Wireshark: programma che serve per vedere il traffico di rete
abbiamo fatto delle prove in localhost praticamente abbiamo aperto un pagina web e abbiamo analizzato tutte le informazioni che vengono inviate al login (con username e password) vediamo che il server risponde con il Token di sessione, rubare il token di sessione è alla base del phishing
Ci sono due modi per risolvere questo problema:
- Usare HTTPS
- Refreshare il token di sessione spesso (così anche se rubato si ha poco tempo per usarlo)
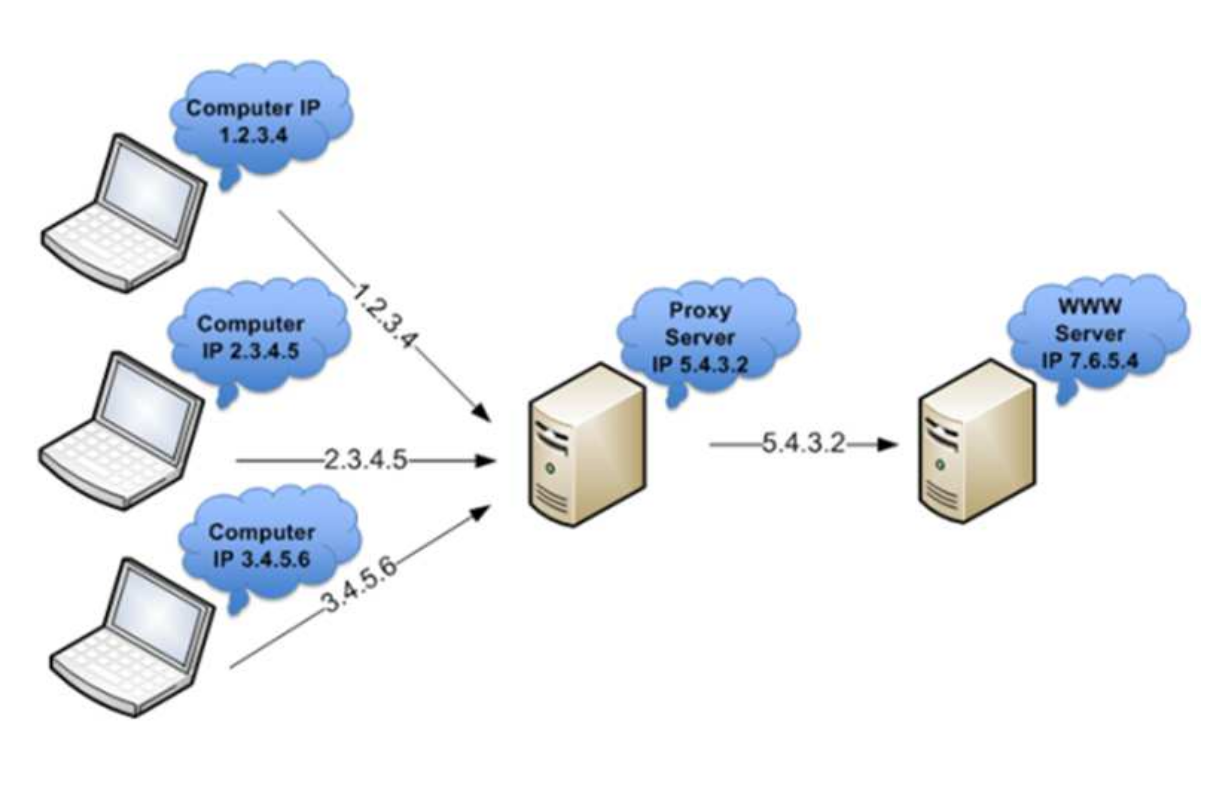
Proxy: serve per mascherare l’ip di un servizio sulla rete, di seguito il dettaglio di quello che succede:
- I client mandano le richieste al proxy.
- Il proxy le invia al server destinazione.
- Il server riceve la richiesta del proxy.
- Il server invia la risposta al proxy.
- Il proxy invia la risposta del server al client originale.
il proxy ha una cache quindi può capitare che risponda con una pagina web vecchia e non aggiornata
 SMTP(Simple Mail Transfer Protocol): questo è il protocollo utilizzato per lo scambio di posta elettronica, in specifico si occupa di trasferire le mail dal server mittente a quello destinazione. Usa la porta 25 su TCP
SMTP(Simple Mail Transfer Protocol): questo è il protocollo utilizzato per lo scambio di posta elettronica, in specifico si occupa di trasferire le mail dal server mittente a quello destinazione. Usa la porta 25 su TCP
 La @ nella mail viene inserita per distinguere il nome utente dal server di destinazione
Di seguito quello che accade veramente:
La @ nella mail viene inserita per distinguere il nome utente dal server di destinazione
Di seguito quello che accade veramente:
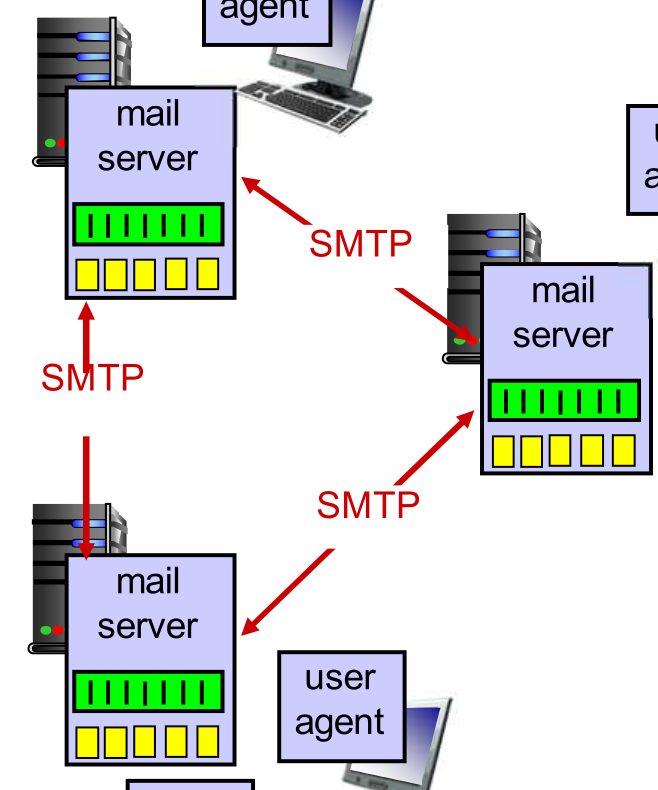
 L’immagine mostra perfettamente la natura “botta e risposta” del protocollo SMTP, basato su comandi testuali chiari (come
L’immagine mostra perfettamente la natura “botta e risposta” del protocollo SMTP, basato su comandi testuali chiari (come HELO,MAIL FROM,RCPT TO) e codici di stato standardizzati. In questo scenario, l’email è stata autorizzata per Jones e Brown, ma la consegna a Green è fallita a causa di un indirizzo inesistente.
Il client che si connette al server viene chiamato user-agent: si collega al server di posta e ci permette di interagire con le nostre mail, questo può essere fatto anche tramite SMPT ma è molto più conveniente usare POP3 e IMAP
POP3(Post Office Protocol): scarica le mail dal server e ci permette la visualizzazione anche offline (cancella le mail dal server di posta) IMAP(Acronimo): ci permette la visualizzazione delle mail senza scaricarle, è più semplice ma non ci permette di visualizzare le mail se siamo offline, usando questo protocollo ovviamente le mail non vengono cancellate dal server di posta (google ha tutte le nostre email nei suoi database)
| Caratteristica | POP3 | IMAP |
|---|---|---|
| Dove è definito il protocollo? | RFC 1939 | RFC 2060 |
| Quale porta TCP viene utilizzata? | 110 | 143 |
| Dove sono memorizzate le e-mail? | PC dell’utente | Server |
| Dove vengono lette le e-mail? | Offline | Online |
| Tempo di connessione richiesto? | Poco | Molto |
| Uso delle risorse del server? | Minimo | Esteso |
| Caselle di posta multiple? | No | Sì |
| Chi esegue il backup delle caselle di posta? | Utente | ISP (Provider) |
| Adatto per utenti mobile? | No | Sì |
| Controllo utente sui download? | Poco | Elevato |
| Download parziale dei messaggi? | No | Sì |
| Le quote disco sono un problema? | No | Potrebbero diventarlo nel tempo |
| Semplice da implementare? | Sì | No |
| Supporto diffuso? | Sì | In crescita |
| Mail di SPAM: lo spam di mail nasce dalla famosa azienda spam che un giorno per pubblicizzare il suo prodotto ha inviato un sacco di mail contemporaneamente. |
DNS (Domain Name System): Gli indirizzi IP identificano in modo univoco le macchine nella rete, per noi umani è difficile ricordare una sequenza di numeri, quindi si danno dei noi l’associazione nome-indirizzoIP viene risolta usando il protocollo DNS.
 Di seguito un esempio
Di seguito un esempio
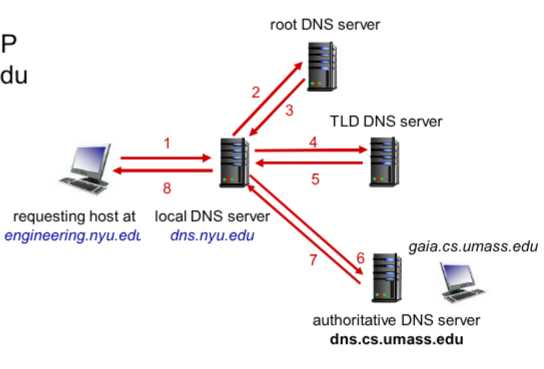 Questi sono i passaggi che fa un dispositivo per risolvere un nome in un indirizzo IP.
Questi sono i passaggi che fa un dispositivo per risolvere un nome in un indirizzo IP.
In pratica il DNS è un database distribuito in tutto il mondo, viene gestito come un albero, questo albero ha 13 radici. In pratica ogni dispositivo sa raggiungere un server che conosce più indirizzi di lui se l’indirizzo cercato non viene trovato(fino ad arrivare al server root). L’architettura dei domini è divisa in 4 livelli chiari:
- Root Domain
- Top-Level Domain (TLD)
- Second-Level Domain (SLD)
- Sottodomini (Third-Level e oltre)
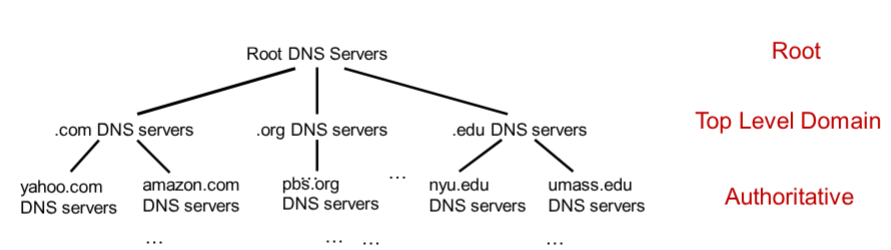 è un protocollo molto scalabile, in quanto la maggior parte delle richieste vengono risolte a livello basso (grazie alle cache) e quasi mai al root level. Banalmente se noi cerchiamo google.it su rete UNICT il server dell’ateneo sa risolvere l’indirizzo IP a livello 1.
è un protocollo molto scalabile, in quanto la maggior parte delle richieste vengono risolte a livello basso (grazie alle cache) e quasi mai al root level. Banalmente se noi cerchiamo google.it su rete UNICT il server dell’ateneo sa risolvere l’indirizzo IP a livello 1.
Esempio
Prendendo come esempio l’indirizzo
web.dmi.unict.it., la suddivisione è la seguente: il punto finale implicito rappresenta il Root Domain , “it” è il Top-Level Domain (TLD) , “unict” è il Second-Level Domain (SLD) , e infine “dmi” e “web” sono i sottodomini di terzo livello e oltre.
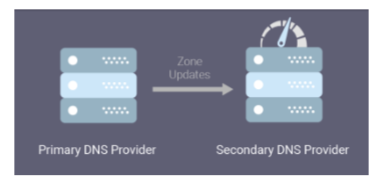
Esistono due tipi di server DNS in un’azienda:
- Primario: Qui risiedono i dati ufficiali (l’admin modifica qui i record del dns db)
- Secondario: Se il server primario dovesse andare offline, il server secondario continuerà a rispondere alle richieste degli utenti, garantendo che il sito web rimanga raggiungibile. Il processo di aggiornamento è semplice:
- Aggiorno i record nel Primario
- Vengono aggiornati in automatico anche i record nel secondario
Fuori contesto: posso mettermi in mezzo alla comunicazione tra due PC diventando un man in the middle e riuscendo a catturare tutti i dati che vanno da A a B
Esistono anche dei protocolli utilizzati per la diagnostica, uno di quelli più utilizzati è SNPM (Simple Network Management Protocol), non ci interessa in modo reale come funziona, dobbiamo solo sapere che esiste e per cosa viene utilizzato (ha solo detto il nome praticamente).
Siamo passati a 3 - Transport_N.pdf
Nello stack abbiamo diversi layer:
- Datalink layer: comunicazione fisica tra gli host
- Network layer: comunicazione logica tra gli host
- Trasport layer: comunicazione logica tra i processi (usando IP e porta)
Il trasporto a livello trasport viene fatta usando:
- il multiplexing (sorgente): è il processo con cui un host incapsula i frammenti di dati provenienti da uno o più sockets in segmenti del transport layer.
- il demultiplexing (destinazione): Consiste nella consegna dei segmenti al socket corretto.
Per fare queste cose vengono utilizzati due protocolli (uno o l’altro):
- RDT(Reliable Data Transfer): affidabile e lento, TCP(Trasmission Control Protocol) è la sua implementazione più famosa. Viene diviso in diverse versioni dal nostro libro per farci capire come si è arrivati storicamente a TCP, esiste una singola versione.
- UDP: inaffidabile ma molto veloce
UDP(User Datagram Protocol): offre un servizio “best effort”. Visto che non garantisce l’arrivo dei dati è un protocollo molto semplice, non viene stabilita una connessione reale tra sorgente e destinazione, grazie a queste caratteristiche è molto veloce.
- Multiplexing: L’incapsulamento dei frammenti di dati durante il multiplexing avviene utilizzando opportuni header.
- Dimensioni dell’Header: L’header del protocollo UDP occupa 8 byte: 2 byte per la porta del mittente, 2 per la porta del destinatario, 2 per la lunghezza del messaggio e 2 per il checksum. Per confronto, l’header del protocollo TCP occupa dai 20 ai 60 byte.
- Funzionamento del Checksum: Il checksum è un meccanismo che consente di rilevare errori di trasmissione che spesso consistono in bit-flip. La verifica consiste nel calcolo di un checksum sia al mittente che al destinatario. Se le due somme non dovessero coincidere, il pacchetto sarà da considerarsi fallato, e verrà scartato.
Implementa anche un checksum che rileva gli errori in trasmissione (non viene utilizzata perché ritenuta troppo semplice)
Nel mondo reale funziona in questo modo:
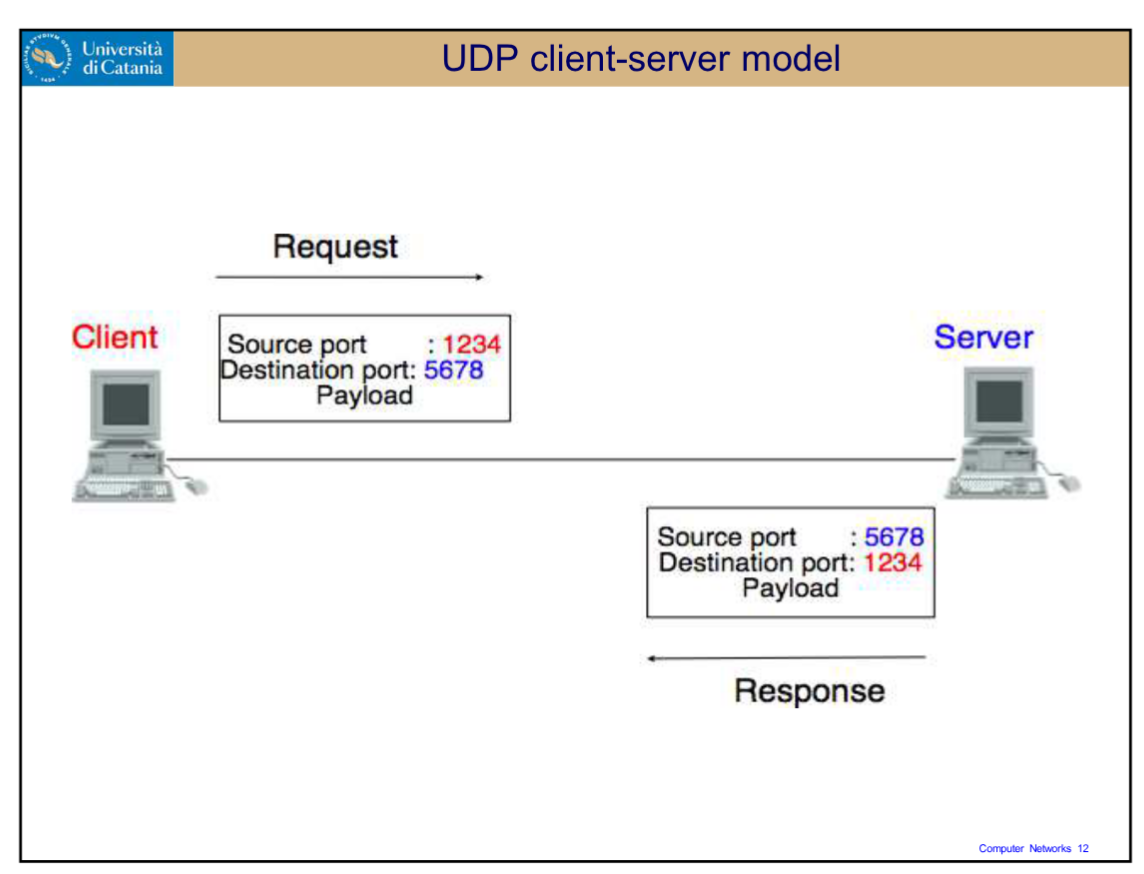
RDT: riesce a rendere affidabile qualcosa di inaffidabile, lo fa pagando in termini di velocità. Il nostro libro ha creato delle versioni per farci capire come si è arrivati alla versione finale:
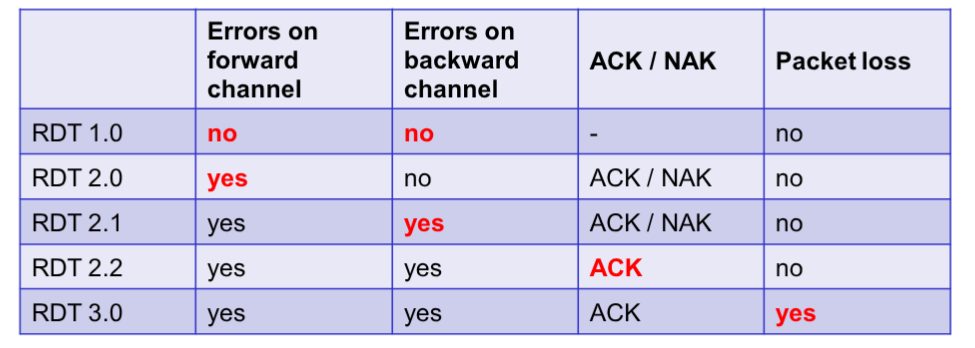 Osserviamo in breve le caratteristiche dei vari RDT prima di studiarne le FSM al dettaglio:
Osserviamo in breve le caratteristiche dei vari RDT prima di studiarne le FSM al dettaglio:
- 1.0.: Non include nessun meccanismo effettivo, ma fa da base per le versioni successive.
- 2.0.: Gestisce i pacchetti corrotti tramite segnali di ACK/NAK, ma non gestisce ACK e NAK corrotti.
- 2.1.: Gestisce gli errori sul backward channel (un canale usato per l’invio di ACK/NAK).
- 2.2.: Si elimina il simbolo dedicato NAK, utilizzando in maniera differente gli ACK
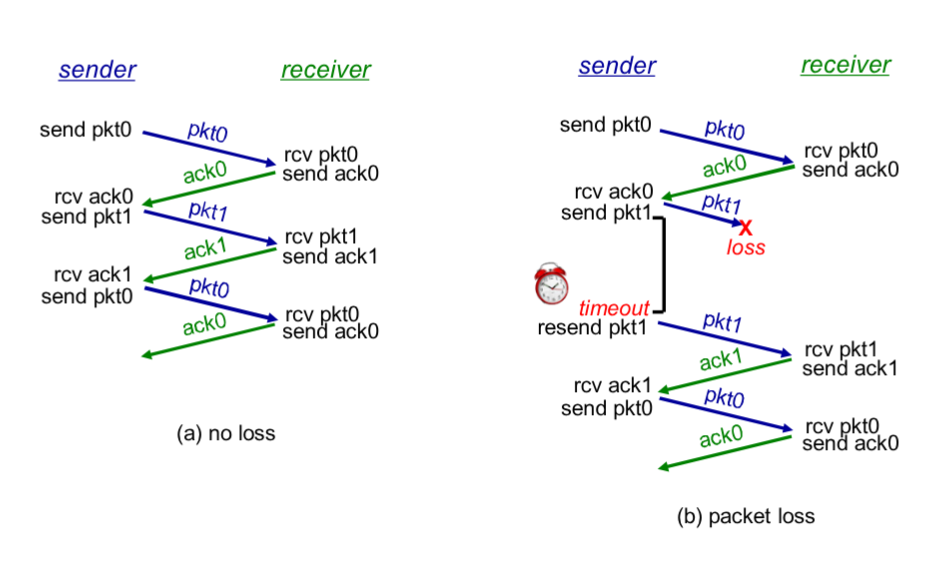
- 3.0.: Tutte le precedenti versioni gestiscono solo pacchetti corrotti. Con questa versione, si verifica anche la perdita dei pacchetti, introducendo il meccanismo di time-out.
Approfondire studiando gli stati reali in cui si trovano le macchine nelle varie fasi
Di seguito la versione 3 nel mondo reale