiamo anche altre proprietà importanti che riguardano questi operatori logici:
Abbiamo anche altre proprietà importanti che riguardano questi operatori logici:
 Ricordiamo anche il teorema di De Morgan che ci dice:
Ricordiamo anche il teorema di De Morgan che ci dice:
Prima forma canonica (somma di prodotti)
Si crea la tabella di verità di un’espressione logica e poi si seguono i seguenti step:
- Si individuano i casi in cui il risultato è pari a 1
- Per ogni caso si costruisce un prodotto delle variabili, ogni variabile è
- se uguale a 1 la scriviamo direttamente
- se uguale a 0 la scriviamo negata
- Si sommano tra loro i prodotti ottenuti
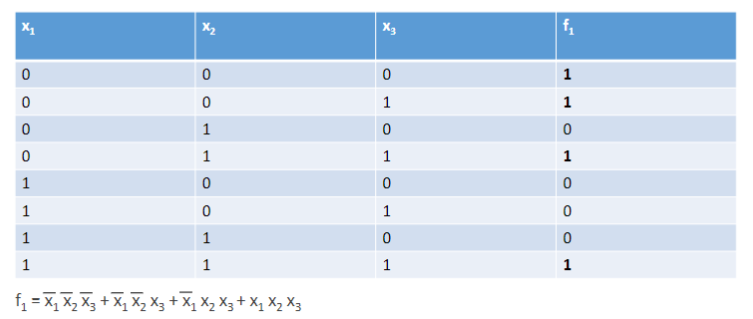
Seconda forma canonica (prodotto di somme)
Si crea la tabella di verità di un’espressione logica e poi si seguono i seguenti step:
- Si individuano tutti i casi in cui il risultato è pari a 0
- Per ogni caso, si costruisce una somma delle variabili, ogni variabile è:
- se uguale a 0 la scriviamo direttamente
- se uguale a 1 la scriviamo negata
- Moltiplichiamo le somme ottenute.
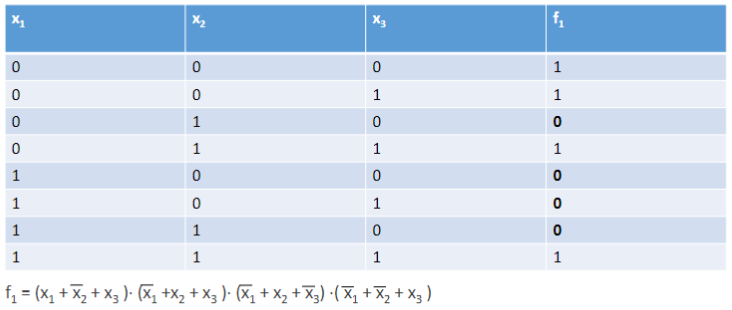
Forma minima
Due espressioni logiche si dicono equivalenti se hanno la medesima tabella di verità, un’espressione di dice in forma minima quando non esiste un’altra espressione equivalente ma di costo inferiore, il costo di un’espressione si calcola contando il numero di volte in cui le variabili compaiono, per noi è molto importante ridurre un’espressione perché un’espressione minima produrrà un circuito logico più semplice.
Esempio
costo 6 costo 2
Di seguito un’esempio di minimizzazione
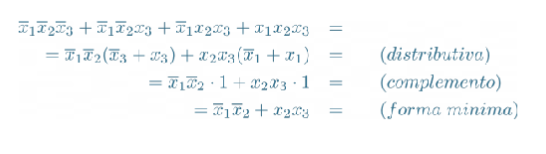
Mappe di Karnaugh
Le mappe di Karnaugh sono un metodo di tipo geometrico che permettono di ricavare l’espressione logica di costo minimo data una funzione
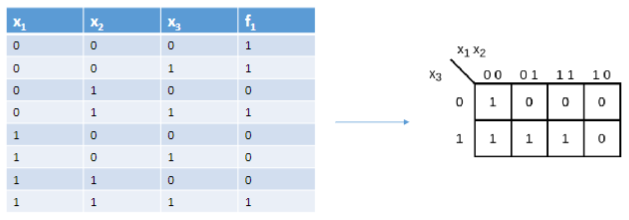 Come si usano:
Come si usano:
- Trasformare la tavola di verità in una mappa di Karnaugh
- Raggruppare le caselle di valore 1 adiacenti orizzontalmente o verticalmente
- Ogni gruppo rappresenta il prodotto delle sue variabili con lo stesso valore (forma diretta se 1 e negata se 0). Identificare quali variabili non contribuiscono ed eliminarle nella forma analitica.
- Somma dei gruppi creati
Condizione di indifferenza: spesso accade che una funzione logica non sia definita su tutte le combinazioni di valori delle sue variabili, nella tabella di verità sono indicate con il simbolo “X” e quindi anche nella mappa di karnaugh corrispondente avranno un x, il loro valore va scelto in modo arbitrario cercando di creare una semplificazione a costo minimo.
Circuiti logici
Le operazioni logiche possono essere realizzate da semplici circuiti elettronici chiamati porte. Collegando varie porte tra di loro si possono rappresentare le espressioni logiche. Questi sono i simboli principali.
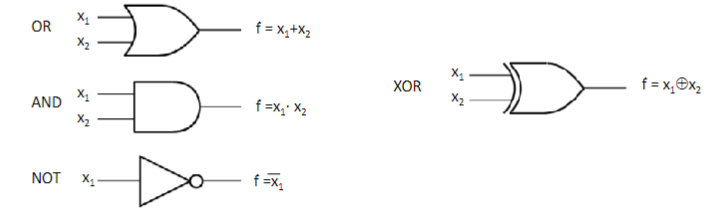 Altre porte molto importanti sono le porte NAND e NOR, si denota tramite gli operatori a due argomenti ”↑” o ”↓” rispettivamente
Altre porte molto importanti sono le porte NAND e NOR, si denota tramite gli operatori a due argomenti ”↑” o ”↓” rispettivamente
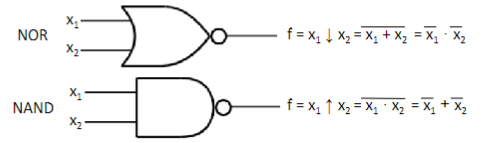
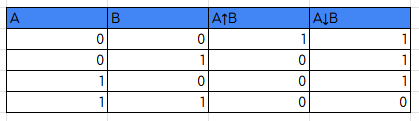 Queste 2 porte godono della proprietà commutativa ma non di quella associativa e appunto per questo non si possono creare degli alberi di porte. Grazie alle leggi di De Morgan e alla legge di involuzione possiamo passare da una SOP ad una rete di NAND
Queste 2 porte godono della proprietà commutativa ma non di quella associativa e appunto per questo non si possono creare degli alberi di porte. Grazie alle leggi di De Morgan e alla legge di involuzione possiamo passare da una SOP ad una rete di NAND
4. La pila
La pila consiste in una lista di elementi alla quale però si può lavorare solo agendo sulla cima della pila. É possibile eseguire solo 2 operazioni:
- PUSH: aggiungiamo un elemento in cima
Subtract SP, SP,#4 ;diminuire l’indirizzo contenuto in SP di una parola per puntare alla nuova cima
Store Rj, (SP) ; scrivere il valore richiesto nella parola puntata da SP
- POP: togliere un elemento dalla cima
Load Rj, (SP) ;copiare il valore contenuto nella locazione di memoria puntata da SP in un registro del processore
Add SP, SP,#4 ;aumentare l’indirizzo contenuto in SP di una parola per puntare alla nuova cima
La pila in Visual
 Questi 2 comandi vanno a salvare nella pila la lista dei registri che inseriamo, l’ordine con la quale vengono inseriti si basa sul codice passato, i codici disponibili sono:
Questi 2 comandi vanno a salvare nella pila la lista dei registri che inseriamo, l’ordine con la quale vengono inseriti si basa sul codice passato, i codici disponibili sono:
Esempio
I valori nei nostri registri sono:
- R0 = 18
- R1 = 20
- R2 = 22
- R3 = 24
- R4 = 26
- R5 = 28 Questo succede se uso STM con i vari codici:
Questo succede se uso LDM:
Area di attivazione in pila
Il blocco di programma riservato ai sottoprogrammi è anche essa una pila ed è chiamato Stack Frame, il Frame Pointer è un registro che punta allo stack frame del sottoprogramma in esecuzione.
Gestione dei sottoprogrammi
Un sottoprogramma è una lista di istruzioni che eseguono un compito specifico e che possono essere richiamate in un qualsiasi punto del programma.
- Chiamata a sottoprogramma: viene fatta attraverso l’istruzione
call INDIRIZZO, l’operazione di chiamata esegue 2 step:- Salva il contenuto del registro PC nel Link Register;
- Salta all’indirizzo di destinazione indicato nell’istruzione di chiamata
- Rientro da sottoprogramma: viene fatta attraverso l’istruzione
RETURN, quello che fa questa istruzione è salvare il contenuto del link register nel registro PC In Visual facciamo così: Il passaggio di parametri ai sottoprogrammi può essere fatto attraverso i registri o usando la pila.
Il passaggio di parametri ai sottoprogrammi può essere fatto attraverso i registri o usando la pila.

5. Shifting e comandi vari



6. Circuiti integrati
Transistor
Nei circuiti elettronici, per rappresentare i valori 0 e 1 delle variabili binarie si usano i valori di tensione elettrica, si stabilisce una tensione di soglia dove tutti i valori di tensione rappresentano un 1 mentre quelli inferiori rappresentano uno 0, i valori vicini alla soglia sono ambigui e quindi per evitare incertezze nasce la banda vietata dove i valori non vengono presi in considerazione.
 I transistor sono delle componenti elettroniche che svolgono il compito di interruttori, in specifico i transistor MOS (transistore a metallo-ossido semiconduttore) sono quelli più utilizzati nei nostri dispositivi, questo tipo di transistor hanno 3 collegamenti: Base, Pozzo e Sorgente, a seconda della tensione in ingresso nella Base il transistore collegherà o meno la sorgente al pozzo, se il transistor sta conducendo allora la tensione in entrata è uguale alla tensione in uscita, esistono 2 tipi di transistor MOS:
I transistor sono delle componenti elettroniche che svolgono il compito di interruttori, in specifico i transistor MOS (transistore a metallo-ossido semiconduttore) sono quelli più utilizzati nei nostri dispositivi, questo tipo di transistor hanno 3 collegamenti: Base, Pozzo e Sorgente, a seconda della tensione in ingresso nella Base il transistore collegherà o meno la sorgente al pozzo, se il transistor sta conducendo allora la tensione in entrata è uguale alla tensione in uscita, esistono 2 tipi di transistor MOS:
- NMOS:
- il transistor è in conduzione (vale 1) se
- il transistor è in interdizione (vale 0) se = 0
- PMOS:
- il transistor è in conduzione (vale 1) se
- il transistor è in interdizione (vale 0) se = Attraverso questi 2 transistor possiamo costruire le seguenti porte logiche:
- NOT: si ottiene una porta NOT con un transistor NMOS collegando la sorgente alla massa e il pozzo all’alimentazione tramite una resistenza, per una tensione di ingresso di “1” in uscita avremo una tensione di “0” e viceversa.
- NOR: si ottiene collegando due transistor NMOS in parallelo, solo se entrambi i transistori sono in interdizione la tensione in uscita sarà uno altrimenti sarà sempre 0
- NAND: collegando due transistor NMOS in serie si ottiene una porta NAND
- AND: collegando in serie una NAND e NOT
- OR: collegando in serie una NOR e NOT
L’unico problema dei transistor NMOS è che consumano tanta corrente, cosi nascono i transistor CMOS che hanno un consumo di potenza ridotto e soprattutto dimensioni ridotte infatti da quando sono nati abbiamo componenti con miliardi di transistor all’interno
Definizioni nelle porte logiche
- il tempo di transizione in un circuito è il tempo impiegato da un segnale per transitare di livello
- il ritardo di propagazione è il tempo che ci mette il nostro circuito ad adattarsi ai nuovi valor in input
- la frequenza di lavoro è il numero di volte che esso commuta in un determinato tempo.
- Fan-in è il numero di ingressi di una porta logica
- Fan-out è il numero di uscite di una porta logica
TIP
Tipicamente il fan-in e fan-out si limita a meno di 10 per porta perché un numero più elevato inciderebbe sul ritardo di propagazione
Circuiti integrati
Decodificatore: un blocco funzionale in grado di decodificare un codice binario in ingresso Multiplatore: un blocco funzionale dotato di molteplici ingressi di selezione e altrettanti ingressi dato e di una sola uscita, quello che fa questo blocco funzionale è selezionare uno degli ingressi dato basandosi sui segnalo che arrivano negli ingressi selezione e inviarlo in uscita
Reti sequenziali
Le reti che riescono a memorizzare informazioni sono chiamate reti sequenziali, queste reti logiche sono basati su dei cicli, una rete sequenziale in grado di memorizzare dei bit viene anche detta bistabile ne esistono di 3 tipi:
- Bistabile asincrono: Sono privi di un segnale di sincronismo e modificano il loro stato in seguito al cambiamento degli ingressi.
- Bistabile sincrono: Sono sensibili ad un segnale di controllo e i cambiamenti di stato avvengono solo in corrispondenza di un impulso del segnale di controllo
- Bistabile di tipo D: Memorizza un bit unificando gli ingressi S e R in un unico ingresso D. Quando il segnale di clock è alto (), l’uscita segue il valore di D; quando è basso (), lo stato rimane invariato.