Heap
Introduzione
Si usa l’heap per implementare efficientemente le code con priorità. Questo tipo di coda non serve gli elementi in base al momento di arrivo, ma in base a una caratteristica intrinseca chiamata chiave (o priorità). Spesso viene astratta come un albero (successivamente la implementiamo come array)
Caratteristiche principali
Lo heap è un albero con le seguenti caratteristiche:
- Binario: ogni nodo ha al massimo due figli.
- Posizionale: è possibile distinguere figlio destro e figlio sinistro
- Completo: In ogni livello dell’albero sono presenti nodi
- Parzialmente ordinato: Il valore di un nodo sarà sempre maggiore o uguale a quella dei suoi figli
Esempio - il pronto soccorso
Un esempio reale di coda con priorità è il triage ospedaliero. I codici colore rappresentano le priorità (chiavi):
- Bianco/Verde (codici bassi/meno urgenti).
- Giallo/Rosso (codici alti/urgenti). Se un paziente arriva in codice giallo, supera automaticamente tutti quelli in attesa con codice verde, indipendentemente da quanto tempo stiano aspettando. La fila viene rispettata solo tra pazienti con lo stesso codice.
Confronto con altre implementazioni delle code con priorità
Specifiche iniziali
Per capire perché nasce lo heap dobbiamo prima fare un’analisi di come le varie strutture dati si comportano (in termini di complessità algoritmica) quando si lavora con una coda con priorità. Un implementazione di una coda con priorità deve avere necessariamente i seguenti metodi:
- Inserimento: Aggiungere un nuovo elemento.
- Estrazione (del minimo): Rimuovere e restituire l’elemento prioritario.
- Decremento (Decrease Key): Aumentare la priorità di un elemento e quindi diminuire il valore della sua chiave
- Minimo: Consultare l’elemento prioritario senza estrarlo.
Le analisi successive verranno fatte supponendo nodi
Vs Array Disordinato
- Inserimento: . Basta mettere l’elemento nella prima posizione libera
- Estrazione/Minimo: . Bisogna scorrere tutto l’array per trovare il valore più piccolo.
- Decremento: se abbiamo il puntatore all’elemento, ma non aiuta l’estrazione successiva.
Vantaggio: Inserimento immediato. Svantaggio: Costo lineare per trovare il minimo, inaccettabile per code frequenti.
Vs Array Ordinato
- Minimo: . Il minimo è sempre in prima posizione (o ultima, a seconda dell’ordinamento).
- Inserimento: . Per inserire un valore e mantenere l’ordine, bisogna “shiftare” (spostare) tutti gli elementi successivi.
- Estrazione: . Anche togliendo il primo elemento, bisogna riorganizzare l’array (shift verso sinistra).
Vantaggio: Accesso rapido al minimo. Svantaggio: Inserimento ed estrazione costosi.
Vs Alberi Binari di Ricerca Bilanciati (BBST)
Utilizzando un BBST (Balanced Binary Search Tree), l’altezza dell’albero è garantita essere logaritmica ().
- Tutte le operazioni (Inserimento, Estrazione, Ricerca, Decremento): .
Sebbene sia ottimo i BBST sono strutture complesse da implementare e mantenere (richiedono puntatori e ribilanciamenti).
L’obiettivo dello Heap è ottenere le stesse prestazioni asintotiche dei BBST () ma con una struttura molto più semplice, gestibile tramite un array e senza l’uso esplicito di puntatori.
Come è fatto uno Heap
Introduzione
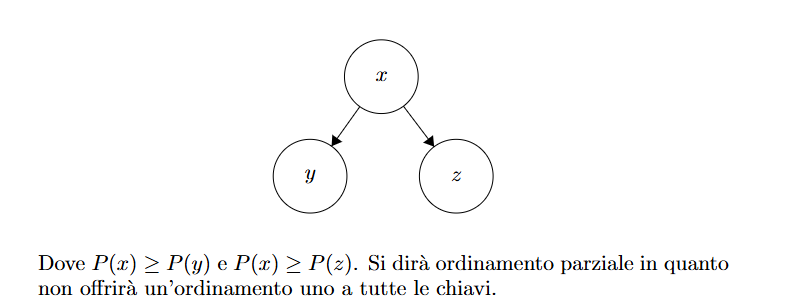
Un heap è un albero binario completo dove a differenza di un BST (dove tutto il sottoalbero sinistro è minore del nodo e tutto il destro è maggiore), nello Heap c’è solo una relazione verticale:
Non c’è alcuna relazione d’ordine specifica tra fratello destro e fratello sinistro. Questo è definito ordinamento parziale.
Tipi di Heap
Esistono due varianti di Heap, simmetriche tra loro:
- Min Heap: La chiave di un nodo è sempre minore o uguale a quella dei suoi figli. La radice contiene il minimo assoluto.
- Max Heap: La chiave di un nodo è sempre maggiore o uguale a quella dei suoi figli. La radice contiene il massimo.
Operazioni sullo Heap
Di seguito la complessità e le implementazioni delle varie funzionalità di uno heap.
Minimo
Poiché usiamo un Min Heap, il minimo si trova sempre alla radice. Costo: (Accesso diretto all’indice 1 dell’array). Nota: la stessa cosa vale per il massimo in un MaxHeap
Decrease Key (Decremento di una chiave)
Se riduciamo il valore di una chiave (es. un nodo passa da 7 a 1), potremmo violare la proprietà dello heap (il figlio diventa più piccolo del padre). Procedura:
- Si aggiorna il valore.
- Si confronta il nodo con il padre.
- Se il nodo è minore del padre, si scambiano (swap).
- Si ripete il procedimento risalendo verso la radice finché la proprietà non è ripristinata o si raggiunge la radice.
Costo: Nel caso peggiore si risale tutta l’altezza dell’albero. .
DECREASE-KEY(H,x,k)
key(x) = k
p = parent(x)
while(p != NULL and key(p)>key(x)) do
swap(x,p)
x = p
p = parent(x)
Inserimento
L’inserimento sfrutta la logica del Decrease Key:
- Inseriamo il nuovo nodo con valore nella prima posizione libera
- Poi facciamo una Decrease Key al nodo inserito con il suo valore reale.
- L’elemento “risale” (bubble-up) fino alla sua posizione corretta.
Costo: Proporzionale all’altezza dell’albero. .
INSERT(H,k)
x = new node(H)
key(x) = k
p = parent(x)
while(p != NULL and key(p)>key(x)) do
swap(x,p)
x = p
p = parent(x)
Procedura Heapify(i):
Si applica a un nodo assumendo che i sottoalberi sinistro e destro siano già heap validi.
- Confronto la chiave di con il figlio sinistro () e il figlio destro ().
- Individuo il più piccolo tra , e .
- Se il minimo non è , scambio con il figlio minore.
- Chiamo ricorsivamente Heapify sul figlio appena scambiato.
Analisi della complessità di Heapify: L’equazione di ricorrenza (nel caso peggiore su un albero quasi completo) è approssimabile dal Teorema Master (Caso 2): Il fattore deriva dal fatto che, in un albero non perfettamente bilanciato nell’ultimo livello, il sottoalbero più grande può contenere circa i 2/3 dei nodi totali. Tuttavia, la complessità rimane legata all’altezza: .
HEAPIFY(H,x)
y = left(x)
z = right(x)
min = x
IF y != NULL AND key(y)<key(x)
min = y
IF y \neq NULL AND key(z)<key(min)
min = z
IF min != x
swap(x, min)
heapify(H,min)
Estrazione del Minimo
Per estrarre il minimo (la radice), non possiamo lasciare un buco.
- Prendiamo l’ultimo elemento dell’array (quello più in basso a destra) e lo spostiamo alla radice al posto del minimo rimosso.
- Ora la struttura è integra, ma l’ordinamento è violato (un elemento grande è in testa).
- Bisogna far “scendere” questo elemento nella posizione corretta e lo facciamo usando la funzione heapify. Costo: richiamando heapify questa procedura costa .
Heap usando un array
Il vero segreto dello Heap è che può essere implementato facilmente usando un array, eliminando la necessità di puntatori. E lo si fa usando le seguenti convenzioni:
- La radice è all’indice (o , a seconda dell’implementazione; qui useremo l’indice 1 per semplificare le formule).
- Dato un nodo all’indice :
- Il figlio sinistro (Left) si trova a .
- Il figlio destro (Right) si trova a .
- Il genitore (Parent) si trova a .
Queste operazioni possono essere eseguite in modo estremamente efficiente tramite operazioni bitwise (shift dei bit):
- Moltiplicare per 2 corrisponde a uno shift a sinistra (
i << 1). - Dividere per 2 corrisponde a uno shift a destra (
i >> 1).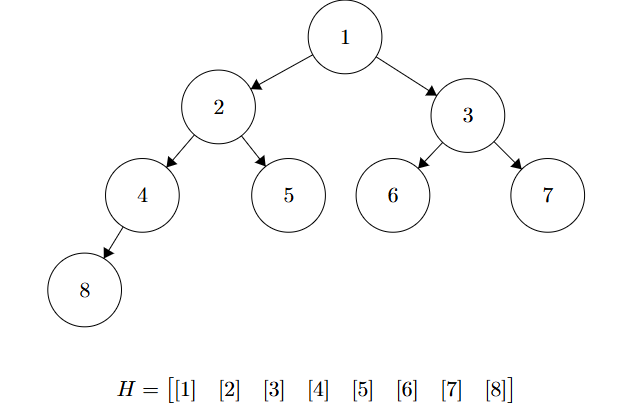 Di seguito tutte le funzioni ridefinite per l’implementazione sottoforma di array del heap
Di seguito tutte le funzioni ridefinite per l’implementazione sottoforma di array del heap
Funzioni left, right, parent
int left(int i){
return (2*i)+1; //Mettiamo +1 perché gli array partono da 0
}
int right(int i){
return (2*i)+2;
}
int parent(int i){
return (i-1)/2;
}Heapify
void min_heapify(int i){
int l = left(i);
int r = right(i);
int min = i;
if(l < size && array[l] < array[min]) min = l;
if(r < size && array[r] < array[min]) min = r;
if(min != i){
int scambio = array[i];
array[i] = array[min];
array[min] = scambio;
min_heapify(min);
}
}
void max_heapify(int i){
int l = left(i);
int r = right(i);
int max = i;
if(l < size && array[l] > array[max]) max = l;
if(r < size && array[r] > array[max]) max = r;
if(max != i){
int scambio = array[i];
array[i] = array[max];
array[max] = scambio;
heapify(max);
}
}
Insert
void insert(int k){
array[size++] = k;
int i = size - 1;
int p = parent(i);
//Questa insert mantiene una struttura max-heap, per min-heap modificare in: array[p]>array[i]
while(i>0 && array[p]<array[i]){
int scambio = array[i];
array[i] = array[p];
array[p] = scambio;
i = p;
p = parent(i);
}
}Extract-min
int extractMax(){
int max = array[0];
int scambio = array[0];
array[0] = array[size-1];
array[size-1] = scambio;
size--;
max_heapify(0);
return max;
}Costruzione dello Heap
Come si costruisce uno heap partendo da un array disordinato di elementi? di seguito due metodi per farlo
Metodo 1: Inserimenti successivi
Possiamo inserire gli elementi uno alla volta in uno heap vuoto (usando la funzione insert). Poiché ogni inserimento costa , per elementi il costo totale è:
Metodo 2: Procedura Build-Min-Heap (Ottimizzata)
Esiste un metodo più efficiente che sfrutta la struttura. Prendiamo l’array così com’è e chiamiamo Heapify a ritroso, partendo dall’ultimo nodo interno fino alla radice.
Algoritmo:
FOR i = floor(n/2) DOWN TO 1:
Min-Heapify(array, i)In pratica, sistemiamo prima i sottoalberi piccoli in basso, poi quelli medi, e infine la radice.
Analisi della complessità A prima vista potrebbe sembrare perché chiamiamo Heapify volte. Tuttavia, l’altezza dei nodi varia:
- La maggior parte dei nodi è vicino al fondo (altezza bassa, costo Heapify basso).
- Pochissimi nodi sono in alto (altezza ).
La somma dei costi è data dalla serie: Poiché la serie converge a una costante, il costo totale è: Costruire uno heap da zero quindi richiede tempo lineare.
Metodo 3: procedura Build-Max-Heap
Questa procedura è uguale a quella del min-heap ma richiamiamo max-heapify
void buildMaxHeap(){
for(int i = size/2-1; i >= 0; i--){
max_heapify(i);
}
}Heapsort
Analisi
Prendendo in esame il selection sort, capiamo subito che il problema principale di questo tipo di algoritmo è il tempo perso durante la ricerca del massimo, cosa che in un max-heap facciamo in tempo , da qui nasce l’heapsort
Algoritmo e implementazione
L’algoritmo heapsort inizia utilizzando Build-max-heap per costruire un max-heap nella array in input, l’elemento più grande è memorizzato nella radice, quindi ci basta scambiarlo con l’ultimo elemento nell’array per ordinarlo, poi richiamiamo max-heapify sull’array ma escludendo gli elementi ordinati, facendo questa cosa per ogni elemento otteniamo il nostro array ordinato.
void HeapSort(){
buildMaxHeap();
int len = size;
for(int i = len-1; i > 2; i--){
int scambio = array[i];
array[i] = array[0];
array[0] = scambio;
size--;
max_heapify(0);
}
size = len; //Nell'implementazione fatta serve per stampare il lo heap
}Questo algoritmo ha complessità
Esami
Nel file 6 - 29 ottobre 2025.pdf ci sono alla fine degli esempi di esercizi di esame:
- Effettuare 13 estrazioni del minimo e mostrare cosa succede al nostro array
- Scrivere la procedura HeapMerge
- Scrivere la procedura ListMerge che segua delle regole specifiche
- Top-ten di punteggi più alti
- ecc…
Limiti degli ordinamenti con confronti
Albero di decisione
Definizione
Gli ordinamenti per confronti possono essere visti in modo astratto come degli alberi di decisione. Un albero di decisione è un albero binario pieno che rappresenta i confronti fra elementi fatti in un particolare algoritmo preso in esame.
Esempio
Attraverso un esempio è abbastanza intuitivo capire come funziona un albero di decisione:
Con abbiamo un albero di decisione del tipo: 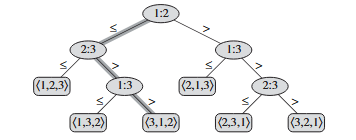 Notiamo subito che il caso peggiore nell’ordinamento corrisponde all’altezza di questo albero
Notiamo subito che il caso peggiore nell’ordinamento corrisponde all’altezza di questo albero
Teorema e dimostrazione
Teorema
Qualsiasi algoritmo di ordinamento per confronti richiede
Dimostrazione
Come abbiamo visto nell’esempio dell’albero di decisione ci basta determinare l’altezza di un albero ogni dove possibile permutazione degli elementi compare come foglia. Consideriamo quindi un albero di decisione:
- elementi da ordinare
- altezza
- numero di foglie ciascuna delle permutazioni dell’input compare in una foglia, si ha quindi . Dal momento che un albero binario di altezza non ha più di foglie si ha: da questo estraiamo: che ci indica una complessità di
Conclusioni
Da questo capiamo che algoritmi come heapSort e MergeSort sono ottimi algoritmi di ordinamento usando i confronti