Tabelle Hash
Introduzione alle Hash table
Introdurremo il concetto di Tabella Hash partendo da un problema di implementazione: dobbiamo implementare un dizionario. Quale è il modo migliore di farlo?
Cos’è un dizionario?
Un dizionario è un insieme su cui possiamo effettuare operazioni di:
- inserimento
- cancellazione
- ricerca Questa struttura dati viene usata principalmente per la ricerca. La ricerca di un elemento in un dizionario può portare a due esiti differenti:
- Ricerca con successo: ricerca di un elemento presente nella tabella
- Ricerca senza successo: ricerca di un elemento non-presente nella tabella.
Possibili implementazioni e complessità con strutture già note
- Array non-ordinato:
- Inserimento:
- Cancellazione:
- Ricerca:
- Array ordinato:
- Inserimento:
- Cancellazione:
- Ricerca: Ricerca Binaria
- Lista non-ordinata:
- Inserimento:
- Cancellazione:
- Ricerca:
- Lista ordinata:
- Inserimento:
- Cancellazione:
- Ricerca:
- BST:
- Inserimento:
- Cancellazione:
- Ricerca:
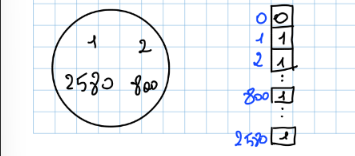
- Tabella a Indirizzamento Diretto:
- Inserimento:
- Cancellazione:
- Ricerca:
Tabelle a Indirizzamento Diretto
Definizione
Una tabella a indirizzamento diretto è una soluzione molto conveniente, nei casi in cui l’insieme universo (l’insieme di tutti i numeri registrabili) è un insieme relativamente piccolo. Una tabella a indirizzamento diretto avrà uno slot per ogni elemento . Ad ogni elemento è associata una chiave , ovvero un indice della tabella a indirizzamento diretto.
Implementazione
Inserimento:
Insert(T,k)
T[k] = 1
Rimozione:
Insert(T,k)
T[k] = 0
Ricerca:
Search(T,k)
IF T[k]=1
RETURN true
ELSE RETURN false
Hanno tutte complessità
Svantaggi di questa struttura
Apparentemente, le tabelle a indirizzamento diretto sono perfette; tuttavia, esistono dei casi in cui non sono veramente consone, e in cui anzi, non possono essere proprio utilizzate:
- Insieme U molto grande rispetto a K: se l’insieme universo è molto grande, ma l’insieme delle chiavi da memorizzare è piccolo, la memoria da allocare sarà quasi del tutto sprecata.
- L’insieme universo è infinito. Un calcolatore non ha memoria infinita, e una tabella a indirizzamento diretto ha bisogno di un numero finito di indici.
Per risolvere questi problemi e poter utilizzare le tabelle ad indirizzamento diretto e quindi i dizionari nascono le funzioni di hash, una funzione che assegna ad un valore una specifica chiave.
Funzione hashing
Definizione
Il ruolo della funzione hashing (detta ) è quello di associare ad un elemento dell’insieme , un indice della tabella hash. In questo modo lo spazio richiesto da una tabella Hash (una tabella ad indirizzamento diretto ma che usa l’hashing) sarà ridotto a , quindi sarà uguale al numero di chiavi da memorizzare, molto di meno rispetto a , riuscendo a conservare i vantaggi di una tabella ad indirizzamento diretto (ovvero la ricerca in )
Collisioni
La funzione , avendo solitamente un codominio di cardinalità inferiore al dominio, non è una funzione biunivoca. Per il pigeonhole principle, se gli elementi da inserire nella Hash Table sono più degli indirizzi, almeno due chiavi finiranno allo stesso indirizzo. Quando due chiavi finiscono nella stessa cella, abbiamo un fenomeno chiamato collisione, dall’evitare le collisioni nascono tutti modi per implementare una tabella hash.
Implementazioni delle tabelle hash
Data una chiave sono tanti i metodi che possiamo utilizzare per indirizzare, di seguito ne vediamo alcuni.
Metodo della divisione
Dati:
- ,
-
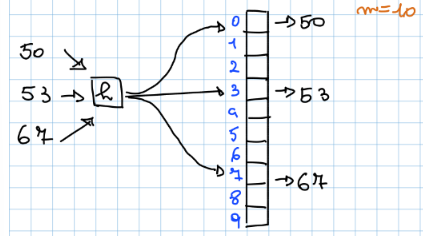 Quando utilizziamo questo metodo evitiamo certi valori di , per esempio non può essere una potenza di , perché se allora durante la creazione delle chiave si baserà solo sui meno significativi e non su tutto il valore creando poca uniformità.
Quando utilizziamo questo metodo evitiamo certi valori di , per esempio non può essere una potenza di , perché se allora durante la creazione delle chiave si baserà solo sui meno significativi e non su tutto il valore creando poca uniformità.

Metodo della moltiplicazione
Dati:
- e Spieghiamo il principio di di questo metodo:
- ci ritorna un valore compreso tra 0 e .
- Il resto della divisione per 1 con un numero reale, ritornerà il valore della parte decimale, ottenendo un valore compreso tra 0 e 1, 1 escluso.
- Moltiplicando per , otteniamo valori compresi tra 0 e , escluso.
- La funzione floor ci permette di prendere solo la parte intera In questo metodo il valore di non è critico come prima, solitamente scegliamo una potenza di perché rende più veloce l’implementazione nei calcolatori moderni
Risolviamo le collisioni usando l’hashing con concatenazione
Definizione
Nell’hashing con concatenazione poniamo tutti gli elementi che sono associati alla stessa cella in una lista concatenata. Praticamente la cella contiene un puntatore alla testa della list adi tutti gli elementi memorizzati che vengono mappati in ; se non c’è ne sono, la cella contiene la costante
Implementazioni
Inserimento:
Insert(T,k)
List-Insert(T[h(k)], k)
Costo: avrà come l’inserimento in lista.
Rimozione:
Insert(T,k)
List-Delete(T[h(k)], k)
Costo: avrà come la cancellazione dalla lista.
Ricerca:
Search(T,k)
RETURN List-Search(T[h(k)], k)
Costo: Il caso peggiore sarà quello in cui ogni elemento è inserito nella stessa posizione della tabella. , come la ricerca in una lista di elementi. Andiamo a studiare tuttavia il caso medio, introducendo il concetto di uniformità.
Analisi
Attention
Data una tavola hash con celle dove sono memorizzati elementi, definiamo fattore di carico della tavola il rapporto , ossia il numero medio di elementi che memorizzati in una lista, la nostra analisi sarà fatta in funzione di che può essere minore, uguale o maggiore di .
Caso peggiore: il comportamento nel caso peggiore dell’hashing con concatenamento è pessimo, tutte le chiavi vengono associate alla stessa cella, quindi stiamo lavorando praticamente con una lista, con tutte le inefficienze del caso ovvero: Ricerca in
Caso medio: il comportamento nel caso medio dipende dal modo in cui la funzione hash distribuisce mediamente l’insieme delle chiavi da memorizzare tra le celle. Per adesso supponiamo che qualsiasi elemento abbia la stessa probabilità di essere mandato in un qualsiasi posizione. Questa ipotesi si chiama Hashing uniforme semplice. Se indichiamo con la lunghezza della lista per avremo da questo possiamo dire che la lunghezza media delle liste è: per fare un’analisi della complessità dobbiamo necessariamente distinguere due casi:
- Ricerca senza successo: una ricerca senza successo richiede un tempo di nel caso medio Dimostrazione: Il tempo atteso per ricercare senza successo una chiave è il tempo atteso per svolgere ricerche fino alla fine della lista che ha lunghezza attesa di quindi il tempo totale richiesto (incluso quello per calcolare che ipotizziamo sia ) è
- Ricerca con successo: una ricerca con successo richiede un tempo di nel caso medio
Dimostrazione: il numero di elementi esaminati durante una ricerca con successo di un elemento è uno in più del numero di elementi che si trovano prima di nella lista di . Gli elementi prima di li troviamo facendo: Ricordiamo che . Dunque il numero atteso di elementi esaminati con successo è:Di seguito la risoluzione:
- Distribuiamo la sommatoria dentro la parentesi e sostituiamo :
- Riscrivo la prima sommatoria semplicemente come e sposto fuori la costante :
- Riscrivo la sommatoria con come :
- Riscrivo le sommatorie come differenza di sommatorie
- Risolvo le sommatorie
- Risolvo i calcoli rimanenti
Risolviamo le collisioni usando l’hashing a indirizzamento aperto
Definizione
Un altro metodo che permette di risolvere le collisioni, è l’indirizzamento aperto. Supponiamo di avere una tabella con un numero di slot. Se cercando di effettuare un inserimento nella tabella, la posizione calcolata dalla funzione di hashing risulta già occupata, verrà calcolato e ispezionato un altro slot. Ciò avverrà fino a quando non si troverà uno slot libero (contenente NULL o D, ne parleremo dopo), o fino a quando non si saranno controllati tutti gli slot della tabella.
Sequenza di ispezione
La funzione di hashing all’interno di una tabella con indirizzamento aperto al posto di ritornare una singola posizione, sarà così definita: Definiamo sequenza di ispezione di una chiave , la sequenza di indici che viene generata dalla funzione di hashing calcolata su , ovvero: La sequenza di ispezione conterrà tutti gli slot della tabella e rappresenta tutte le possibili posizioni che potrebbe prendere se non sono occupate.
Implementazioni funzioni di base
Inserimento
hash_insert(T, k)
IF n = m
RETURN // tabella piena
i = 0
WHILE (T[h(k, i)] != NULL AND T[h(k, i)] != D): //D spiegato in "Funzione di cancellazione"
i = i + 1
T[h(k, i)] = k
n = n + 1
Ricerca
hash_search(T, k)
i = 0
WHILE T[h(k, i)] != NULL AND i < m:
IF T[h(k, i)] = k
RETURN True
i++
RETURN False
Funzione di cancellazione
La funzione di cancellazione, all’interno di una tabella hash che risolve le collisioni tramite l’indirizzamento aperto, richiederà una modifica fondamentale per il funzionamento corretto della funzione di ricerca. Cancellato un elemento dalla tabella, esso non dovrà essere sostituito da NULL. Esso dovrà infatti essere contrassegnato come D di DELETED. L’esempio di seguito aiuta a capire perché usiamo
Esempio:
- Prendiamo una tabella hash con contiene i numeri .
- Eliminiamo il numero 3 dalla tabella, ottenendo .
- Calcoliamo la sequenza di ispezione della chiave 5 che sarebbe:
- Supponiamo adesso di usare la funzione di ricerca per verificare la presenza (evidente) del numero 5
La ricerca si interromperà a . Ciò non sarebbe avvenuto prima dell’eliminazione del numero 3, ed è causato proprio dal NULL in posizione 2.
Contrassegnare lo slot con DELETED espliciterà il fatto che lo slot è libero in caso di inserimento, ma anche che la ricerca non andrà interrotta nonostante lo slot vuoto.
hash_delete(T, k)
i <- 0
WHILE (T[h(k, i)] != NULL AND i < m):
IF T[h(k, i)] = k:
T[h(k, i)] = DELETED
RETURN True
i = i + 1
RETURN False
Essendo l’eliminazione abbastanza macchinosa usiamo l’indirizzamento aperto solo quando non dobbiamo eliminare elementi.
Requisiti di una funzioni hash per indirizzamento aperto
Dati:
- è l’insieme di tutte le permutazioni sull’insieme .
- La cardinalità di è . Sia una permutazione. La probabilità che deve essere la stessa per qualsiasi permutazione. Questa ipotesi si chiama hashing uniforme. Costruire funzioni hash per l’indirizzamento aperto che rispettino questa proprietà è piuttosto complesso. Successivamente vengono analizzate tre tecniche usate per creare la sequenza di ispezione
Analisi
La nostra analisi dell’indirizzamento aperto è espressa in termini del fattore di carico . Supponiamo venga applicata l’hashing uniforme quindi la sequenza utilizzata per inserire o ricercare una chiave ha la stessa probabilità di essere una qualsiasi permutazione di . Analizziamo di seguito il numero atteso di ispezioni dell’hashing con indirizzamento aperto, facendo differenza tra una ricerca con e senza successo:
Ricerca senza successo: data una tavola hash con un fattore di carico il numero atteso di ispezioni in una ricerca senza successo è al massimo
Dimostrazione:  Tips:
Tips:
- Regola del valore atteso: Il calcolo iniziale si basa sulla regola statistica per cui il numero atteso di ispezioni equivale alla somma delle probabilità di farne almeno .
- Significato pratico degli eventi: La lunga serie di probabilità condizionate calcola un evento molto specifico: la probabilità di eseguire ispezioni consecutive e di trovare sempre slot già occupati nella tavola.
- Origine della disuguaglianza: La serie di frazioni è strettamente decrescente. Poiché ogni termine è minore o uguale al primo (), il prodotto di questi termini è matematicamente .
- Conversione in serie geometrica: Per risolvere la sommatoria , basta sostituire con e far partire l’indice da anziché da . Diventa così la serie geometrica standard , che per converge a .
Ricerca con successo: data una tavola hash con un fattore di carico il numero atteso di ispezioni in una ricerca senza successo è al massimo
Dimostrazione: 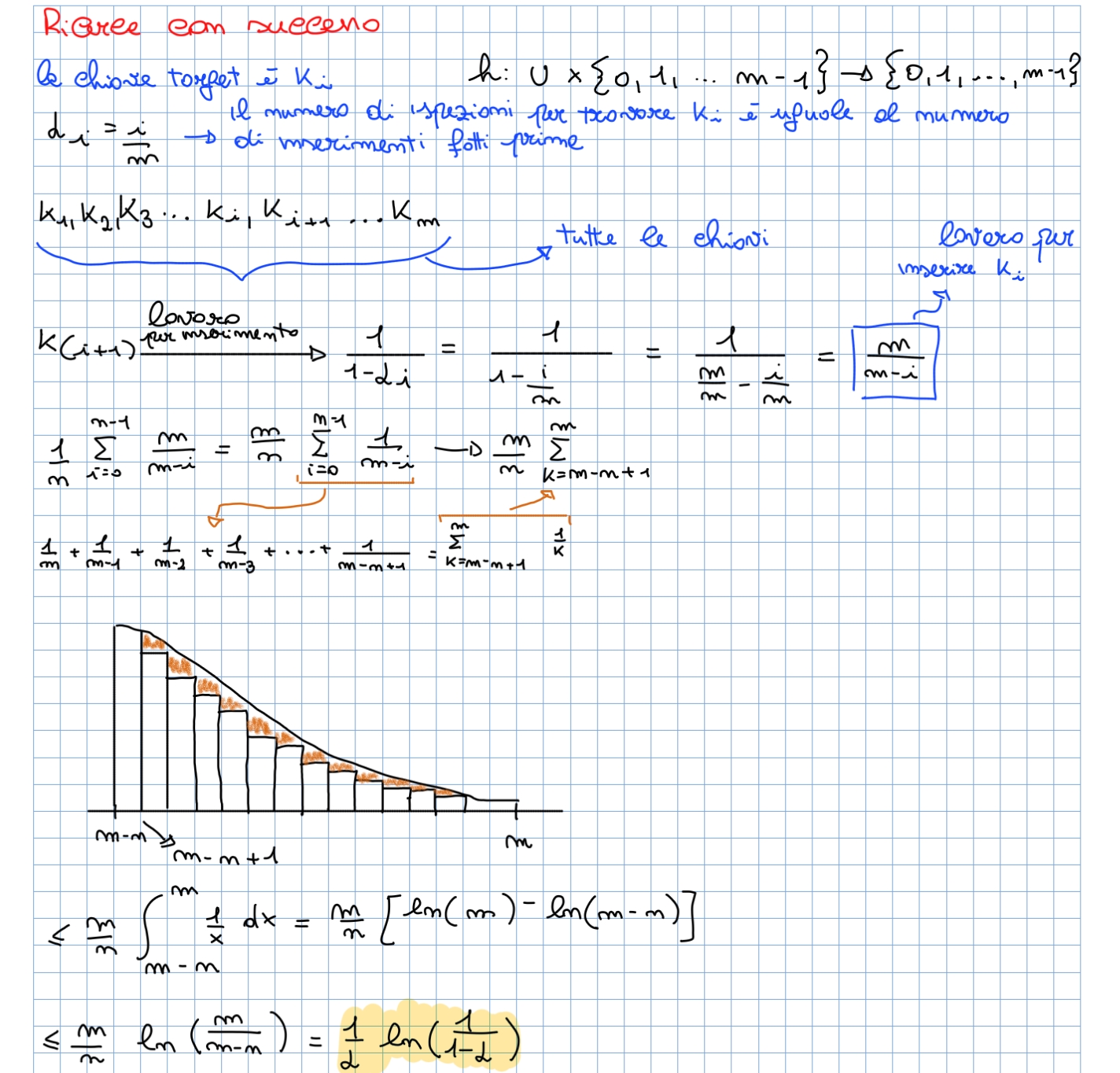
Tecniche per creare una sequenza di ispezione
Ispezione lineare
La funzione di hashing per la scansione lineare è definita in questo modo
Con . Le sequenze della nostra funzione di hashing saranno del tipo
Questa funzione di hashing non gode della proprietà di hashing uniforme, in quanto, le permutazioni ottenute non possono non iniziare con . Moltissime permutazioni avranno probabilità , e le restanti . Un’altro problema di questo tipo di ispezione è l’agglomerazione primaria. In breve, la probabilità che le chiavi siano inserite in slot successivi aumenta ad ogni inserimento, favorendo agglomerati di chiavi e allungando le tempistiche relative alle operazioni.
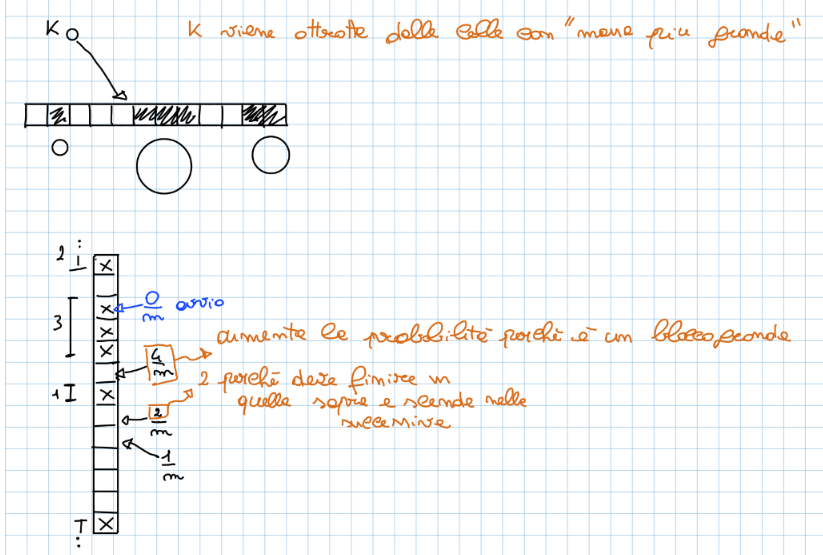
Ispezione quadratica
Cambia solo la funzione di hashing e diventa: Con e costanti scelte in modo tale che l’intera tabella venga scansionata dalla funzione ed evitare l’agglomerazione primaria.
Ispezione doppio hashing
In questa funzione vengono usate due funzione di hashing: Il numero totale di permutazioni totale è , in quanto la prima funzione di hashing da la prima posizione, la seconda le successive, e quindi possibili posizioni dopo altre .