la programmazione dinamica si applica ai problemi di ottimizzazione, questi problemi hanno molteplici soluzioni possibili, per capire quale soluzione è la migliore definiamo la funzione bontà che assegna ad ogni soluzione un grado di bontà.
Sviluppare un algoritmo di programmazione dinamica
Lo sviluppo di un algoritmo di programmazione dinamica si può essere suddiviso in queste fasi:
Caratterizzazione di una sotto-struttura ottima
Definire in modo ricorsivo il valore di una soluzione ottima
Costruire una procedura bottom-up per il calcolo di una soluzione ottima
Costruire una soluzione ottima dalle informazioni calcolate
Le fasi dalla 1 alla 3 formano la base per risolvere un problema applicando la programmazione dinamica. La fase 4 può essere omessa se è richiesto soltanto il valore di una soluzione ottima. Infine ricordiamo che:
Approcciare un problema in maniera top-down vuol dire risolverlo in maniera ricorsiva
Approcciare un problema in maniera bottom-up vuol dire risolverlo in maniera iterativa
Fibonacci
Definizione
La sequenza di Fibonacci è definita dalla seguente equazione:
Fn={1Fn−1+Fn−2se n≤2se n>2
L’implementazione diretta che ne facciamo è:
F(n):
if n <= 2 then
return 1
else
return F(n-2) + F(n-1)
Guardando l’albero di ricorsione si nota subito che alcuni sotto-problemi vengono risolti più volte, questo è ovviamente un problema che ci fa perdere tempo. Quello che facciamo è rendere un caso base ogni sotto-problema risolto
F(n)
// Inizializzazione
M = new Array(n) // array che contiene la soluzione
M[1] = M[2] = 1
for i = 3 to n DO M[i] <- NULL // inizializzazione
F(n)
if M[n] != null then
return M[n]
if M[n-1] == null then
M[n-1] <- F(n-1)
if M[n-2] == null then
M[n-2] <- F(n-2)
return M[n-1] + M[n-2]
Entrambe le soluzioni sono top-down, ma la seconda risulta più efficiente. Di seguito una soluzione bottom-up:
F(n):
M[1] <- M[2] <- 1
for i <- 3 to n do
M[i] <- M[i-2] + M[i-1]
return M[n]
Analisi
L’approccio ricorsivo puro non ha senso se un sotto-problema deve essere risolto più volte per arrivare alla soluzione, in quel caso ha più senso fare uso della memorizzazione.
Se lo spazio delle soluzioni viene esplorato tutto per trovare la soluzione allora ha più senso un approccio iterativo (bottom-up) come nel caso della sequenza di Fibonacci
Rod-cutting
Definzione
Il problema del taglio delle aste può essere definito nel seguente modo:
Data un’asta di lunghezza n pollici
Una tabella di prezzi pi con i=1,2,…,n
Bisogna determinare il ricavo massimo rn che si può ottenere tagliando l’asta e vendendone i pezzi.
Un’asta di lunghezza n può essere tagliata in 2n−1 modi differenti
Denotiamo una decomposizione in pezzi utilizzando la normale notazione additiva ovvero 7=2+2+3 indica che un asta di lunghezza 7 viene tagliata in tre pezzi.
Se una soluzione ottima prevede il taglio dell’asta in k pezzi, per 1≤k≤n allora la decomposizione: n=i1+i2+⋯+ikdell’asta in pezzi di lunghezza i1,i2,…,ik fornisce il ricavo massimo ovvero: rn=pi1+pi2+⋯+pik
Esempio: di seguito mostriamo un esempio di ricavi massimi per ogni possibile lunghezza della rod
Generalizzando
Generalizzando possiamo esprimere i valori di rn in funzione dei ricavi delle aste più corte ovvero:rn=max(pn,r1+rn−1,r2+rn−2,…,rn−1+r1)dove:
pn corrisponde alla vendita dell’asta di lunghezza n senza tagli
Gli altri n−1 argomenti corrispondono al ricavo massimo ottenuto facendo un taglio iniziale in due pezzi di dimensione i e n−i (con i=1,2,…,n−1) e poi tagliando in modo ottimale gli ulteriori pezzi ottenendo i ricavi ri e rn−i
Poiché non sappiamo a priori quale valore di i ottimizza i ricavi dobbiamo considerare tutti i possibili valori di i e selezionare quello che massimizza i ricavi. Per risolvere il problema originale stiamo risolvendo i problemi più piccoli dello stesso tipo questo lo possiamo fare perché il problema del taglio delle aste presenta una sottostruttura ottima ovvero le soluzioni ottime di un problema incorporano le soluzioni ottime dei sotto-problemi correlati.
Se vediamo ciascuna decomposizione di un’asta come un primo pezzo seguito da un’eventuale decomposizione del pezzo restante, possiamo riformulare rn come: rn=max1≤i≤n(pi+rn−i)quindi possiamo definire il nostro problema come: $$
r(i) = \begin{cases}
0 & \text{se } i = 0 \
\max_{1 \le k \le i} { p(k) + r(i - k) } & \text{se } i \ge 1
\end{cases}
```
CUT-ROD(p, n)
if n == 0
return 0
q = -infinity
for i = 1 to n
q = max(q, p[i] + CUT-ROD(p, n - i))
return q
```
Di seguito l'albero di ricorsione con $i = 4$
![[Screenshot_20251224_110126_Samsung capture.jpg|500]]
Notiamo subito che ci sono dei sotto-problemi che si ripetono più volte, quindi dobbiamo fare uso della memorizzazione per rendere il tutto più efficiente.
###### Implementazione bottom-up del ROD-CUT con memorizzazione
Globalmente avremo definito:
- $P$ array con i valori rispetto alla lunghezza
- $R$ array con i valori dei casi già esaminati
```
ROD-CUT(n)
if n = 0 then
return 0
for i <- 1 to n
m <- P(i) // salviamo il valore senza aver tagliato
for k <- 1 to i-1 DO // proviamo tutti i possibili tagli
if R(k) + R(i-k) > m //vediamo con quale otteniamo il valore migliore
then m <- R(k) + R(i-k) // salviamo il valore migliore ottenuto
R[i] <- m // lo salviamo nei casi già esaminati
```
![[Screenshot_20251224_112902_Samsung capture.jpg|500]]
Oltre a memorizzare i casi già risolti ora vogliamo memorizzare il modo migliore per tagliare la rod di lunghezza $i$ e lo facciamo usando un array $K$
**Esempio**: con $K = [ \underset{1}{1}, \underset{2}{2}, \underset{3}{3}, \underset{4}{2} ]$ sappiamo che una rod di lunghezza $4$ deve essere tagliata nel punto $2$ per ottenere il taglio migliore
```
ROD-CUT(n)
R <- new Array(n)
K <- new Array(n)
if n == 0 then
return 0
for i <- 1 to n
m <- P(i)
K[i] <- i
for k <- 1 to i-1 DO
if R[k] + R[i-k] > m then
m <- R[k] + R[i-k]
K[i] <- k //Salviamo il taglio migliore
R[i] <- m
return K
PRINT-CUT(n, K) //Funzione che stampa il taglio migliore dato n
if K[n] == n
print(n)
else
PRINT-CUT(K[n], K)
PRINT-CUT(n - K[n], K)
```
###### Sottostruttura ottima
Il problema del rodcut gode della proprietà della sottostruttura ottima di seguito la dimostrazione:
1. Prendiamo una soluzione ottima $S^*$ del problema
2. Supponiamo che questa soluzione preveda il taglio dell'asta in due pezzi: uno di lunghezza $k$ e uno di lunghezza $n-k$, il valore di questa soluzione quindi è definito come $$p(S^*) = p(S_k) + p(S_{n-k})$$
3. Supponendo per assurdo che $S_{n-k}$ non sia ottima, abbiamo quindi un'altra decomposizione $S'_{n-k}$ con valore più alto
4. Quindi otteniamo una nuova soluzione ottima definita in questo modo: $$p(S^*_{migliore}) = p(S_k) + p(S'_{n-k})$$
5. Visto che $p(S'_{n-k}) > p(S_{n-k})$ allora $p(S^*_{migliore})>p(S^*)$, questo rappresenta una contraddizione in quanto $S$ era già ottima
### Ottimizzazione della moltiplicazione tra matrici
Questo è un problema di ottimizzazione basato sul prodotto riga per colonna delle matrici, visto che questa operazione gode della proprietà associativa associando i prodotti in maniera diversa è possibile ottenere lo stesso risultato ma con un numero di operazioni scalari minori
###### Definizione della moltiplicazione tra matrici
Date due matrici $A$ e $B$ per poter effettuare il prodotto tra queste due dobbiamo rispettare la seguente condizione:
- Il numero delle colonne di $A$ deve essere uguale al numero di righe di $B$
L'implementazione della moltiplicazione è la seguente:
```
MATRIX-MULTIPLTY(A,B,p,q,w)
C = NEW MATRIX[p,w]
FOR i = 1 TO p DO
FOR j = 1 TO w DO
C[i,j] = 0
FOR k = 1 TO q DO
C[i,j] = C[i,j] + A[i,k]*B[k,j]
RETURN c
```
###### Analizziamo la complessità
Supponendo di voler moltiplicare una sequenza di tre matrici $$A_1· A_2 · A_3$$con:
- $A_1 = p \times q$
- $A_2 = q \times w$
- $A_3 = w \times q$
Il numero di operazioni scalari di $A_1 · A_2$ sarà uguale a $p·q·w$ (ottenendo in output una matrice di dimensione $p \times w$). Quindi la complessità di $A_1· A_2 · A_3$ sarà uguale alla somma della complessità tra i vari prodotti riga per colonna, quindi la complessità cambia in base a quale operazione effettuiamo prima.
*Esempio*
Con
- $A_1 = 10 \times 100$
- $A_2 = 100 \times 5$
- $A_3 = 5 \times 50$
La complessità della parentesizzazione $(A_1 · A_2)·A_3$ sarà:
$$10·100·5+10·5·50 = 5000+2500 = 7500$$
La complessità della parentesizzazione $A_1 · (A_2·A_3)$ sarà:
$$100·5·50+10·100·50 = 25000 + 50000 = 75000$$
Associazioni differenti creano complessità molto differenti, la domanda che adesso ci poniamo è:
*Come troviamo la parentesizzazione migliore per minimizzare il numero di operazioni scalari?*
###### Fasi della programmazione dinamica
**Premesse comuni a tutte le fasi**
- Abbiamo una sequenza di matrici $A_1, A_2, \dots A_n$
- abbiamo un vettore di interi $P = P_0, P_1, P_2, P_3, \dots P_n$
Le dimensioni della matrice $A_i$ sono $P_{i-1} \text{ e } P_i$
**1. Ricerca della sottostruttura ottima**
Presa la nostra sequenza di matrici $A_1, A_2, \dots A_n$ supponiamo che una parentesizzazione ottima di quest'ultima suddivida il prodotto in questo modo$$(A_1 \dots A_k)·(A_{k+1} \dots A_n)$$ovviamente anche entrambe le sotto sequenze devono essere parentesizzate in modo ottimo e quindi avremo che: $$S^*_{1,n} = S^*_{1,k}+S^*_{k+1,n} + P_0P_KP_n$$dove $P_0P_KP_n$ sono il numero di moltiplicazioni per $A_{1,k}·A_{k+1,n}$.
**Dimostrazione**:
Se ci fosse un modo meno costoso di parentesizzare $A_1 \dots A_k$ sostituendo questa parentesizzazione in quella ottima otterremo un'altra parentesizzazione di $A_1, A_2, \dots A_n$ il cui costo sarebbe minore di quella ottima: una contraddizione.
*Formalmente*:
Supponiamo che la sottostruttura non sia ottima. In particolare supponiamo che per la prima parte ($1$ a $k$) esista una soluzione migliore di quella usata, esiste un $S^{\text{migliore}}_{1,k}$ tale che:
$$S^{\text{migliore}}_{1,k}<S_{1,k}$$
se costruiamo la soluzione ottima con questa versione più economica otteniamo $$S^{\text{migliore}}_{1,n} = S^{\text{migliore}}_{1,k}+S^*_{k+1,n}+P_0P_KP_n$$Visto che abbiamo ipotizzato che $S^{\text{migliore}}_{1,k}<S_{1,k}$ allora necessariamente $$S^{\text{migliore}}_{1,n} < S^*_{1,n}$$Questo è un assurdo in quanto avevamo dichiarato che $S^*_{1,n}$ era già la soluzione ottimale
Usiamo la sottostruttura ottima per trovare una soluzione ricorsiva
**2. Definizione ricorsiva di una soluzione ottima**
Abbiamo la nostra sequenza di matrici: $A_i \dots A_j$ preso un $k$ generico avremo che $(A_i \dots A_k)(A_{k+1}\dots A_j)$ e su questo definiamo:
$$S_{i,j} = \begin{cases}
0 & \text{se } i = j \\
\min_{i \le k < j} (S_{i,k} + S_{k+1,j} + p_{i-1} p_k p_j) & \text{se } i < j
\end{cases}$$
Segue l'implementazione:
```
MATRIX-CHAIN-ORDER(p, i, j):
if i == j:
return 0
sm = +infinity // elemento più grande
for k from i to j-1:
// Chiamate ricorsive per calcolare i costi dei sottoproblemi
res_sinistro = MATRIX-CHAIN-ORDER(p, i, k)
res_destro = MATRIX-CHAIN-ORDER(p, k+1, j)
// Calcolo del costo attuale: costo sx + costo dx + costo moltiplicazione finale
costo_attuale = res_sinistro + res_destro + p[i-1] * p[k] * p[j]
if sm > costo_attuale:
sm = costo_attuale
return sm
```
Se eseguiamo questa funzione con $i = 1$ e $j = 4$ cerchiamo il modo ottimale di moltiplicare $A_1, A_2, A_3, A_4$ e otteniamo il seguente albero di ricorsione:
![[Pasted image 20251226111919.png|500]]
dalla quale notiamo subito che ci sono dei sotto problemi che si ripetono quindi dobbiamo usare una approccio bottom-up per rendere più efficiente l'algoritmo
**3. Ricerca di una soluzione ottima usando un approccio bottom-up**
Per risolvere il problema dei sotto problemi che si ripetono dobbiamo fare uso della memorizzazione, in questo caso non attraverso un array ma attraverso una matrice, visto che abbiamo due indici. Data la matrice $S$ possiamo dire che:
- $S[i,j]$ è il costo minimo per moltiplicare le matrici da $A_i$ fino ad $A_j$
- la diagonale principale contiene sempre $0$ perché moltiplicare una matrice per stesse non richiede alcuna operazione
- Visto che l'algoritmo calcola il costo solo dove $i<j$ sarà sola il triangolo superiore alla diagonale ad essere riempito
- Il risultato finale ovvero il costo minimo per moltiplicare la sequenza di $n$ matrici si trova in posizione $S[1,n]$
```
MATRIX-CHAIN-ORDER(P, n)
S = new matrix(n, n)
// Inizializzazione diagonale: costo 0 per catene di lunghezza 1
for i = 1 to n do
S[i, i] = 0 // Dim 1
// l è la lunghezza della catena
for l = 2 to n do // Dim l > 1
for i = 1 to n - l + 1 do
j = i + l - 1
S[i, j] = +∞
for k = i to j - 1 do
// Calcolo del costo temporaneo
costo = S[i, k] + S[k + 1, j] + P[i-1] * P[k] * P[j]
// Se il nuovo costo è minore, aggiorna la matrice
if S[i, j] > costo then
S[i, j] = costo
return S[1, n]
```
**ESEMPIO**
![[Screenshot_20251226_122108_Samsung capture.jpg|500]]
Questo algoritmo calcola il *costo minimo della soluzione* ma non abbiamo modo di sapere quale sia l'ordine effettivo delle matrici da moltiplicare.
Molti algoritmi richiedono di trovare il valore della soluzione ottima, quindi ci potremmo fermare al terzo step, in questo caso però abbiamo bisogno anche ricostruire la parentesizzazione della soluzione ottima in modo da poter effettuare la vera e propria moltiplicazione, da questa esigenza nasce lo step successivo, solitamente opzionale.
**4. Costruzione della soluzione ottimale**
```
MATRIX-CHAIN-ORDER(p, n)
S = new matrix(n, n)
D = new matrix(n, n)
for i = 1 to n do:
S[i, i] = 0
for l = 2 to n do:
for i = 1 to n - l + 1 do:
j = i + l - 1
S[i, j] = +infinity
for k = i to j - 1 do: # k è il punto di scissione
q = S[i, k] + S[k+1, j] + p[i-1] * p[k] * p[j]
if S[i, j] > q:
S[i, j] = q
D[i, j] = k # Memorizza il punto di scissione ottimale
return S[1, n]
PRINT-CHAIN(D, i, j)
if i == j:
print "A" + i
else:
k = D[i, j]
print "("
PRINT-CHAIN(D, i, k)
PRINT-CHAIN(D, k+1, j)
print ")"
```
Mentre l'algoritmo che è rimasto essenzialmente lo stesso si occupa di esplorare e trovare tutti i possibili modi di parentesizzare la catena $k$, la matrice $D[i,j]$ salva esattamente quale indice $k$ ha prodotto la parentesizzazione migliore. La funzione print-chain serve per stampare la parentesizzazione migliore in base ai parametri passati.
###### Complessità
Avendo tre cicli annidati la complessità è $O(n^3)$, è una complessità molto alta, infatti questo algoritmo viene utilizzando quando si devono moltiplicare matrici molto grandi dove c'è un vero e proprio guadagno.
### Distanza di Editing
###### Introduzione al Problema
Il problema fondamentale analizzato riguarda il calcolo della distanza tra due stringhe, $X$ e $Y$. Esistono diverse metriche per valutare questa distanza, come la **Distanza di Hamming** (che considera solo sostituzioni su stringhe di uguale lunghezza) o la più generale **Distanza di Editing** (o distanza di Levenshtein).
La Distanza di Editing definisce il numero minimo di operazioni necessarie per trasformare la stringa $X$ nella stringa $Y$. Le operazioni consentite, ciascuna con un costo unitario, sono:
1. **Inserimento** di un carattere.
2. **Cancellazione** di un carattere.
3. **Sostituzione** di un carattere.
Consideriamo ad esempio la trasformazione dalla parola "CASA" alla parola "CHIESA".
- _CASA_ $\to$ _CHASA_ (Inserimento 'H')
- _CHASA_ $\to$ _CHESA_ (Sostituzione 'A' con 'E')
- _CHESA_ $\to$ _CHIESA_ (Inserimento 'I')
###### Sottostruttura ottima
**Tesi**: Sia $S$ una sequenza ottima di operazioni che trasforma il prefisso $X[1\dots i]$ nel prefisso $Y[1\dots j]$. Vogliamo dimostrare che la sottosequenza contenuta in $S$ che risolve i sottoproblemi deve essere a sua volta ottima.
**Dimostrazione**: analizziamo l'ultima operazione effettuata nella sequenza $S$, da qui distinguiamo 3 casi possibili
1. L'utlima operazione è una sostituzione, allora $S$ è composta da una sottosequenza $S'$ e da un operazione di sostituzione, allora il suo costo totale è $$\text{costo(S) = Costo(S') + costo sostituzione}$$Se $S'$ per assurdo non è ottima allora esisterebbe $S''$ con un costo strettamente minore, questo significa che abbiamo trovato una soluzione $W$ con un costo minore di $S$, siamo arrivati ad una contraddizione
2. Analoga ma con la cancellazione come ultima operazione
3. Analoga ma con l'inserimento come ultima operazione
###### Definizione Formale e Ricorsiva
Date due stringhe:
- $X$ di lunghezza $n$, dove $x_i = X[1 \dots i]$ è il prefisso di lunghezza $i$.
- $Y$ di lunghezza $m$, dove $y_j = Y[1 \dots j]$ è il prefisso di lunghezza $j$.
Definiamo $ED(i, j)$ come la distanza di editing tra i prefissi $x_i$ e $y_j$. La soluzione può essere espressa ricorsivamente:
**Casi Base**
Se una delle due stringhe è vuota, la distanza è pari alla lunghezza dell'altra stringa (tutti inserimenti o cancellazioni):
- $ED(i, 0) = i$
- $ED(0, j) = j$
**Passo Ricorsivo**
Per calcolare $ED(i, j)$ con $i, j > 0$, consideriamo i caratteri $x_i$ e $y_j$:
1. Se $x_i = y_j$ (Match): Non è necessaria alcuna operazione sui caratteri correnti. Il costo è ereditato dai prefissi precedenti: $$ED(i, j) = ED(i-1, j-1)$$
2. Se $x_i \neq y_j$ (Mismatch): Dobbiamo scegliere l'operazione che minimizza il costo tra le tre possibili:
- _Sostituzione:_ $ED(i-1, j-1) + 1$
- _Cancellazione (da X):_ $ED(i-1, j) + 1$
- _Inserimento (in Y):_ $ED(i, j-1) + 1$
La formula completa è:
$$ED(i, j) = \min(ED(i-1, j) + 1, ED(i, j-1) + 1, ED(i-1, j-1) + \text{costo\_sostituzione})$$
(Nota: il costo di sostituzione è 1 se i caratteri sono diversi, 0 se uguali).
###### Programmazione Dinamica
L'approccio ricorsivo puro ("top-down") è inefficiente a causa della ricalcolazione dei sottoproblemi sovrapposti. La soluzione ottimale utilizza la **Programmazione Dinamica** ("bottom-up"), costruendo una tabella (matrice) di dimensione $(n+1) \times (m+1)$.
**Algoritmo per il calcolo della Distanza (EDT)**
*Input*: Stringhe $X, Y$ di lunghezza $n, m$.
*Complessità*: Tempo $O(n \times m)$, Spazio $O(n \times m)$ (ottimizzabile a $O(\min(n, m))$ se si memorizzano solo le ultime due righe).
**Pseudocodice:**
```
EDT(X, Y, n, m)
Dichiara matrice ED[0..n, 0..m]
// Inizializzazione
FOR i = 0 TO n DO ED[i, 0] = i
FOR j = 0 TO m DO ED[0, j] = j
// Riempimento Matrice
FOR i = 1 TO n DO
FOR j = 1 TO m DO
IF X[i] == Y[j] THEN
ED[i, j] = ED[i-1, j-1]
ELSE
ED[i, j] = min(ED[i, j-1], // Inserimento
ED[i-1, j], // Cancellazione
ED[i-1, j-1]) // Sostituzione
+ 1
```
###### Ricostruzione della Soluzione Ottima
Una volta compilata la matrice, il valore in $ED[n, m]$ rappresenta il costo minimo. Per trovare la sequenza di operazioni, si esegue un "backtracking" dalla cella $(n, m)$ alla cella $(0, 0)$.
**Pseudocodice Ricostruzione:**
```
PRINT-EDT(ED, X, Y, n, m)
i = n, j = m
WHILE (i > 0 OR j > 0)
IF (i > 0 AND j > 0 AND X[i] == Y[j]) THEN
// Match: nessun costo, ci spostiamo in diagonale
i = i - 1
j = j - 1
ELSE
// Determiniamo da quale cella proviene il minimo
min_val = min(ED[i, j-1], ED[i-1, j], ED[i-1, j-1])
IF (j > 0 AND min_val == ED[i, j-1]) THEN
STAMPA("Inserimento di " + Y[j])
j = j - 1
ELSE IF (i > 0 AND min_val == ED[i-1, j]) THEN
STAMPA("Cancellazione di " + X[i])
i = i - 1
ELSE
STAMPA("Sostituzione di " + X[i] + " con " + Y[j])
i = i - 1
j = j - 1
```
---
### Longest Common Substring
Date due stringhe X e Y devo cercare la più lunga stringa di caratteri **consecutivi** comune a entrambe le stringhe.
Vediamo se questo problema può essere risolto tramite la prog dinamica
Ricordiamo che dobbiamo dimostrare 2 cose:
1) la soluzione ottima di un problema contiene al suo interno le soluzioni ottime dei suoi sotto problemi
2) definire un approccio ricorsivo per risolvere il problema
###### Sottostruttura ottima:
**Definizione del sotto problema:** Definiamo $L(i, j)$ come la lunghezza della più lunga sottostringa comune che **termina esattamente** agli indici $i$ di $X$ e $j$ di $Y$ (ovvero il "suffisso comune").
**La Tesi:** Se i caratteri $X[i]$ e $Y[j]$ sono uguali, allora la lunghezza del suffisso comune che termina in $(i, j)$ dipende direttamente dalla lunghezza del suffisso comune che terminava in $(i-1, j-1)$.
**La Dimostrazione (Logica):**
Supponiamo che $X[i] == Y[j]$.
Poiché stiamo cercando una **sottostringa** (caratteri _consecutivi_), il carattere corrente estende semplicemente ciò che c'era immediatamente prima.
- Se la soluzione per $(i, j)$ è una stringa di lunghezza $K > 1$, significa che i caratteri $X[i]$ e $Y[j]$ sono l'ultimo carattere di questa stringa.
- Se rimuoviamo questo ultimo carattere, rimaniamo con una sottostringa comune di lunghezza $K-1$ che termina agli indici $i-1$ e $j-1$.
- Affinché la soluzione a $(i, j)$ sia **ottima** (massima), anche la soluzione a $(i-1, j-1)$ deve essere **ottima**. Se ci fosse un suffisso comune più lungo a $(i-1, j-1)$, potremmo aggiungerci $X[i]$ (che è uguale a $Y[j]$) ottenendo un risultato migliore per $(i, j)$, contraddicendo l'ipotesi iniziale.
Longest
###### Definizione funzione ricorsiva:
Dati due indici $i$ e $j$ (rispettivamente per le stringhe $X$ e $Y$) sfrutteremo una matrice per memorizzare i risultati e la soluzione sarà la casella con valore massimo della matrice:
**Caso Base:** Se uno degli indici è 0 (stringa vuota o prima dell'inizio), non c'è nessuna stringa comune.
$$L(i, 0) = 0, \quad L(0, j) = 0$$
**Caso 1: I caratteri corrispondono ($X[i] == Y[j]$)** Poiché i caratteri sono uguali, estendiamo la sottostringa comune trovata nel passo precedente (la "diagonale" precedente nella matrice).
$$L(i, j) = 1 + L(i-1, j-1)$$
_Perché $i-1, j-1$?_ Perché per mantenere la **consecutività**, dobbiamo guardare i caratteri immediatamente precedenti in entrambe le stringhe.
**Caso 2: I caratteri NON corrispondono ($X[i] \neq Y[j]$)** Poiché una sottostringa deve essere consecutiva, se i caratteri attuali sono diversi, la catena si **spezza**. Non possiamo "saltare" un carattere.
$$L(i, j) = 0$$
Il suffisso comune che _termina_ in questi indici ha lunghezza 0.
Se dopo che la catena si spezza il contatore di caratteri torna a 0 e si ripete la procedura fino a quando non si raggiungono i casi base.
###### Soluzione con programmazione dinamica:
**Logica dell'algoritmo:**
1. Creiamo una matrice `dp` di dimensione $(m+1) \times (n+1)$.
2. Iteriamo sulle stringhe.
3. Se $X[i] == Y[j]$, incrementiamo il valore della diagonale precedente ($dp[i-1][j-1] + 1$).
4. Se $X[i] \neq Y[j]$, mettiamo $0$.
5. Teniamo traccia di una variabile `max_len` durante il processo.
```
dp[][]= new matrix(m+1,n+1)
maxLength = 0
endIndex = 0
for i from 1 to m+1 do:
for j from 1 to n+1 do:
if X[i] == Y[j]:
dp[i][j] = dp[i-1][j-1] +1
if dp[i][j] > maxLength:
maxLength = dp[i][j]
endIndex = i
else:
dp[i][j] = 0
LCS = X[endIndex - maxLenght : endIndex]
return LCS
```
> [!TIP]
>
> $$endIndex - maxLenght : endIndex$$
> indica lo slicing della stringa da endIndex - maxLength a endIndex.
> *Esempio*: endIndex = 5 maxLength = 2 ---> da 3 a 5
### Longest Common Subsequence (LCS)
Date due sequenze $X$ e $Y$, il problema consiste nel trovare la più lunga sottosequenza comune a entrambe. A differenza delle sottostringhe, una **sottosequenza** non richiede che gli elementi siano consecutivi nella sequenza originale, ma devono mantenere lo stesso ordine relativo. Ad esempio, data $X = \langle A, B, C, B, D, A, B \rangle$, la sequenza $\langle B, C, D, B \rangle$ è una sua sottosequenza. Vediamo come risolvere questo problema tramite la programmazione dinamica.
###### Sottostruttura ottima
**Sottostruttura ottima di una LCS**
Siano $X = \langle x_1, x_2, \dots, x_m \rangle$ e $Y = \langle y_1, y_2, \dots, y_n \rangle$ le sequenze; sia $Z = \langle z_1, z_2, \dots, z_k \rangle$ una qualsiasi LCS di $X$ e $Y$.
1. Se $x_m = y_n$, allora $z_k = x_m = y_n$ e $Z_{k-1}$ è una LCS di $X_{m-1}$ e $Y_{n-1}$.
2. Se $x_m \neq y_n$, allora $z_k \neq x_m$ implica che $Z$ è una LCS di $X_{m-1}$ e $Y$.
3. Se $x_m \neq y_n$, allora $z_k \neq y_n$ implica che $Z$ è una LCS di $X$ e $Y_{n-1}$.
> [!TIP]
>
> In questa definizione partiamo dalla fine della nostra stringa, se le stringhe sono uguali allora quel carattere deve essere salvato nella sottostringa comune $z$ e quindi il problema si riduce di $1$, se le stringhe non sono uguali il problema resta quello di trovare la sottostringa comune ignorando quel carattere ecco perché: ($X_{m-1}$ e $Y$) o ($X$ e $Y_{n-1}$)
**Dimostrazione**
1. Visto che deve essere $z_k = x_m = y_n$. Ora, il prefisso $Z_{k-1}$ è una sottosequenza comune di $X_{m-1}$ e $Y_{n-1}$ di lunghezza $k - 1$. Vogliamo dimostrare che questo prefisso è una LCS. Supponiamo per assurdo che ci sia una sottosequenza comune $W$ di $X_{m-1}$ e $Y_{n-1}$ di lunghezza maggiore di $k - 1$. Allora, accodando $x_m = y_n$ a $W$ si ottiene una sottosequenza comune di $X$ e $Y$ la cui lunghezza è maggiore di $k$, che è una contraddizione.
2. Se $z_k \neq x_m$, allora $Z$ è una sottosequenza comune di $X_{m-1}$ e $Y$. Se esistesse una sottosequenza comune $W$ di $X_{m-1}$ e $Y$ di lunghezza maggiore di $k$, allora $W$ sarebbe anche una sottosequenza comune di $X_m$ e $Y$, contraddicendo l’ipotesi che $Z$ sia una LCS di $X$ e $Y$.
3. La dimostrazione è simmetrica a quella del punto (2).
###### Definizione funzione ricorsiva
Definiamo $c[i, j]$ come la lunghezza di una LCS delle sequenze $X_i$ e $Y_j$.
**Caso Base:** Se una delle sequenze ha lunghezza 0, la lunghezza della LCS è 0.
$$c[i, j] = 0 \quad \text{se } i=0 \text{ oppure } j=0$$
**Caso 1: I caratteri corrispondono ($x_i == y_j$):** Abbiamo trovato un elemento della LCS. Incrementiamo di 1 la lunghezza della LCS trovata nei prefissi precedenti ($i-1, j-1$).
$$c[i, j] = c[i-1, j-1] + 1$$
**Caso 2: I caratteri NON corrispondono ($x_i \neq y_j$):** Non possiamo estendere la sottosequenza con l'attuale coppia. Dobbiamo cercare la soluzione migliore risolvendo i due sottoproblemi possibili (ignorando l'ultimo carattere di $X$ o ignorando l'ultimo carattere di $Y$) e prendendo il massimo.
$$c[i, j] = \max(c[i, j-1], c[i-1, j])$$
###### Soluzione con programmazione dinamica
**Logica dell'algoritmo:**
1. Creiamo una tabella $c$ di dimensione $(m+1) \times (n+1)$ per memorizzare le lunghezze.
2. Creiamo una tabella $b$ per memorizzare le "frecce" che indicano quale sottoproblema ha generato la soluzione ottima ($\nwarrow, \uparrow, \leftarrow$) .
3. Inizializziamo la prima riga e la prima colonna a 0 .
4. Iteriamo attraverso la tabella riga per riga (bottom-up).
5. Se $x_i == y_j$, il valore deriva dalla diagonale in alto a sinistra + 1 (freccia $\nwarrow$).
6. Se $x_i \neq y_j$, il valore è il massimo tra il vicino in alto (freccia $\uparrow$) e il vicino a sinistra (freccia $\leftarrow$) .
7. Il valore in $c[m, n]$ è la lunghezza della LCS. Per ricostruire la stringa, seguiamo le frecce a ritroso partendo da $b[m, n]$ .
```
LCS-LENGTH(X, Y)
m = X.length
n = Y.length
Siano b[1..m, 1..n] e c[0..m, 0..n] nuove tabelle
// Inizializzazione casi base
for i = 1 to m: c[i, 0] = 0
for j = 0 to n: c[0, j] = 0
// Calcolo Bottom-up
for i = 1 to m:
for j = 1 to n:
if X[i] == Y[j]:
c[i, j] = c[i-1, j-1] + 1
b[i, j] = "↖" // Corrisponde a diagonale
elseif c[i-1, j] >= c[i, j-1]:
c[i, j] = c[i-1, j]
b[i, j] = "↑" // Corrisponde a 'su'
else:
c[i, j] = c[i, j-1]
b[i, j] = "←" // Corrisponde a 'sinistra'
return c, b
```
Per stampare la sequenza effettiva, si usa una procedura ricorsiva che segue la tabella $b$ a ritroso:
```
PRINT-LCS(b, X, i, j)
if i == 0 or j == 0:
return
if b[i, j] == "↖":
PRINT-LCS(b, X, i-1, j-1)
print X[i]
elseif b[i, j] == "↑":
PRINT-LCS(b, X, i-1, j)
else:
PRINT-LCS(b, X, i, j-1)
```
# Algoritmi golosi
### Introduzione
###### Definizione
Un'altra strategia che possiamo sfruttare per risolvere problemi di ottimizzazione è la strategia greedy, in italiano golosa. Un algoritmo goloso fa sempre la scelta che sembra ottima in un determinato momento, ovvero fa una scelta *localmente ottima*, nella speranza che tale scelta porterà a una soluzione globalmente ottima. La scelta greedy che viene fatta cambia da problema a problema.
### Problema dello zaino
###### Definizione
Riprendendo il problema dello zaino presentato nella lezione 2, ricordiamo che:
- $k$ capienza dello zaino
- $A = \{a_1,a_2,\dots,a_n\}$
- $P(a_i) =$ peso dell'oggetto
- $V(a_i) =$ valore dell'oggetto
- *Obbiettivo*: massimizzare il guadagno
in questo caso però ogni oggetto ha lo stesso valore ovvero: $$v(a) = 1 \; \forall a \in A$$
Banalmente ciò che dobbiamo massimizzare è il numero di oggetti. Un ottima strategia (greedy) è quella di scegliere l'oggetto con il peso minore.
###### Dimostrazione scelta greedy
a_w : P(a_w) = \min{\text{Peso}(a_j) : a_j \in A}
Ovvero $a_w$ scelta greedy. $S \subseteq A$ è una soluzione ottima. Allora $a_w \in S$.
Ipotizziamo per assurdo che $a_w \notin S$.
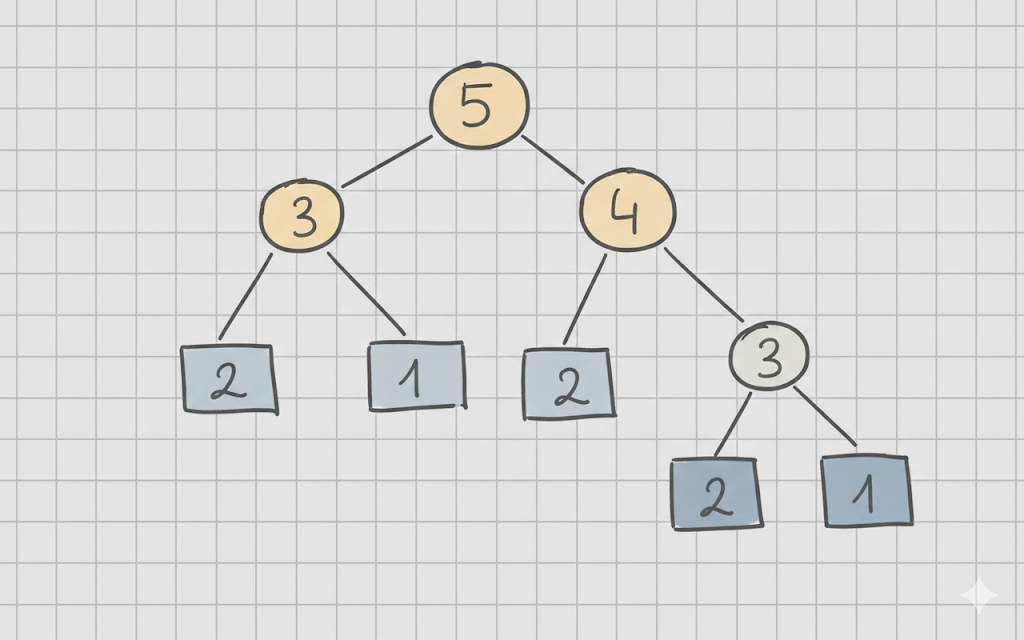 Guardando l’albero di ricorsione si nota subito che alcuni sotto-problemi vengono risolti più volte, questo è ovviamente un problema che ci fa perdere tempo. Quello che facciamo è rendere un caso base ogni sotto-problema risolto
Guardando l’albero di ricorsione si nota subito che alcuni sotto-problemi vengono risolti più volte, questo è ovviamente un problema che ci fa perdere tempo. Quello che facciamo è rendere un caso base ogni sotto-problema risolto