Grafi
Proprietà dei grafi
Definizione e proprietà
Un grafo è definito come con
- insieme di vertici
- insieme di archi
Se allora il grafo si dice non orientato Se allora il grafo si dice orientato
Cammino
Dato un percorso è un cammino se:
- (tutti gli elementi devono essere vertici del grafo)
- (ogni coppia di nodi consecutivi deve essere collegata da un arco)
Se nel cammino abbiamo che allora c’è un ciclo
Cammino semplice
I nodi devono essere tutti diversi, quindi è un cammino senza cicli
Grafo aciclico
Un grafo è detto aciclico quando non ha cicli Se un grafo ha un ciclo allora ne ha infiniti
Grafo pesato
Un grafo è pesato se ad ogni arco diamo un peso usando la funzione peso: quindi il costo totale di un eventuale cammino è: la maggior parte dei grafi pesati ha valori positivi negli archi
Ordinamento topologico
Un ordinamento topologico è un ordinamento lineare dei nodi in modo che valga la relazione:
Ovviamente se c’è un ciclo questa caratteristica non può essere rispettata
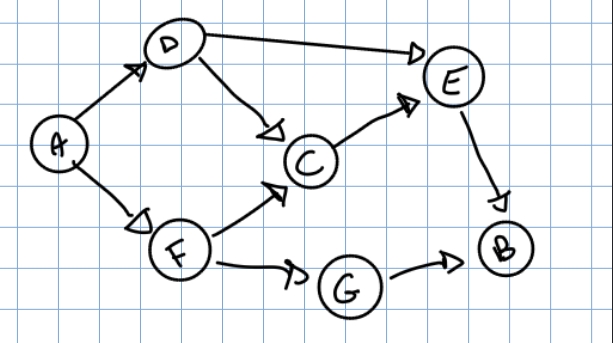 Un eventuale ordinamento di questo grafo è:
Un eventuale ordinamento di questo grafo è:
Componente connessa e fortemente connessa
Componente connessa: dato un grafo diciamo che due vertici sono connessi se esiste un cammino da a
Componente fortemente connessa: dato un grafo orientato , diciamo che due vertici sono fortemente connessi se esiste sia un cammino da a che un cammino da ad .
Rappresentazioni dei grafi
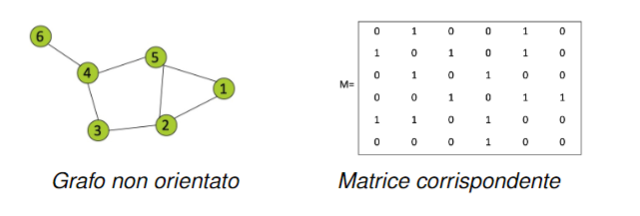
Tramite matrice di adiacenza: Dato un grafo con . La matrice detta matrice di adiacenza del grafo ha dimensione dove è il numero di vertici, ed è formata in questo modo:
- se i vertici e sono connessi da un arco
- se i vertici e non sono connessi da un arco
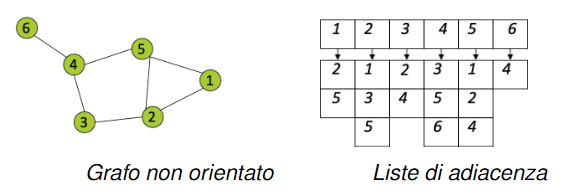
 Tramite lista di adiacenza: un grafo può essere rappresentato pure con le liste di adiacenza, ovvero un array i cui elementi sono i nodi e per ogni nodo viene associato un altro array con la lista dei nodi collegati ad esso.
Tramite lista di adiacenza: un grafo può essere rappresentato pure con le liste di adiacenza, ovvero un array i cui elementi sono i nodi e per ogni nodo viene associato un altro array con la lista dei nodi collegati ad esso.
BFS
Definizione
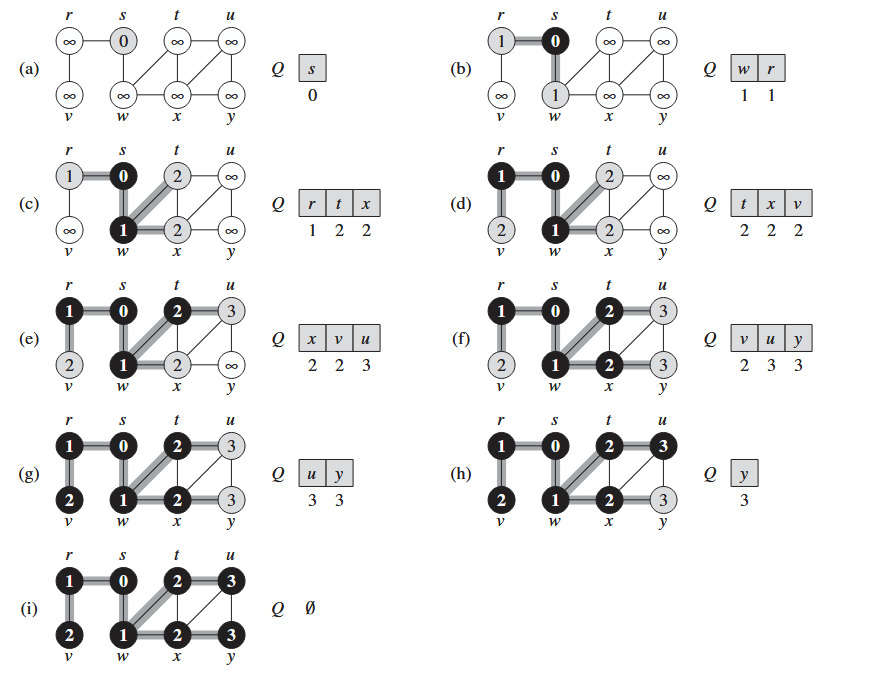
La Breadth-First-Search ovvero ricerca in ampiezza è una algoritmo di ricerca nei grafi. Dato un grafo e un vertice distinto detto sorgente, la visita in ampiezza ispeziona sistematicamente gli archi di per “scoprire” tutti i vertici che sono raggiungibili da .
Implementazione
Per tenere traccia del lavoro svolto, la visita in ampiezza colora i vertici di:
- bianco: nodo non ancora visitato
- grigio: nodo scoperto ma non ancora visitato
- nero: nodo visitato
All’inizio tutti i nodi sono bianchi, si sceglie un nodo iniziale (la sorgente ) e da li:
- Aggiungiamo ad una coda tutti i nodi adiacenti a da (colorandoli di grigio)
- Per ogni nodo aggiunto alla coda calcoliamo la sua distanza da
BFS(V, s)
Foreach v in V //for di inizializzazione
color[v] = White
d[v] = +infinito
d[s] = 0; // la distanza della sorgente da stessa è 0
Q = { } // inizializzazione della coda come vuota
Q.enqueue(s)
While Q != {} DO
v = Q.dequeue(Q)
foreach u in ADJ(v) //scorriamo tutti i nodi adiacenti a v
if(color[u] == W)
d[u] = d[v]+1
color[u] = Gray
Q.enqueue(u)
color[v] = Black
La ricerca oltre a calcolare la distanza di ogni nodo dalla sorgente crea un albero, detto albero BFS dove il cammino che va da ad un generico corrisponde al cammino minimo da a
DFS
Definizione
Un altro algoritmo di ispezione dei grafi è il depth first search, a differenza del BFS dove la ricerca era in ampiezza qui abbiamo una ricerca in profondità, vedremo successivamente che questo algoritmo ci permette di trarre dal nostro grafo diverse informazioni utili come:
- la composizione delle componenti connesse
- un ordinamento topologico tutto questo lo facciamo grazie all’albero DFS che crea durante la ricerca. Vedremo diverse implementazioni
Premesse comuni alle implementazioni fatte
I nodi sono colorati in modo diverso in base allo stato in cui si trovano:
- bianco: nodo non ancora visitato
- grigio: nodo scoperto ma non visitato
- nero: nodo visitato
Nella nostra implementazione teniamo traccia del tempo di inizio e fine visita di un nodo usando due array e , con e indichiamo rispettivamente il tempo di inizio e fine di ( sarà una variabile che scandirà il tempo di esecuzione)
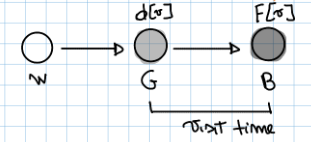 Avremo anche altri due array:
Avremo anche altri due array: - : che ci indicherà il colore del nodo v
- : che ci indicherà il padre di quel nodo nel albero DFS Inoltre useremo una funzione che ritorna una lista dei nodi adiacenti a
Prima implementazione
DFS-visit(v):
color[v] = gray;
foreach u in adj(v)
if color[u] = white
π[u] = v
DFS-visit(u)
color[v] = black
DFS(G,s):
foreach v in V DO:
color[v] = white
π[] = null
DFS-visit(s);
Questa è l’implementazione più grezza, infatti ci potrebbero essere dei nodi non visitati, ad esempio quelli non collegati a nulla. Da queste problematiche nasce la seconda implementazione.
Seconda implementazione
In questa implementazione aggiungiamo un for che scorre la lista dei nodi, in modo che qualsiasi nodo verrà sicuramente visitato, il fatto che ogni nodo può essere una ipotetica sorgente potrebbe creare più alberi DFS ovvero una foresta DFS
DFS-visit(v):
color[v] = gray;
foreach u in adj(v)
if color[u] = white
π[u] = v
DFS-visit(u)
color[v] = black
DFS(G,s):
foreach v in V DO:
color[v] = white
π[] = null
foreach v in V DO:
if color[v] = white:
DFS-visit(s);
Questa implementazione è perfetta, ma non raccoglie nessuna informazione sul nostro grafo, da qui nasce la necessità di introdurre e per scandire il tempo, usati nella terza implementazione
Terza implementazione
DFS-visit(v):
d[v] = T
T = T+1
color[v] = gray;
foreach u in adj(v)
if color[u] = white
π[u] = v
DFS-visit(u)
color[v] = black
F[v] = t
t = t+1
DFS(G,s):
foreach v in V DO:
color[v] = white
π[] = null
foreach v in V DO:
if color[v] = white:
DFS-visit(s);
Alla fine avremo alla fine di questo algoritmo negli array ed il tempo di inizio e fine, molto utile nell’utilizzo della DFS per scopi terzi. Di seguito un grafo con le informazioni ottenute dopo una DFS:
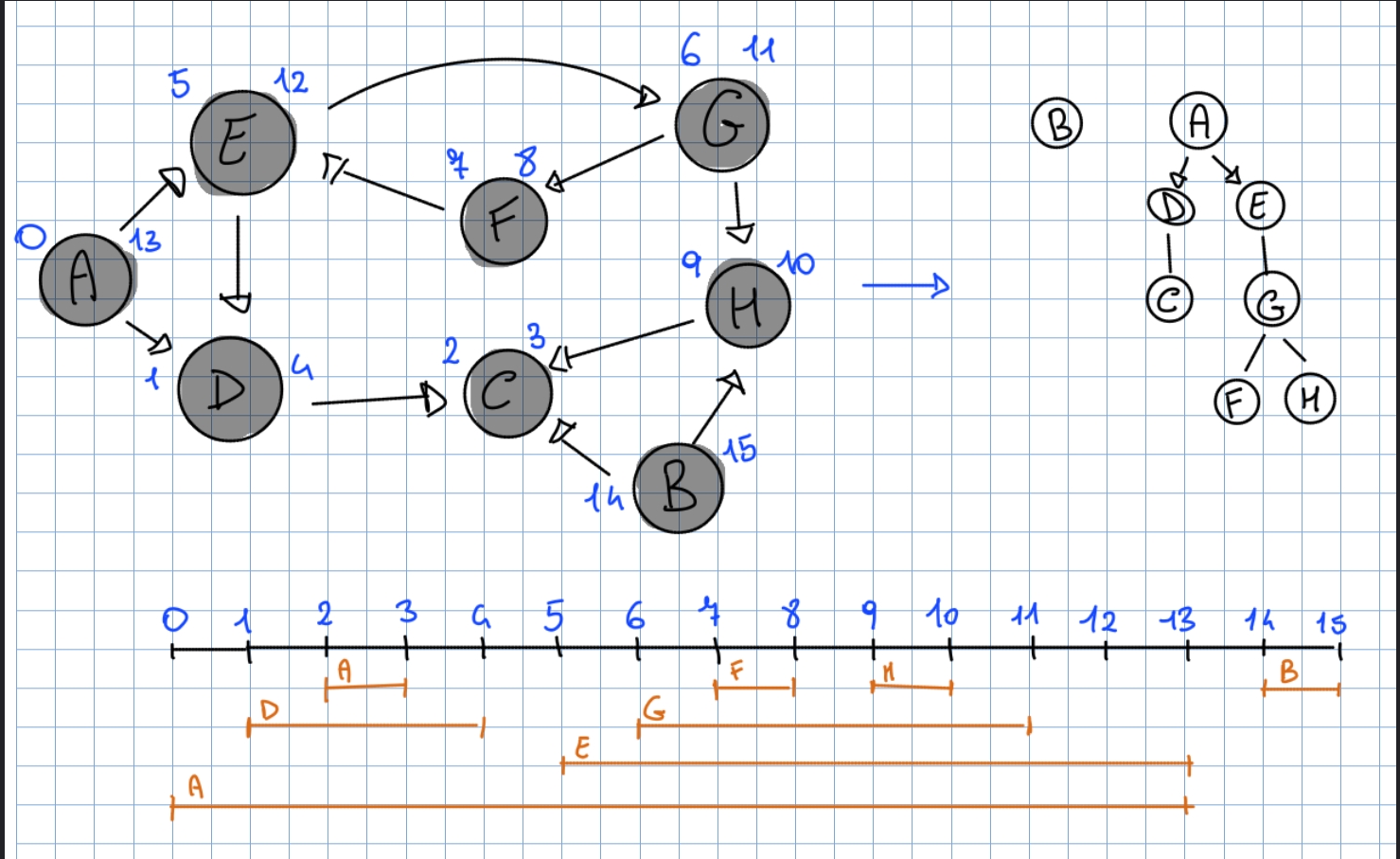
Etichette degli archi
Nel nostro grafo etichettiamo gli archi in base al ruolo che hanno durante l’esplorazione del grafo, e sono:
- T archi consecutivi: sono gli archi usati dalla DFS per scoprire nuovi nodi
- I archi all’indietro: collegano un nodo a un suo antenato nell’albero DFS
- F archi in avanti: collegano un nodo al suo discendente
- C archi trasversali: collegano nodi che non hanno relazione antenato-discendente
Per cosa usiamo la DFS
Ordinamento topologico: dato il tempo di inizio e fine visita di ogni vertice del grafo otteniamo un ordinamento topologico valido se mettiamo i vertici in ordine rispetto al tempo di fine visita:
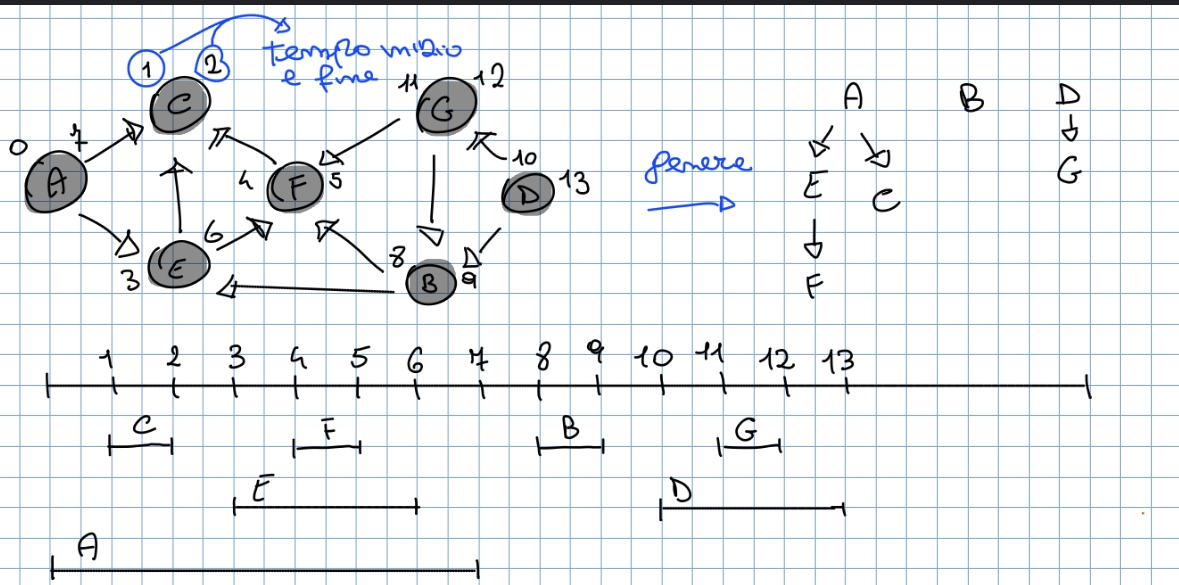 Dai tempi di fine visita otteniamo un ordinamento topologico:
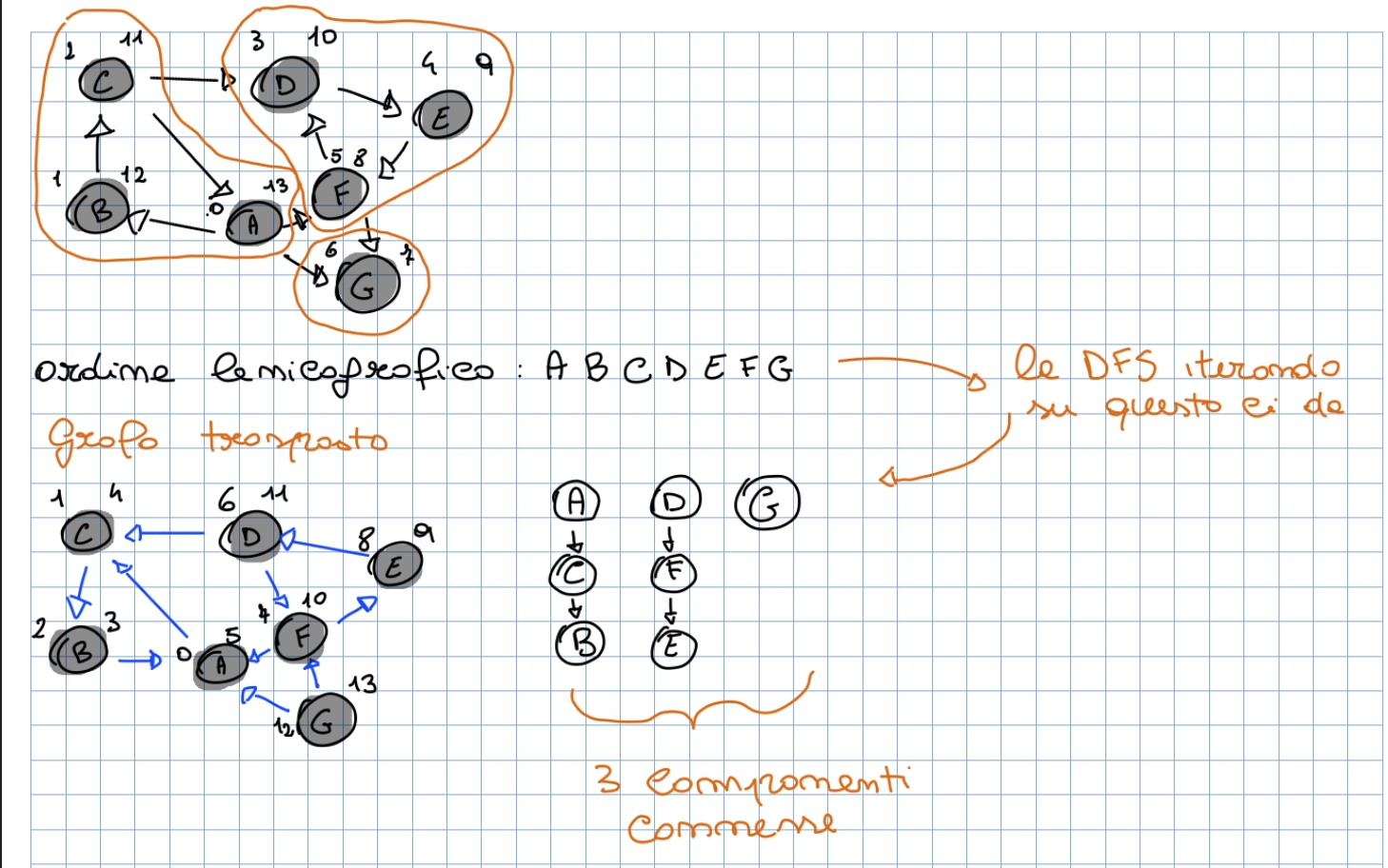
Identificazione delle componenti connesse: per identificare le componenti connesse di un grafo facciamo uso della DFS nel seguente modo:
Dai tempi di fine visita otteniamo un ordinamento topologico:
Identificazione delle componenti connesse: per identificare le componenti connesse di un grafo facciamo uso della DFS nel seguente modo:
- Faccio una DFS e metto in ordine rispetto al tempo di inizio visita
- Creo il grafo trasposto di quello dato in input (inverto le direzioni di tutti gli archi)
- Faccio la DFS sul grafo trasposto usando nel foreach principale la lista di nodi definita nel punto 1
Otteniamo una foresta di alberi DFS, tanti alberi quanti sono le componenti connesse. Di seguito un esempio:
Ricerca dei cammini minimi
Introduzione
Definizioni
In un problema dei cammini minimi sono dati:
- un grafo orientato pesato
- funzione peso che associa agli archi dei pesi Il peso di un cammino è la somma dei pesi degli archi che lo compongono: il peso di un cammino minimo da a è definito in questo modo:
Un cammino minimo è definito come un cammino qualsiasi con peso
Varianti di questo problema
Esistono 4 varianti del problema dei cammini minimi:
- Problema dei cammini minimi da sorgente unica(single source): dato un grafo vogliamo trovare un cammino minimo che va da un dato vertice sorgente a ciascun vertice
- Problema dei cammini minimi con destinazione unica(single destination): trovare un cammino minimo da ciascun vertice a un dato vertice destinazione. (Invertendo la direzione di ciascun argo nel grafo lo possiamo ricondurre la primo caso)
- Problema del cammino minimo per una coppia di vertici(single pair): trovare un cammino minimo da a , è una variante del primo problema.
- Problema dei cammini minimi fra tutte le coppie di vertici(all-pairs): trovare un cammino minimo da a per ogni coppia di vertici. Di seguito affronteremo il primo e il quarto.
Proprietà dei cammini minimi
Sottostruttura ottima
Teorema: Dati
- un grafo orientato
- la funzione peso
- sia un cammino minimo dal vertice al per qualsiasi e tali che sia un sotto-cammino di dal vertice al vertice allora è un cammino minimo da a Dimostrazione: Se scomponiamo il cammino in abbiamo . Supponiamo adesso che ci sia un cammino da a con peso . Allora è un cammino da a il cui peso è minore di che contraddice l’ipotesi che sia un cammino minimo da a
Archi di peso negativo e cicli
All’interno del nostro grafo potrebbero essere contenuti dei cammini di peso negativo, o anche dei cicli:
- Quando non sono presenti dei cicli di peso complessivo negativo raggiungibili è sempre possibile definire
- Quando sono presenti dei cicli di peso complessivo negativo non sarà possibile individuare di in quanto sarà sempre possibile diminuirlo effettuando un numero indefinito di passi all’interno del ciclo. In tal caso diremo che
Rilassamento dei cammini minimi
Il processo di rilassamento di un arco consiste nel verificare se passando per , è possibile migliorare il cammino minimo per da precedentemente trovato. Nelle nostre implementazioni avremo un array dove è peso del cammino da ad , con ogni passo di rilassamento possiamo ridurre questo valore.
RELAX(u,v,w):
if(d[v]>d[u]+w(u,v))
d[v] = d[u]+w(u,v)
π[v] = u
Alla creazione del nostro grafo tutti i valori del nostro array vengono inizializzati a .
Proprietà dei cammini minimi
- Disuguaglianza triangolare Per qualsiasi arco , si ha .
- Proprietà del limite superiore Per tutti i vertici , si ha sempre e, una volta che il limite superiore assume il valore , esso non cambia più.
- Proprietà dell’assenza di un cammino Se non c’è un cammino da a , allora si ha sempre .
- Proprietà della convergenza Se è un cammino minimo in per qualche e se in un istante qualsiasi prima del rilassamento dell’arco , allora in tutti gli istanti successivi.
- Proprietà del rilassamento del cammino Se è un cammino minimo da a e gli archi di vengono rilassati nell’ordine , allora . Questa proprietà è soddisfatta indipendentemente da altri passi di rilassamento effettuati.
- Proprietà del sotto grafo dei predecessori Una volta che per ogni , il sotto grafo dei predecessori è un albero di cammini minimi radicato in .
Single-Source Shortest Path in un DAG
Generic SSSP
Di seguito vediamo il primo algoritmo per la ricerca di un cammino minimo ovvero il Single-Source Shortest Path che risolve il primo problema dei cammini minimi.
Generic-SSSP(G,s)
d = new array(len(V))
foreach v in V do
d[v] = +infinito
d[s] = 0
while esiste (u, v) in E tale che d[u] + w(u, v) < d[v]:
RELAX(u, v)
return d
SSSP in un grafo orientato aciclico (DAG)
Rilassando gli archi di un dag (Directed Acyclic Graph) pesato secondo un ordine topologico dei suoi vertici è possibile calcolare i cammini minimi da una sorgente unica nel tempo . L’algoritmo inizia ordinando topologicamente il dag, se esiste un cammino dal vertice al vertice , allora precede nell’ordine topologico. Effettuiamo un passaggio sui vertici secondo l’ordine topologico. Durante l’elaborazione vengono rilassati tutti gli archi che escono dal vertice
DAG-SHORTEST-PATHS(G, w, s)
U = getTopologicalOrder(G);
foreach u in U:
foreach v in G.Adj[u]
RELAX(u, v, w)
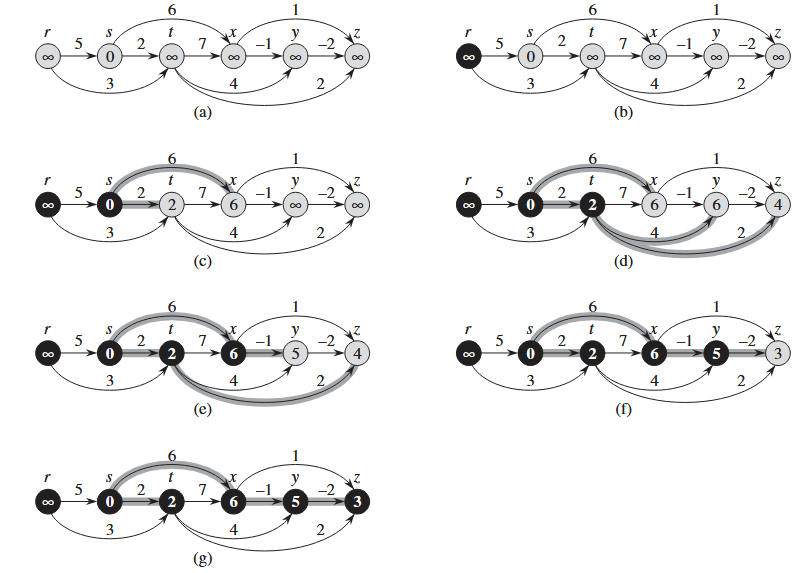
Algoritmo di Bellam-Ford
Definizione
Questo algoritmo si basa su un cavillo logico molto semplice, visto che non so quali archi rilassare li rilasso sempre tutti. Li rilasso volte dove è la lunghezza del cammino più lungo (ovvero il numero di nodi), dopo aver fatto rilassamenti degli archi sono sicuro che anche il cammino più lungo sarà rilassato. Questo algoritmo a differenza di tutti gli altri è in grado di capire se l’output che sta ritornando è valido, aggiungendo infatti un rilassamento ulteriore dopo le passate verifichiamo se il nostro grafo contiene dei cicli negativi.
Implementazione
Bellman-Ford(G, s, w)
// 1. Inizializzazione
d = new Array(len(V))
for each v ∈ V do
d[v] = +∞
π[v] = NIL
d[s] = 0
// 2. Rilassamento iterativo degli archi
for i ← 1 to |V|-1 do
for each (u, v) ∈ E do
relax(u, v, w)
// 3. Controllo dei cicli di peso negativo
for each (u, v) ∈ E do
if (d[v] > d[u] + w(u, v)) then
return false
return dLa parte iniziale viene utilizzata per inizializzare gli array e che rappresentano:
- rappresenta la distanza di da
- è il nodo padre di nell’albero dei cammini minimi
Il punto tre verifica la validità del risultato, stiamo controllando se si possono effettuare altri relax, se questo succede vuol dire che il nostro grafo contiene dei cicli negativi, e quindi la ricerca di un cammino minimo non può esistere
Esempio
Di seguito un esempio di come dovremmo implementare questo algoritmo in sede di esame
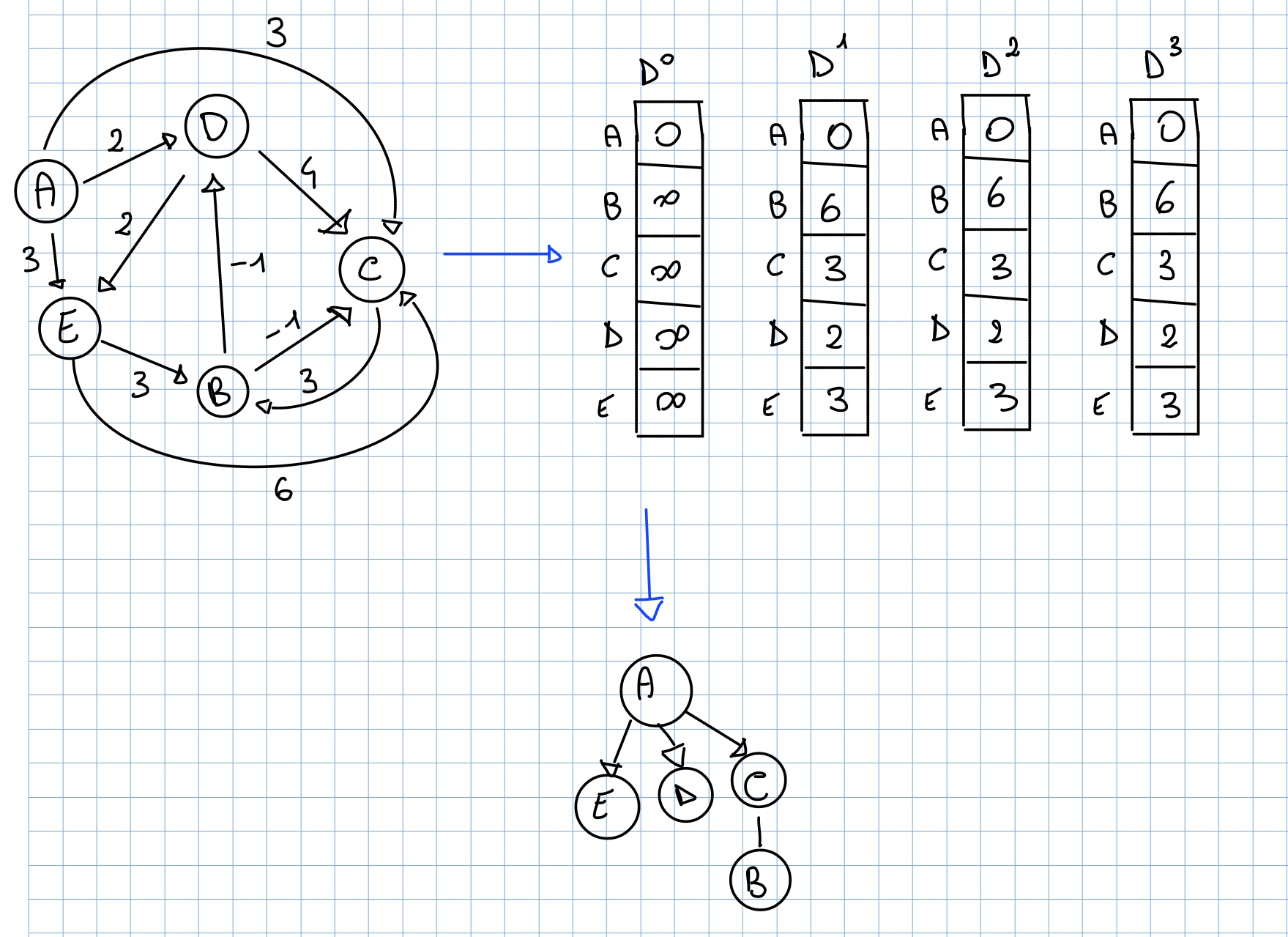
Complessità
La complessità di questo algoritmo cambia in base al tipo di implementazione utilizzata per rappresentare i grafi:
- Lista di adiacenza:
- Matrice di adiacenza:
Algoritmo di Dijkstra
Definizione
Per poter funzionare questo algoritmo ha bisogno che tutti i pesi nel grafo siano positivi. Questo algoritmo si basa sull’idea che se troviamo un nodo convergente (quindi completamente rilassato) possiamo rilassare i tutti i suoi archi uscenti. Dati due insiemi:
- insieme dei nodi in convergenza
- insieme dei nodi non in convergenza Un nodo convergente sarà sicuramente il nodo con il valore più piccolo nell’insieme dei nodi non in convergenza questo poiché tutti i pesi degli archi sono positivi (o nulli), non esiste alcun cammino alternativo che, passando per altri nodi non ancora visitati, possa “tornare indietro” e ridurre ulteriormente la distanza di quel nodo specifico.
Implementazione
Dijkstra(G, s, w)
d = new Array(len(V))
for each v ∈ V do
d[v] = +∞
π[v] = NIL
d[s] = 0
Q ← build-min-heap(V)
while Q ≠ ∅ do
v ← extract-min(Q)
foreach u ∈ ADJ(v)
if d[u] > d[v] + w(v, u) then
decrease-key(Q, u, d[v] + w(v, u))
La parte iniziale viene utilizzata per inizializzare gli array e che rappresentano:
- rappresenta la distanza di da
- è il nodo padre di nell’albero dei cammini minimi Quello che fa il resto del algoritmo consiste nel creare un min-heap rispetto al valore che hanno i nodi in e poi rilassare tutti gli archi uscenti dai minimi della coda fino a quando la coda non è vuota
Esempio
Di seguito un esempio di come dovremmo implementare questo algoritmo in sede di esame
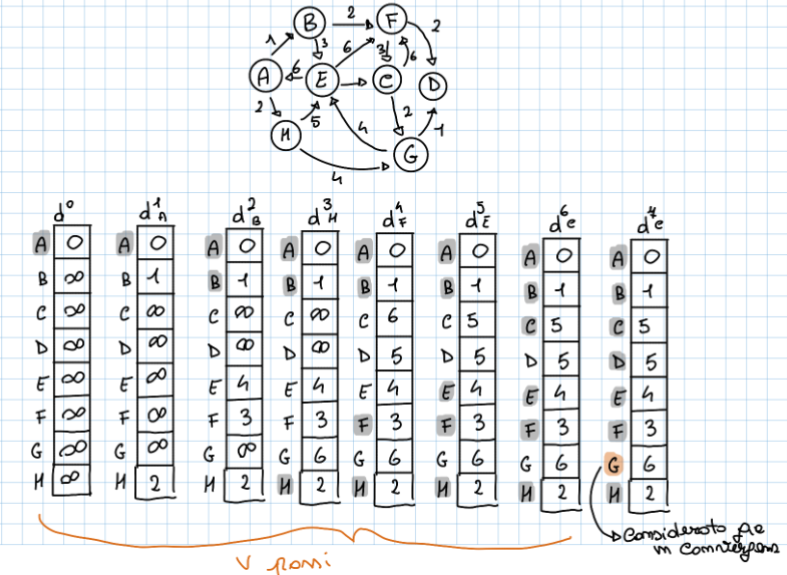
Complessità
Questa analisi deve essere divisa in varie sezioni:
- Inizializzazione: scorre tutti i nodi quindi ha un costo pari a:
- Costruzione min-heap: la costruzione del min-heap è lineare al numero di elementi quindi nel nostro caso avremo un costo pari a:
- While principale: la funzione extractMin di un min-heap come è noto impiega tempo nel nostro caso viene eseguita volte, quindi si avrà un costo pari a:
- Foreach interno: la funzione decreaseKey di un min-heap come è noto impiega tempo , viene richiamata ogni volta che troviamo un cammino più breve, quindi nel caso peggiore avviene per tutti gli archi quindi si avrà un costo pari a: Quindi il costo complessivo di questo algoritmo sarà:
Conclusioni sul problema dei cammini minimi da una sorgente
Conclusioni
Per la risoluzione di questo problema abbiamo presentato tre algoritmi:
- Single-Source Shortest Path
- Bellam-Ford
- Dijkstra Sia SSSP che Dijkstra hanno delle condizioni sul grafo per poter funzionare, questo li porta ad avere una complessità migliore rispetto a Bellam-Ford che resta però il più generalista.
Utilizzi molteplici
Questi algoritmi studiati principalmente per la risoluzione del problema single source possono essere usati anche per risolvere il problema di trovare il cammino minimo tra tutte le coppie però la complessità aumenta:
- Bellam-Ford:
- Dijkstra:
- DAG:
Programmazione dinamica per la risoluzione dei cammini minimi tra tutte le coppie
Definizione
In questo algoritmo la dimensione del problema viene identificata come: il numero di archi che possono essere presenti in un cammino minimo ovvero la lunghezza massima di un cammino minimo che sarebbe pari a , la dimensione del problema verrà di seguito identificata con . Indicheremo con il peso del cammino minimo da a usando archi.
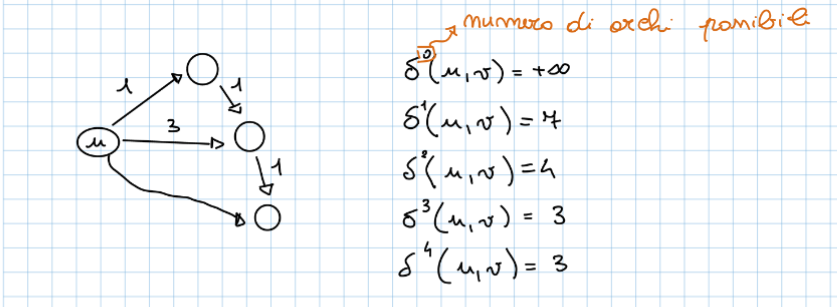
Ipotizzando di avere un cammino minimo da due generici vertici e al passo avremo questa cosa:
 se al passo (quindi con più archi disponibili) scopriamo di avere un altro percorso che passa dal nodo , quindi siamo in una situazione del tipo:
se al passo (quindi con più archi disponibili) scopriamo di avere un altro percorso che passa dal nodo , quindi siamo in una situazione del tipo: 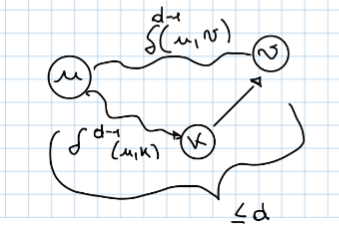 come facciamo a capire quale dei due percorsi ha il peso minore, lo facciamo in questo modo:
come facciamo a capire quale dei due percorsi ha il peso minore, lo facciamo in questo modo:
l_{i,j}^d = \begin{cases} w_{i,j} & \text{se } d = 1 \ \min_{1 \le k \le n} \left( l_{i,k}^{d/2} + l_{k,j}^{d/2} \right) & \text{se } d > 1 \end{cases}
Da questo nasce la una nuova implementazione della funzione $APSP$: ``` Fast-APSP(W) n = m // numero di vertici L^1 = W d = 1 while d < n - 1 do L^{2d} = EXTEND-APSP(L^d, L^d) d = 2d return L^d ``` Se inseriamo un iterazione in più otteniamo lo stesso risultato del ciclo finale di bellam-ford (la verifica di cicli negativi) ###### Complessità Il Fast-APSP ha complessità $O(V^3\log V)$ che è un miglioramento lieve rispetto a quello di bellam-ford ###### Risoluzione degli esercizi Utilizzare questo criterio quando chiede esercizi su grafi con algoritmo matriciale (quello lento) # **Passo D0** 1) Disegnare una matrice $n*n$ dove n è il numero dei vertici 2) Sulla diagonale metti 0 3) Per ogni vertice se esiste un arco da v a u scrivi nella matrice il peso dell'arco viceversa metti infinito **Passo Dn** Per ogni possibile coppia di vertici verifica se ne esiste un cammino con n nodi che avrà peso minore rispetto al cammino precedente. Tips: se un nodo non ha archi uscenti allora avrà sempre infinito su tutta la riga tranne la diagonale. ### Floyd-Warshall ###### Definizione D'ora in avanti indicheremo con $V_K$ il sottoinsieme di $V$ formato dai primi $K$ nodi\begin{aligned} V_k &= { v_1, v_2, v_3, \dots, v_k } \ V_0 &= { } \ V_1 &= { v_1 } \ V_2 &= { v_1, v_2 } \ &\vdots \ V_n &= V \end{aligned}
La dimensione del problema al passo k è definita *dalla possibilità di includere il k-esimo nodo come potenziale punto di passaggio per tutte le coppie (u,v).* ![[Pasted image 20260117105549.png]]considerando i due cammini evidenziati in blu ottengo un cammino che passa da $k$, ora bisogna capire quale dei due cammini è il migliore. E lo facciamo usando una matrice$$D^K[i,j] = \delta^K(i,j) = \begin{cases} w[i, j] & \text{se } k = 0 \\ \min \left( D^{k-1}[i, j], D^{k-1}[i, k] + D^{k-1}[k, j] \right) & \text{se } k > 0 \end{cases}$$ è molto simile al caso di programmazione dinamica che abbiamo fatto precedentemente, però in questo caso non dobbiamo provare tutte le $k$ ad ogni passaggio perché $k$ è già definita ###### Implementazione Dalla definizione di matrice precedentemente presentata otteniamo il seguente algoritmo: ``` FLOYD-WARSHALL(W) n = m // numero di vertici D^0 = W for k = 1 to n do D^k = new Matrix(n, n) for i = 1 to n do for j = 1 to n do // Se il cammino attraverso k è più breve, aggiorna if (D^{k-1}[i, j] > D^{k-1}[i, k] + D^{k-1}[k, j]) D^k[i, j] = D^{k-1}[i, k] + D^{k-1}[k, j] else D^k[i, j] = D^{k-1}[i, j] return D^n ``` Inoltre vogliamo creare un albero dei cammini minimi, per fare ciò dobbiamo tenere traccia dei predecessori dei nostri nodi, e lo facciamo usando una seconda matrice definita in questo modo:\pi^K[i, j] = \begin{cases} i & \text{se } [i, j] \in E \ \text{null} & \text{altrimenti} \end{cases}
![[Pasted image 20260117111058.png]] Di conseguenza il nostro algoritmo diventa: ``` Floyd-Warshall(W) n = m // numero di vertici D^0 = W // Inizializzazione della matrice dei predecessori Pi Pi^0 = new Matrix(n, n) for i = 1 to n do for j = 1 to n do if (i != j and W[i, j] < infinity) Pi^0[i, j] = i else Pi^0[i, j] = null // Ciclo principale dell'algoritmo for k = 1 to n do D^k = new Matrix(n, n) Pi^k = new Matrix(n, n) for i = 1 to n do for j = 1 to n do // Manteniamo i valori precedenti come base D^k[i, j] = D^{k-1}[i, j] Pi^k[i, j] = Pi^{k-1}[i, j] // Controllo se il passaggio per il nodo k migliora il cammino if (D^{k-1}[i, j] > D^{k-1}[i, k] + D^{k-1}[k, j]) D^k[i, j] = D^{k-1}[i, k] + D^{k-1}[k, j] Pi^k[i, j] = Pi^{k-1}[k, j] // Aggiorna il predecessore return D^n, Pi^n ``` ###### Esempio ![[Screenshot_20260117_112309_Samsung capture.jpg|500]] Ci sono delle euristiche da seguire per ridurre il carico di lavoro: *in generale devo fare len(V)+1 matrici (la prima è quella di adiacenza)* 1. Riscrivo la riga e la colonna $k$ perché sicuramente non cambia 2. Riscrivo la diagonale principale perché è sicuramente sempre 0 (non capita mai di avere dei cappi) 3. Prendo la colonna $k$ e se in una delle celle che la compongo ci trovo un $\infty$ riscrivo tutta la riga 4. Prendo la riga $k$ e se in una delle celle che la compongono ci trovo un $\infty$ riscrivo tutta la colonna ###### Complessità La complessità di questo algoritmo è $O(V^3)$ ottima rispetto a tutto quello che abbiamo trovato fino ad adesso. In generale si preferisce questo algoritmo anche quando servono i cammini minimi da una singola sorgente, perché ha la stessa complessità di bellam-ford.