- Introduzione alla ricorsione 1. La ricorsione 2. Fasi della ricorsione 3. Definizioni ricorsive delle strutture dati 4. Struttura generale di un programma ricorsivo 5. Dimensione del problema 6. L’equazione di ricorrenza 7. Costruzione di una equazione di ricorrenza
- Applicazioni pratiche della ricorsione 1. Il fattoriale 2. Moltiplicazione come somma ripetuta 3. Potenza con moltiplicazione ripetuta
- Problemi di somma e soglia su array 1. Premessa 2. Somma dei valori di un array 3. Verificare se la somma supera una soglia
- Approccio ricorsivo e iterativo 1. Analisi 2. Versione 0.1: pesi unitari, valori diversi 3. Versione generale 0/1: pesi e valori variabili 4. Esercizi sulla ricorsione
- Concetti preliminari di analisi asintotica 1. Confronto tra le principali funzioni di crescita 2. Confronto tra le principali funzioni di crescita 3. Termini e fattori dominanti e trascurabili
- Le notazioni asintotiche 1. La notazione Θ (theta) 2. La notazione O (Big-Oh) 3. La notazione Ω (Big-Omega) 4. Le notazioni o e ω (piccole) 5. Conclusioni sulle notazioni asintotiche
- Oltre i casi limite 1. Cosa accade davvero in pratica 2. Quando le costanti contano
- Introduzione alle equazioni di ricorrenza 1. Definizione 2. Risoluzione dell’equazione di ricorrenza
- Identificare l’equazione di ricorrenza 1. Fasi della ricorsione 2. Esempio - Ricerca binaria
- Ricorrenze non uniformi 1. Esempio - QuickSort 2. Analisi
- Il metodo dell’albero di ricorsione 1. Notazione 2. Analisi 3. Esempi
- Il metodo della sostituzione 1. Definizione 2. Step da seguire 3. Esempi
- Metodo basato sul teorema Master 1. Definizione 2. Enunciato del teorema Master 3. Interpretazione intuitiva 4. Confronto tra funzioni 5. Esempi
- Introduzione 1. Caratteristiche principali 2. Esempio - il pronto soccorso
- Confronto con altre implementazioni delle code con priorità 1. Specifiche iniziali 2. Vs Array Disordinato 3. Vs Array Ordinato 4. Vs Alberi Binari di Ricerca Bilanciati (BBST)
- Come è fatto uno Heap 1. Introduzione 2. Tipi di Heap
- Operazioni sullo Heap 1. Minimo 2. Decrease Key (Decremento di una chiave) 3. Inserimento 4. Procedura Heapify(i): 5. Estrazione del Minimo
- Heap usando un array 1. Funzioni left, right, parent 2. Heapify 3. Insert 4. Extract-min
- Costruzione dello Heap 1. Metodo 1: Inserimenti successivi 2. Metodo 2: Procedura Build-Min-Heap (Ottimizzata) 3. Metodo 3: procedura Build-Max-Heap
- Heapsort 1. Analisi 2. Algoritmo e implementazione
- Esami
- Limiti degli ordinamenti con confronti
- [[#Limiti degli ordinamenti con confronti#Albero di decisione|Albero di decisione]] 1. Definizione 2. Esempio
- [[#Limiti degli ordinamenti con confronti#Teorema e dimostrazione|Teorema e dimostrazione]] 1. Teorema 2. Dimostrazione 3. Conclusioni
- [[#Limiti degli ordinamenti con confronti#Counting sort|Counting sort]] 1. Premesse 2. Algoritmo 3. Implementazione 4. Complessità
- [[#Limiti degli ordinamenti con confronti#Radix sort|Radix sort]] 1. Premesse 2. Algoritmo 3. Implementazione 4. Complessità
- [[#Limiti degli ordinamenti con confronti#Introduzione alle Hash table|Introduzione alle Hash table]] 1. Cos’è un dizionario? 2. Possibili implementazioni e complessità con strutture già note
- [[#Limiti degli ordinamenti con confronti#Tabelle a Indirizzamento Diretto|Tabelle a Indirizzamento Diretto]] 1. Definizione 2. Implementazione 3. Svantaggi di questa struttura
- [[#Limiti degli ordinamenti con confronti#Funzione hashing|Funzione hashing]] 1. Definizione 2. Collisioni
- [[#Limiti degli ordinamenti con confronti#Implementazioni delle tabelle hash|Implementazioni delle tabelle hash]] 1. Metodo della divisione 2. Metodo della moltiplicazione
- [[#Limiti degli ordinamenti con confronti#Risolviamo le collisioni usando l’hashing con concatenazione|Risolviamo le collisioni usando l’hashing con concatenazione]] 1. Definizione 2. Implementazioni 3. Analisi
- [[#Limiti degli ordinamenti con confronti#Risolviamo le collisioni usando l’hashing a indirizzamento aperto|Risolviamo le collisioni usando l’hashing a indirizzamento aperto]] 1. Definizione 1. Sequenza di ispezione 1. [[#Sequenza di ispezione#Implementazioni funzioni di base|Implementazioni funzioni di base]] 2. Funzione di cancellazione 1. [[#Funzione di cancellazione#Requisiti di una funzioni hash per indirizzamento aperto|Requisiti di una funzioni hash per indirizzamento aperto]] 2. [[#Funzione di cancellazione#Analisi|Analisi]]
- [[#Limiti degli ordinamenti con confronti#Tecniche per creare una sequenza di ispezione|Tecniche per creare una sequenza di ispezione]] 1. [[#Funzione di cancellazione#Ispezione lineare|Ispezione lineare]] 2. [[#Funzione di cancellazione#Ispezione quadratica|Ispezione quadratica]] 3. [[#Funzione di cancellazione#Ispezione doppio hashing|Ispezione doppio hashing]]
- [[#Limiti degli ordinamenti con confronti#Alberi bilanciati|Alberi bilanciati]] 1. [[#Funzione di cancellazione#Definizione di albero bilanciato|Definizione di albero bilanciato]] 2. [[#Funzione di cancellazione#Ripasso proprietà del BST|Ripasso proprietà del BST]]
- [[#Limiti degli ordinamenti con confronti#Proprietà di una albero rosso-nero|Proprietà di una albero rosso-nero]] 1. [[#Funzione di cancellazione#Proprietà di un albero rosso-nero|Proprietà di un albero rosso-nero]] 2. [[#Funzione di cancellazione#Rappresentazione di un albero rosso-nero|Rappresentazione di un albero rosso-nero]] 3. [[#Funzione di cancellazione#Definizione altezza nera lemma altezza massima|Definizione altezza nera lemma altezza massima]]
- [[#Limiti degli ordinamenti con confronti#Operazioni negli alberi rosso-neri: rotazioni|Operazioni negli alberi rosso-neri: rotazioni]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Esempi|Esempi]]
- [[#Limiti degli ordinamenti con confronti#Operazioni negli alberi rosso-neri: inserimento|Operazioni negli alberi rosso-neri: inserimento]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Definizione di insert-fixup|Definizione di insert-fixup]] 3. [[#Funzione di cancellazione#Esempio|Esempio]]
- [[#Limiti degli ordinamenti con confronti#Operazioni negli alberi rosso-neri: eliminazione|Operazioni negli alberi rosso-neri: eliminazione]] 1. [[#Funzione di cancellazione#Ripasso rimozione negli alberi BST|Ripasso rimozione negli alberi BST]] 2. [[#Funzione di cancellazione#Definizione|Definizione]] 3. [[#Funzione di cancellazione#Definizione delete-fixup|Definizione delete-fixup]]
- [[#Limiti degli ordinamenti con confronti#Introduzione|Introduzione]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Sviluppare un algoritmo di programmazione dinamica|Sviluppare un algoritmo di programmazione dinamica]]
- [[#Limiti degli ordinamenti con confronti#Fibonacci|Fibonacci]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Analisi|Analisi]]
- [[#Limiti degli ordinamenti con confronti#Rod-cutting|Rod-cutting]] 1. [[#Funzione di cancellazione#Definzione|Definzione]] 2. [[#Funzione di cancellazione#Generalizzando|Generalizzando]] 3. [[#Funzione di cancellazione#Implementazione bottom-up del ROD-CUT con memorizzazione|Implementazione bottom-up del ROD-CUT con memorizzazione]] 4. [[#Funzione di cancellazione#Sottostruttura ottima|Sottostruttura ottima]]
- [[#Limiti degli ordinamenti con confronti#Ottimizzazione della moltiplicazione tra matrici|Ottimizzazione della moltiplicazione tra matrici]] 1. [[#Funzione di cancellazione#Definizione della moltiplicazione tra matrici|Definizione della moltiplicazione tra matrici]] 2. [[#Funzione di cancellazione#Analizziamo la complessità|Analizziamo la complessità]] 3. [[#Funzione di cancellazione#Fasi della programmazione dinamica|Fasi della programmazione dinamica]] 4. [[#Funzione di cancellazione#Complessità|Complessità]]
- [[#Limiti degli ordinamenti con confronti#Distanza di Editing|Distanza di Editing]] 1. [[#Funzione di cancellazione#Introduzione al Problema|Introduzione al Problema]] 2. [[#Funzione di cancellazione#Definizione Formale e Ricorsiva|Definizione Formale e Ricorsiva]] 3. [[#Funzione di cancellazione#Programmazione Dinamica|Programmazione Dinamica]] 4. [[#Funzione di cancellazione#Ricostruzione della Soluzione Ottima|Ricostruzione della Soluzione Ottima]]
- [[#Limiti degli ordinamenti con confronti#Longest Common Substring|Longest Common Substring]] 1. [[#Funzione di cancellazione#Sottostruttura ottima:|Sottostruttura ottima:]] 2. [[#Funzione di cancellazione#Definizione funzione ricorsiva:|Definizione funzione ricorsiva:]] 3. [[#Funzione di cancellazione#Soluzione con programmazione dinamica:|Soluzione con programmazione dinamica:]]
- [[#Limiti degli ordinamenti con confronti#Longest Common Subsequence (LCS)|Longest Common Subsequence (LCS)]] 1. [[#Funzione di cancellazione#Sottostruttura ottima|Sottostruttura ottima]] 2. [[#Funzione di cancellazione#Definizione funzione ricorsiva|Definizione funzione ricorsiva]] 3. [[#Funzione di cancellazione#Soluzione con programmazione dinamica|Soluzione con programmazione dinamica]]
- [[#Limiti degli ordinamenti con confronti#Introduzione|Introduzione]] 1. [[#Funzione di cancellazione#Definizione|Definizione]]
- [[#Limiti degli ordinamenti con confronti#Problema dello zaino|Problema dello zaino]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Dimostrazione scelta greedy|Dimostrazione scelta greedy]]
- [[#Limiti degli ordinamenti con confronti#Compressione di Huffman|Compressione di Huffman]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Come costruiamo le parole in codice|Come costruiamo le parole in codice]] 3. [[#Funzione di cancellazione#Codici prefissi|Codici prefissi]] 4. [[#Funzione di cancellazione#Costo di una codifica|Costo di una codifica]] 5. [[#Funzione di cancellazione#Dimostrazione della sottostruttura ottima|Dimostrazione della sottostruttura ottima]] 6. [[#Funzione di cancellazione#Implementazione|Implementazione]] 7. [[#Funzione di cancellazione#Scelta greedy|Scelta greedy]]
- [[#Limiti degli ordinamenti con confronti#Activity selector|Activity selector]] 1. [[#Funzione di cancellazione#Definizione del Problema|Definizione del Problema]] 2. [[#Funzione di cancellazione#Sottostruttura Ottima|Sottostruttura Ottima]] 3. [[#Funzione di cancellazione#La Scelta Golosa (Greedy Choice)|La Scelta Golosa (Greedy Choice)]] 4. [[#Funzione di cancellazione#Algoritmo Ricorsivo|Algoritmo Ricorsivo]] 5. [[#Funzione di cancellazione#Algoritmo Iterativo|Algoritmo Iterativo]]
- [[#Limiti degli ordinamenti con confronti#Proprietà dei grafi|Proprietà dei grafi]] 1. [[#Funzione di cancellazione#Definizione e proprietà|Definizione e proprietà]] 2. [[#Funzione di cancellazione#Cammino|Cammino]] 3. [[#Funzione di cancellazione#Cammino semplice|Cammino semplice]] 4. [[#Funzione di cancellazione#Grafo aciclico|Grafo aciclico]] 5. [[#Funzione di cancellazione#Grafo pesato|Grafo pesato]] 6. [[#Funzione di cancellazione#Ordinamento topologico|Ordinamento topologico]] 7. [[#Funzione di cancellazione#Componente connessa e fortemente connessa|Componente connessa e fortemente connessa]] 8. [[#Funzione di cancellazione#Rappresentazioni dei grafi|Rappresentazioni dei grafi]]
- [[#Limiti degli ordinamenti con confronti#BFS|BFS]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Implementazione|Implementazione]]
- [[#Limiti degli ordinamenti con confronti#DFS|DFS]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Premesse comuni alle implementazioni fatte|Premesse comuni alle implementazioni fatte]] 3. [[#Funzione di cancellazione#Prima implementazione|Prima implementazione]] 4. [[#Funzione di cancellazione#Seconda implementazione|Seconda implementazione]] 5. [[#Funzione di cancellazione#Terza implementazione|Terza implementazione]] 6. [[#Funzione di cancellazione#Etichette degli archi|Etichette degli archi]] 7. [[#Funzione di cancellazione#Per cosa usiamo la DFS|Per cosa usiamo la DFS]]
- [[#Limiti degli ordinamenti con confronti#Introduzione|Introduzione]] 1. [[#Funzione di cancellazione#Definizioni|Definizioni]] 2. [[#Funzione di cancellazione#Varianti di questo problema|Varianti di questo problema]]
- [[#Limiti degli ordinamenti con confronti#Proprietà dei cammini minimi|Proprietà dei cammini minimi]] 1. [[#Funzione di cancellazione#Sottostruttura ottima|Sottostruttura ottima]] 2. [[#Funzione di cancellazione#Archi di peso negativo e cicli|Archi di peso negativo e cicli]] 3. [[#Funzione di cancellazione#Rilassamento dei cammini minimi|Rilassamento dei cammini minimi]] 4. [[#Funzione di cancellazione#Proprietà dei cammini minimi|Proprietà dei cammini minimi]]
- [[#Limiti degli ordinamenti con confronti#Single-Source Shortest Path in un DAG|Single-Source Shortest Path in un DAG]] 1. [[#Funzione di cancellazione#Generic SSSP|Generic SSSP]] 2. [[#Funzione di cancellazione#SSSP in un grafo orientato aciclico (DAG)|SSSP in un grafo orientato aciclico (DAG)]]
- [[#Limiti degli ordinamenti con confronti#Algoritmo di Bellam-Ford|Algoritmo di Bellam-Ford]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Implementazione|Implementazione]] 3. [[#Funzione di cancellazione#Esempio|Esempio]] 4. [[#Funzione di cancellazione#Complessità|Complessità]]
- [[#Limiti degli ordinamenti con confronti#Algoritmo di Dijkstra|Algoritmo di Dijkstra]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Implementazione|Implementazione]] 3. [[#Funzione di cancellazione#Esempio|Esempio]] 4. [[#Funzione di cancellazione#Complessità|Complessità]]
- [[#Limiti degli ordinamenti con confronti#Conclusioni sul problema dei cammini minimi da una sorgente|Conclusioni sul problema dei cammini minimi da una sorgente]] 1. [[#Funzione di cancellazione#Conclusioni|Conclusioni]] 2. [[#Funzione di cancellazione#Utilizzi molteplici|Utilizzi molteplici]]
- [[#Limiti degli ordinamenti con confronti#Programmazione dinamica per la risoluzione dei cammini minimi tra tutte le coppie|Programmazione dinamica per la risoluzione dei cammini minimi tra tutte le coppie]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Implementazione|Implementazione]] 3. [[#Funzione di cancellazione#Miglioramento|Miglioramento]] 4. [[#Funzione di cancellazione#Complessità|Complessità]]
- [[#Limiti degli ordinamenti con confronti#Floyd-Warshall|Floyd-Warshall]] 1. [[#Funzione di cancellazione#Definizione|Definizione]] 2. [[#Funzione di cancellazione#Implementazione|Implementazione]] 3. [[#Funzione di cancellazione#Esempio|Esempio]] 4. [[#Funzione di cancellazione#Complessità|Complessità]]
Ricorsione
Introduzione alla ricorsione
La ricorsione
La ricorsione rappresenta uno dei concetti più eleganti e profondi della programmazione. Essa si fonda sull’idea che un problema complesso possa essere affrontato scomponendolo in sotto-problemi più semplici, ciascuno dei quali conserva la stessa natura e struttura del problema originario, ma su scala ridotta.
Definizione
Un programma ricorsivo è una funzione o una procedura che durante la propria esecuzione richiama se stessa per risolvere versioni sempre più piccole dello stesso problema
Questo meccanismo sembra apparentemente circolare, ma è in realtà estremamente potente a condizione che esista un punto di arresto ben definito: ovvero la condizione base
Un esempio classico di questo meccanismo è il calcolo del fattoriale di un numero intero non negativo
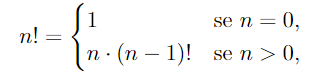 in breve si afferma che per calcolare non è necessario conoscere direttamente il risultato ma basta sapere come calcolare il fattoriale di un numero più piccolo . Questa definizione auto-riferita è perfettamente lecita e diventa potente perché il caso base (quello sopra) interrompe la catena di richiami e garantisce la terminazione (cosa molto importante in un programma)
in breve si afferma che per calcolare non è necessario conoscere direttamente il risultato ma basta sapere come calcolare il fattoriale di un numero più piccolo . Questa definizione auto-riferita è perfettamente lecita e diventa potente perché il caso base (quello sopra) interrompe la catena di richiami e garantisce la terminazione (cosa molto importante in un programma)
Fasi della ricorsione
Le fasi della ricorsione sono:
- Fase di suddivisione: del problema in sotto problemi di minore complessità
- Fase di ricombinazione: dei risultati parziali nella soluzione complessiva Questa duplice operazione è ciò che rende la ricorsione tanto elegante quanto potente infatti permette di passare da una visione monolitica del calcolo a una visione gerarchica e modulare
Definizioni ricorsive delle strutture dati
La ricorsione non riguarda solo gli algoritmi o le funzioni ma anche le strutture dati, di seguito degli esempi:
- Lista: non è altro che un elemento iniziale seguito da un’altra lista dello stesso tipo
- Array: un array di lunghezza può essere definito come un elemento iniziale seguito da un array di lunghezza :
- Alberi: ogni nodo dell’albero può essere considerato come la radice di un nuovo albero, composto dai suoi sottoalberi
Struttura generale di un programma ricorsivo
Ogni programma ricorsivo si fonda su una struttura concettuale ben precisa, che ne garantisce la correttezza logica e la terminazione formata da:
- Il caso base: il caso base è una condizione che ne interrompe la prosecuzione infinita di una ricorsione, matematicamente corrisponde alla condizione di terminazione dell’equazione definita ricorsivamente
- Il passo ricorsivo: In questo punto la funzione richiama sé stessa per risolvere uno o più sotto problemi di dimensione minore, se indichiamo con il problema principale e con i sotto problemi derivati, il passo ricorsivo può essere espresso formalmente come:
- La combinazione dei risultati: Una volta risolti i sotto problemi occorre un meccanismo per ricomporre le soluzioni parziali e ottenere la soluzione complessiva del problema principale. Questo processo detto fase di combinazione è spesso ciò che distingue una ricorsione semplice da una più sofisticata
Una funzione ricorsiva può essere definita in modo generale nel seguente modo: 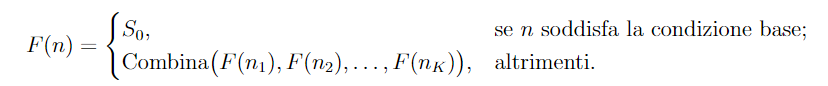 L’esecuzione di questo tipo di funzioni viene gestito automaticamente dallo stack che conserva lo stato di ciascuna chiamata, nel caso in cui la profondità di ricorsione non fosse finita si potrebbe incappare in problemi di stack overflow
Dal punto di vista operativo l’esecuzione di un programma ricorsivo può essere immaginata come una serie di scatole
L’esecuzione di questo tipo di funzioni viene gestito automaticamente dallo stack che conserva lo stato di ciascuna chiamata, nel caso in cui la profondità di ricorsione non fosse finita si potrebbe incappare in problemi di stack overflow
Dal punto di vista operativo l’esecuzione di un programma ricorsivo può essere immaginata come una serie di scatole
Dimensione del problema
Un aspetto cruciale nella progettazione di un algoritmo ricorsivo è la definizione della dimensione del problema, spesso indicata con la variabile , in alcuni casi questa grandezza è intuitiva.
Esempio: nel calcolo del fattoriale o della potenza, la dimensione del problema coincide con un numero intero che viene progressivamente decrementato fino a raggiungere lo zero.
La scelta del parametro che rappresenti la dimensione del problema non è una semplice formalità: essa influisce profondamente sul comportamento dell’algoritmo e sulla sua complessità computazionale
L’equazione di ricorrenza
Ogni algoritmo ricorsivo possiede una propria struttura quantitativa che descrive come il costo del calcolo cresce in funzione delle dimensione del problema, questa struttura prende il nome di equazione di ricorrenza. Un’equazione di ricorrenza esprime il tempo di esecuzione di un algoritmo ricorsivo come funzione del tempo necessario per risolvere uno o più sotto problemi più piccoli più un termine che rappresenta il costo delle operazioni non ricorsive, la funzione del tempo per risolvere un problema di dimensione viene indicato con ovvero: dove rappresenta il tempo necessario per risolvere il sotto problema i-esimo (di dimensione ) e rappresenta il tempo impiegato per la fase di divisione e riunificazione (le fasi che non comportano chiamate ricorsive)
Costruzione di una equazione di ricorrenza
Per costruire l’equazione di ricorrenza corrispondente a un algoritmo occorre osservare come esso si comporta rispetto alla dimensione del problema. Ogni chiamata ricorsiva può essere vista come un nodo dell’albero di ricorsione e il numero di nodi totali determina il tempo totale.
Esempi
- Fattoriale: in questo algoritmo la ricorsione riduce la dimensione del problema di ad ogni chiamata (per ogni chiamata ricorsiva viene fatta una sola moltiplicazione) quindi la sua equazione di ricorrenza è: risolvendo questa ricorrenza otteniamo che
- Somma di un array: in un algoritmo che calcola la somma di una array dividendolo in due metà il tempo di esecuzione ha equazione: poiché ogni chiamata genera due sotto problemi di metà dimensione, è la fase di combinazione richiede solo un tempo costante per sommare i risultati. Risolvendola otteniamo sempre ma con una struttura di chiamate ricorsive estremamente diversa.
- Merge sort: in questo algoritmo ogni livello di ricorsione comporta una divisione in due sottoarray ma la fase di riunificazione (il merging) richiede un tempo lineare . L’equazione di ricorrenza corrispondente diventa quindi: Questo risultato è uno dei più noti nell’analisi algoritmica e mostra come la ricorsione possa amplificare o ridurre l’efficienza di un algoritmo.
Applicazioni pratiche della ricorsione
Per comprendere a fondi il funzionamento della ricorsione, è utile analizzare alcuni analizzare alcuni esempi elementari ma emblematici, mostrano come un problema ricorsivo si risolve sempre creando le due fasi:
- Fase di divisione: il problema viene suddiviso in versioni più semplici
- Fase di riunificazione: le soluzioni vengono combinate per ottenere la soluzione finale
Il fattoriale
Il calcolo del fattoriale di un numero intero non negativo è forse l’esempio più iconico di funzione ricorsiva
Che cosa è un fattoriale
Il fattoriale indicato con rappresenta il prodotto di tutti i numeri interi positivi minori o uguali ad
La sua definizione sottoforma di funzione ricorsiva è la seguente:
- Fase di divisione: consiste nel ridurre il problema a un sotto problema di dimensione minore ovvero
- Fase di riunificazione: avviene durante il ritorno delle chiamate: ciascuna moltiplica il valore ottenuto dalla chiamata successiva per il proprio parametro
int fattoriale ( int n ) {
if ( n == 0) return 1;
else return n*fattoriale(n-1)
}
Questo è l’albero di ricorsione con 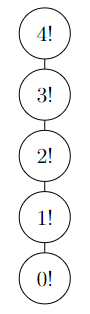
Moltiplicazione come somma ripetuta
Per due numeri interi non negativi possiamo esprimere il prodotto come:
- Fase divisione: riduce il secondo argomento di una unità ad ogni chiamata, il problema viene trasformato in un sotto problema di dimensione più piccola
- Fase di riunificazione: consiste nel sommare al risultato ottenuto dalla chiamata successiva
int moltiplica ( int a , int b ) {
if ( b == 0) 3 return 0;
else return a + moltiplica (a , b - 1);
}
Questo è l’albero di ricorsione di 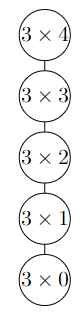
Potenza con moltiplicazione ripetuta
La potenza dati due numeri viene definita così
- Fase di divisione: consiste nel ridurre progressivamente l’esponente fino a raggiungere lo zero
- Fase di riunificazione: avviene moltiplicando ogni valore intermedio per nel momento in cui le chiamate ritornano
int potenza ( int a , int n ) {
if (n == 0) return 1;
else return a * potenza (a , n - 1)
}
L’albero di ricorsione per il calcolo di ha la seguente forma: 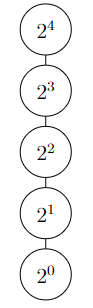
Problemi di somma e soglia su array
Premessa
Gli array sono un ottimo terreno per mettere alla prova la ricorsione, soprattutto in contrapposizione ad una approccio iterativo. I problemi sugli array possono essere risolti in modo ricorsivo seguendo due schemi generali:
- Ricorsione in coda: in cui l’array viene ridotto progressivamente di un elemento alla volta
- Doppia ricorsione: in cui l’array viene suddiviso in due sotto array di dimensioni più piccole che vengono risolti e poi ricombinati
Somma dei valori di un array
Supponiamo di avere un array di interi, il nostro obbiettivo è quello di scrivere una procedura in grado di restituire per qualsiasi array di dimensione , il valore: Si tratta di un problema apparentemente semplice ma utile per comprendere la differenza tra un approccio iterativo e ricorsivo:
- Approccio iterativo: supponendo di avere un array di elementi ci basta scorrere l’array da destra verso sinistra e accumulando progressivamente il valore in una variabile che chiameremo somma
int sommaIterativa(int A[], int n) {
int somma = 0;
for (int i = 0; i < n; i++) {
somma += A[i]; // accumula il valore corrente
}
return somma;
}- Approccio ricorsivo: per usare un approccio ricorsivo dobbiamo scomporre il problema in problemi più piccoli, ciò significa nel caso della somma dobbiamo immaginare l’azione di scorrimento iterativo dell’array come una funzione che richiama ste stessa su versioni ridotte dello stesso array, questa cosa si può fare in due modi:
- Ricorsione di coda: usando al ricorsione in coda definiamo come: Fase di divisione: consiste nel passare da un array di elementi a uno di Fase di riunificazione: consiste nel sommare il valore corrente al risultato ottenuto ricorsivamente
int somma(int A[], int n) {
if (n == 1)
return A[0]; // caso base
else
return A[n-1] + somma(A, n-1); // divisione e riunificazione
}Albero di ricorsione: la complessità dell’albero di ricorsione è e ogni chiamata ricorsiva genera una sola nuova chiamata quindi la complessità temporale è .
- Doppia ricorsione : usando la doppia ricorsione definiamo come:
- Fase di divisione: suddivide il problema in due sotto problemi di dimensione
- Fase di riunificazione: consiste nel sommare i due risultati parziali
int sommaDivisa(int A[], int inizio, int fine) {
if (inizio == fine)
return A[inizio]; // caso base
int medio = (inizio + fine) / 2;
int sinistra = sommaDivisa(A, inizio, medio); // divisione 1
int destra = sommaDivisa(A, medio + 1, fine); // divisione 2
return sinistra + destra; // riunificazione
}Albero di ricorsione: L’albero di seguito è bilanciato e completo con profondità questo ci indica una complessità temporale complessiva è: 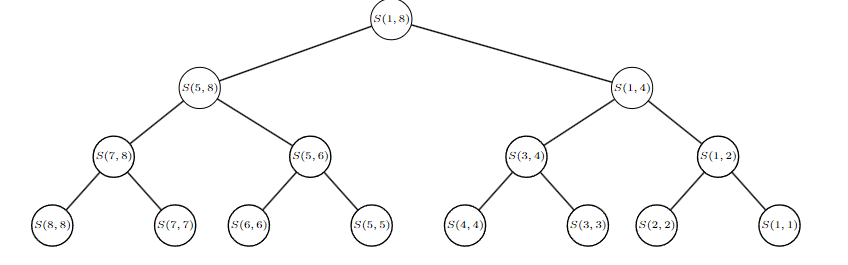
Verificare se la somma supera una soglia
Vogliamo stabilire se la somma degli elementi di un array supera una certa soglia e vogliamo come risultato un esito logico , quello che facciamo è facciamo scorrere la soglia verso il basso man mano che consumiamo l’array: a ogni passo sottraiamo l’ultimo elemento e chiediamo se la somma rimanente super la nuova soglia
bool supera(int A[], int n, int T) {
if (T < 0)
return true; // soglia gia' superata
if (n == 0)
return false; // array esaurito, soglia non superata
return supera(A, n - 1, T - A[n - 1]);
}- Fase di divisione: il problema viene suddiviso in problemi più piccoli con una soglia sempre più bassa
- Fase di riunificazione: il valore dell’ultima chiamata ricorsiva risale
È naturale chiedersi se un approccio a doppia ricorsione possa offrire vantaggi, ma in questo caso la risposta è no, infatti se si suddividesse l’array in due sotto array ciascuna chiamata fornirebbe la risposta “la sinistra da sola non supera ” che non ci dice nulla sull’esito finale che dipende da , ne consegue che la ricorsione binaria in forma puramente booleana è insufficiente e quindi si dovrebbe complicare il tutto per renderla funzionante
Quando l’obiettivo è un esito booleano con possibile arresto anticipato, la ricorsione lineare con soglia residua è la forma più naturale chiara ed efficace
Approccio ricorsivo e iterativo
Analisi
Dopo aver analizzato vari esempi di funzioni ricorsive e la loro costruzione passo dopo passo, è naturale chiedersi quale sia la differenza sostanziale tra un approccio ricorsivo e uno iterativo:
- Ricorsione:
- Concettualmente: rappresenta un modo di ragionare dall’altro verso il basso, infatti parte dalla formulazione del problema generale e lo scompone in sotto problemi più piccoli
- Computazionalmente: richiede una quantità di memoria proporzionale alla profondità della ricorsione
- Iterazione:
- Concettualmente: rappresenta il modo di ragionare dal basso verso l’alto, la soluzione viene costruita passo passo mantenendo esplicitamente lo stato intermedio della computazione
- Computazionalmente: usa una quantità di memoria costante poiché le variabili utilizzate vengono riutilizzate a ogni passo. Le funzioni ricorsive hanno molto spesso una maggiore chiarezza espressiva e questo permette una ottima modularità, naturalmente presenta anche dei limiti pratici, come quando la profondità di una chiamata è molto grande o anche nella gestione dei bug durante la fase di debug.
Il problema dello zaino
Il problema dello zaino che consiste in: dato un insieme di oggetti, ciascuno con un valore e un peso, si vuole scegliere un sottoinsieme che massimizza il valore totale senza superare una capacità massima . Affronteremo questo problema in due versioni
Versione 0.1: pesi unitari, valori diversi
In questo caso abbiamo oggetto tutti con lo stesso peso ma valori differenti, lo zaino può contenere solo un numero limitato di pezzi, pari alla capacità , inoltre gli oggetti sono già disposti in ordine crescente di valore, dal meno prezioso al più prezioso, questa rappresenta la forma più semplice di questo problema. Infatti la scelta ottimale e abbastanza logica consiste nel prendere i oggetti che hanno il valore più alto
Formalizzazione:
- Abbiamo oggetti ordinati per valore crescente:
- Vogliamo massimizzare il valore complessivo: poiché i pesi sono unitari e i valori ordinati, la soluzione ottima è semplicemente:
- Il problema si risolve in maniera lineare in un tempo di esecuzione poiché non sono necessarie né scelte condizionali né chiamate ricorsive
int zainoLineare ( int v [] , int n , int K ) {
int somma = 0;
for ( int i = n - K ; i < n ; i ++) {
if ( i >= 0) somma += v [ i ];
}
return somma;
}Anche se non prettamente necessario per fini didattici esprimiamo la stessa soluzione anche in modo ricorsivo Ricordiamo che: poiché gli oggetti sono già ordinati non è necessario scegliere se includere o meno l’oggetto : se c’è ancora spazio nello zaino () lo si prende automaticamente
int F ( int v [] , int i , int k ) {
if ( i == 0 || k == 0) return 0;
return v [i -1] + F (v , i -1 , k -1);
}La funzione viene richiamata inizialmente con e termina dopo chiamate ricorsive
Conclusioni: questo esempio ci permette di capire che un algoritmo iterativo può essere riscritto anche in forma ricorsiva anche quando la ricorsione non offre dei vantaggi in termini di efficienza
Versione generale 0/1: pesi e valori variabili
Il problema si evolve, gli oggetti non sono più simili tra loro: ogni oggetto ha dunque il proprio peso e un valore differente. La strategia di risoluzione del problema precedente non funziona più infatti: un oggetto di grande valore ma troppo pesante potrebbe impedire di portare con se più oggetti leggeri complessivamente più vantaggiosi, devono essere valutate tutte le possibili combinazioni e in questo la ricorsione diventa uno strumento fondamentale
Formalizzazione: Per ogni oggetto abbiamo peso e valore la capacità massima dello zaino è . Vogliamo massimizzare
- Occorre confrontare sistematicamente le scelte includo/escludo
- Definiamo come prima, i suoi casi base sono:
- se o
- se
- visto che andremo a controllare tutte le possibili combinazioni il ci serve per squalificare tutte le ricorsioni che superano la capacità massima.
- il suo caso caso ricorsivo è:
Si osservi che se una soluzione ottima non include allora è ottima su . Se include allora la soluzione residua è ottima su . Massimizzando i due casi otteniamo il valore ottimo.
int F ( int i , int k , int v [] , int w []) {
if ( k < 0) return INT_MIN /4; // rappresenta - infinito
if ( i == 0 || k == 0) return 0;
int senza = F (i -1 , k , v , w ) ;
int con = v [ i ] + F (i -1 , k - w [ i ] , v , w ) ;
return ( senza > con ) ? senza : con ;
}La ricorsione da sola restituisce il valore ottimo, per ottenere una soluzione concreta facciamo un confronto locale per capire se è preso o escluso. Questa semplice soluzione ha complessità
Esercizi sulla ricorsione
La ricorsione è uno strumento potente per affrontare i problemi di ottimizzazione, gli esercizi dove ci viene chiesto di trova una soluzione ad un problema di ottimizzazione usando la ricorsione devono essere sviluppati seguendo questi passi:
- 1. Individuare i casi base che rendono la ricorsione terminante
- 2. Determinare la scomposizione del problema in sottoproblemi più piccoli
- 3. Stabilire una regola per combinare le soluzioni
Le Notazioni Asintotiche e l’Analisi della Complessità degli Algoritmi
Concetti preliminari di analisi asintotica
Confronto tra le principali funzioni di crescita
Quando si analizza l’efficienza di un algoritmo, non ci si limita a misurare il tempo effettivo di esecuzione sul computer, poiché tale misura dipende da fattori cangianti da macchina a macchina, quello che si punta a fare è descrivere in modo astratto e generale il comportamento dell’algoritmo, indipendentemente dal contesto. In particolare si studia come il tempo di esecuzione cresce al crescere della dimensione dell’input .
- rappresenta la funzione di costo dell’algoritmo. Un algoritmo è fatto di vari passi, un passo può essere considerato come un’operazione di base che richiede un tempo costante.
Diremo che due algoritmi sono più o meno efficienti a seconda di come cresce la loro funzione : un algoritmo la cui funzione di costo cresce più lentamente sarà, per input sufficientemente grandi, più efficiente di uno con crescita più rapida.
Dalla necessità di classificare i vari algoritmi nascono le notazioni asintotiche, che ci permettono per l’appunto di rappresentare questa idea di crescita trascurando i dettagli che non influiscono sul comportamento generale dell’algoritmo.
Confronto tra le principali funzioni di crescita
Alcune funzioni crescono lentamente, altre molto rapidamente. Immaginiamo di avere diversi algoritmi che risolvono lo stesso problema, ma con funzioni di costo differente:
- uno è proporzionale a
- un altro a
- un altro ancora a Per valori piccoli di le differenze possono sembrare trascurabili, ma per input abbastanza grandi la situazione cambia, ad esempio con : In generale abbiamo diversi tipi di crescita:
- Funzioni costanti rappresentano algoritmi che impiegano sempre lo stesso numero di operazioni indipendentemente da
- Accesso ad un elemento di un array
- Funzioni logaritmiche descrivono algoritmi che riducono il problema di un fattore costante a ogni passo
- Ricerca binaria
- Funzioni lineari corrispondono ad algoritmi che analizzano tutti gli elementi dell’input una sola volta
- Scansione di un array
- Funzioni linearitmiche caratterizzano algoritmi efficienti di ordinamento
- Merge sort e Heap sort
- Funzioni polinomiali includono molti algoritmi praticabili ma diventano rapidamente onerose per
- Bubble sort
- Funzioni esponenziali e fattoriali: descrivono problemi di natura combinatoria per i quali il numero di soluzioni cresce esplosivamente con
- Calcolo di tutte le permutazioni Sono elencate in ordine di crescita crescente: una funzione situata più in basso cresce più rapidamente di tutte quelle sopra di essa
Termini e fattori dominanti e trascurabili
Quando si analizza il tempo di esecuzione di un algoritmo la funzione di costo può contenere più termini, si chiama termine dominante quello che determina l’andamento complessivo della funzione per valori grandi di , quando abbiamo più termini quello che dobbiamo fare è:
- Eliminare i termini di ordine inferiore, cioè quelli che crescono più lentamente
- Si ignorano i fattori costanti che moltiplicano i termini
- Si conserva solo il termine che domina Di seguito degli esempi:
- in questa funzione domina il ed essendo un coefficiente moltiplicativo questo è trascurabile quindi possiamo dire che questo algoritmo viene descritto da
- qui il termine che cresce più velocemente è
Le notazioni asintotiche
Con il termine asintotico indichiamo il comportamento di una funzione quando la variabile indipendente cresce senza limiti, possiamo quindi affermare che:
Una notazione asintotica è un modo sintetico per descrivere il modo in cui una funzione cresce rispetto a un’altra. Essa non ci dice quanto vale esattamente una funzione, ma quanto rapidamente aumenta rispetto ad altre funzioni al crescere di n
Esempio: dire che è “dell’ordine ” significa che per input molto grandi il numero di operazioni richieste dall’algoritmo cresce in modo proporzionale a
In generale le notazioni asintotiche forniscono un linguaggio per esprimere relazioni del tipo:
- cresce non più rapidamente / alla stessa velocità / più rapidamente di Esse si basano quindi sul confronto tra le due funzione nel limite per cioè osservando il loro comportamento quando la dimensione diventa molto grande
Esempio: date queste due funzioni: la differenza può sembrare significativa, ma man mano che cresce il termine diventa dominante, quindi possiamo affermare che e hanno la stessa crescita asintotica
La notazione Θ (theta)
La notazione fornisce un vincolo asintotico stretto ovvero rappresenta l’insieme di tutte le funzioni che crescono alla stessa velocità di una funzione di riferimento g(n). Formalmente scriviamo che: In altre parole, a partire da una certa soglia la funzione è sempre compresa tra due multipli costanti della funzione di riferimento .
Praticamente la notazione descrive una crescita bilanciata: cresce in modo simile a differendo al più per un fattore costante. Questo significa che per input di molto grandi possiamo dire che: 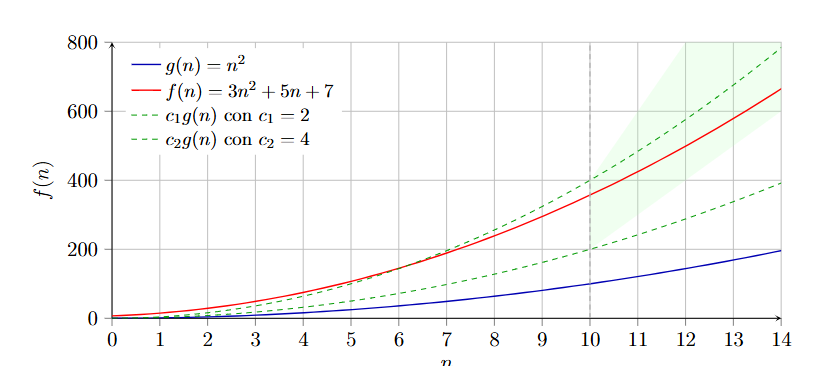 da questa immagine capiamo subito il significato della definizione formale infatti dopo un certo (in questo caso ) la nostra funzione resta confinata nella fascia delimitata dalla linea tratteggiata
da questa immagine capiamo subito il significato della definizione formale infatti dopo un certo (in questo caso ) la nostra funzione resta confinata nella fascia delimitata dalla linea tratteggiata
Esempi:
- perché la costante additiva non influisce sul comportamento
La notazione è la più informativa poiché fornisce sia un limite superiore sia uno inferiore, se allora è simultaneamente:
- Capiremo successivamente il perché
La notazione O (Big-Oh)
La notazione rappresenta un limite superiore asintotico ovvero descrive funzioni che per n sufficientemente grandi non crescono più rapidamente di una funzione di riferimento g(n), formalmente si definisce come: direi che significa che, a partire da una cerca soglia il valore di non supera mai quello di
Praticamente la notazione serve per stabilire una stima superiore del comportamento asintotico infatti garantisce che non crescerà mai più velocemente di per grandi
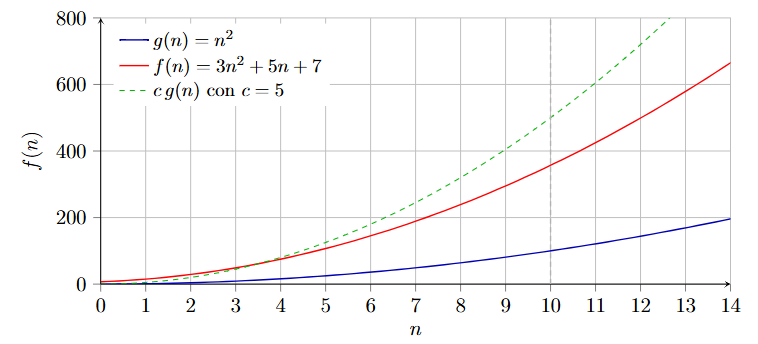 Attraverso questa immagine riusciamo subito a capire la definizione formale, infatti dopo una la funzione non cresce più velocemente di
Attraverso questa immagine riusciamo subito a capire la definizione formale, infatti dopo una la funzione non cresce più velocemente di
Esempi:
la notazione indica solo un limite superiore se diciamo che stiamo affermando che l’algoritmo non richiede mai più di un tempo proporzionale a ma potrebbe essere anche più efficiente. Di solito questa notazione viene usata per descrivere il caso peggiore
La notazione Ω (Big-Omega)
La notazione rappresenta un limite inferiore asintotico ovvero descrive funzioni che per n sufficientemente grande crescono almeno tanto rapidamente quanto una funzione di riferimento g(n) formalmente si definisce come: Ciò significa che a partire da un certo punto il valore di è sempre maggiore o uguale a una constante moltiplicativa di
Praticamente la notazione descrive una crescita minima garantita, infatti oltre una scelta soglia la funzione rimane sempre al di sopra della funzione di riferimento
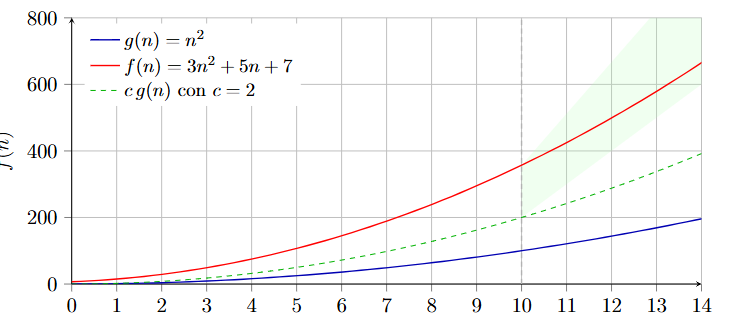 Attraverso questa immagine è abbastanza intuitiva la definizione formale, oltre una certa la nostra funzione rimane sempre al di sopra della curva
Attraverso questa immagine è abbastanza intuitiva la definizione formale, oltre una certa la nostra funzione rimane sempre al di sopra della curva
La notazione indica un limite inferiore e appunto per questo viene utilizzata per descrivere il caso migliore
Esempi:
Le notazioni o e ω (piccole)
Accanto a e che rappresentano limiti asintotici ampi, esistono le loro controparti minuscole e che esprimo limiti stretti
-
La prima esprime che cresce più lentamente di :Significa che il rapporto tende a zero quindi cresce in modo più lento di che per grandi il suo contributo diventa trascurabile
Praticamente possiamo dire che un tempo di esecuzione significa che esso cresce più lentamente di qualunque funzione proporzionale a
-
La seconda ha un significato opposto descrive infatti funzioni che crescono più rapidamente di :Significa che il rapporto tende a infinito Praticamente possiamo dire che un tempo di esecuzione significa che la nostra funzione cresce più velocemente di qualunque funzione proporzionale a
Possiamo dunque pensare alle notazioni e come versioni esclusive di e che indicano una crescita più lenta o più rapida che non raggiunge mai quella della funzione di riferimento
Conclusioni sulle notazioni asintotiche
La scala delle notazioni è la seguente
Oltre i casi limite
Cosa accade davvero in pratica
Le notazioni asintotiche sono strumenti potenti per classificare gli algoritmi, ma è importante ricordare che esse rappresentano un modello astratto del comportamento di un programma. Dire che un algoritmo ha complessità non significa che esegua esattamente operazioni ma solo che per grandi il suo tempo di esecuzione non cresce più rapidamente di una funzione , di solito in questo tipo di analisi si distinguono tre casi:
- che descrive il caso peggiore ovvero il limite superiore del tempo di esecuzione
- che descrive il caso migliore ovvero il limite inferiore del tempo di esecuzione
- indica che il tempo di esecuzione è compreso tra i due limiti precedenti, fornisce quindi una descrizione asintoticamente esatta di quello che è il tempo di esecuzione
Esempio 1: La ricerca lineare Nel caso peggiore, una ricerca lineare in un array di elementi richiede di esaminare tutti gli elementi: Tuttavia, se l’elemento cercato si trova spesso nelle prime posizioni, il numero medio di confronti può essere molto più basso, ad esempio circa . In tal caso, il comportamento medio si avvicina a: ma il tempo effettivo percepito sarà spesso inferiore rispetto al limite teorico.
Esempio 2: L’ordinamento tramite QuickSort Il QuickSort ha una complessità nel caso peggiore di , che si verifica quando il pivot scelto in ogni passo è sempre il minimo o il massimo elemento (ad esempio, se l’array è già ordinato). Tuttavia, nella pratica, grazie alla scelta casuale del pivot o a tecniche di bilanciamento, l’algoritmo si comporta quasi sempre come un algoritmo . Il suo caso medio è quindi molto più rappresentativo delle prestazioni reali: Esempio 3: La ricerca binaria La ricerca binaria ha caso migliore (quando l’elemento cercato è esattamente quello centrale) e caso peggiore . Nella pratica, tuttavia, ogni ricerca richiede un numero di passi che dipende in modo logaritmico da , per cui il comportamento effettivo si avvicina costantemente al caso peggiore.
Questi esempi ci mostrano che le notazioni non devono essere interpretate come previsioni puntuali, ma come descrizioni qualitative del comportamento, le notazioni vanno interpretate in questo modo:
- Caso peggio ci garantisce la soglia di sicurezza, utile in contesti critici
- Caso migliore: indica il limite di ottimalità teorica, ma non sempre raggiungibile
- Caso medio: è spesso quello più significativo nella valutazione pratica
Quando le costanti contano
Nell’analisi asintotica degli algoritmi, è prassi trascurare i fattori costanti e i termini di ordine inferiore, questo approccio consente di concentrarsi sulla crescita dominante della funzione per molto grandi, tuttavia questa cosa nella pratica quotidiana per input di piccole o medie dimensioni dovrebbe essere attenzionata
Esempio: dal punto di vista asintotico è più efficiente, tuttavia il fattore costante nel primo algoritmo può renderlo più lento del secondo per una vasta gamma di valori realistici di , vediamolo con In questo caso, l’algoritmo con complessità peggiore risulta più veloce. Questo esempio mette in evidenza un punto importante: le notazioni asintotiche descrivono il comportamento per grandi, ma non sempre riflettono le prestazioni reali su input di dimensioni moderate
Risoluzione delle equazioni di ricorrenza
Introduzione alle equazioni di ricorrenza
Per analizzare il tempo di esecuzione di tutti gli algoritmi (e in particolare dei ricorsivi) si fa uso delle equazioni di ricorrenza che esprimono il costo totale in funzione del costo dei sotto-problemi e del lavoro aggiuntivo
Definizione
Un’equazione di ricorrenza è una relazione del tipo: con:
- costo per il risolvere il problema di dimensione
- è il numero di sotto-problemi in cui il problema viene suddiviso
- ciascun sotto-problema ha dimensione
- rappresenta il lavoro non ricorsivo (cioè il costo per dividere, combinare o gestire i sotto-problemi)
Risoluzione dell’equazione di ricorrenza
La soluzione (anche detta forma esplicita) indica un’espressione chiusa per , utile per comprendere come cresce il tempo di esecuzione al crescere di . Per fare questa cosa usiamo tre metodi:
- Metodo dell’albero di ricorsione: si rappresenta la ricorsione come un albero, si calcola il costo per livello poi sommati per conoscere il costo totale, questo metodo viene usato principalmente per capire dove si concentra il lavoro (livelli iniziali o finali).
- Metodo della sostituzione: si formula un’ipotesi sul comportamento asintotico di e la si dimostra per induzione
- Metodo Master: fornisce un risultato generale che consente di determinare l’ordine di grandezza di confrontando con
Identificare l’equazione di ricorrenza
Fasi della ricorsione
Ogni algoritmo ricorsivo può essere idealmente scomposto in tre momenti:
- fase di suddivisione: il problema viene suddiviso in più sotto-problemi di dimensione minore
- fase di risoluzione: ciascun sotto-problema viene affrontato a sua volta in modo ricorsivo
- fasi di composizione: i risultati parziali vengono combinati Detto ciò possiamo aggiungere alla spiegazione dell’equazione di ricorrenza le seguenti cose:
- è il numero di sotto-problemi prodotti
- il fattore di riduzione
- il costo complessivo delle operazioni non ricorsive
Esempio - Ricerca binaria
Nel caso della ricerca binaria, l’algoritmo esami un intervallo ordinato, ne calcola il pinto medio e confronta il valore cercato con l’elemento corrispondente. Se il valore coincide la ricerca termina, altrimenti viene richiamata ricorsivamente sull’altra metà
int binarySearch(int A[], int low, int high, int x) {
if (low > high) return -1;
int mid = (low + high) / 2;
if (A[mid] == x)
return mid;
else if (A[mid] > x)
return binarySearch(A, low, mid - 1, x);
else
return binarySearch(A, mid + 1, high, x);
}In ogni chiamata si effettua al massimo una sola chiamata ricorsiva su metà dell’intervallo, mentre il lavoro non ricorsivo è costante. L’equazione di ricorrenza quindi è:
Ricorrenze non uniformi
Non tutti gli algoritmi ricorsivi possono essere descritti mediante un’equazione del tipo: in cui il problema viene suddiviso in un numero costante di sotto-problemi. In molti casi reali, la dimensione dei sotto-problemi può variare a seconda dei dati.
Esempio - QuickSort
- Caso ideale: l’elemento pivot scelto divide l’array esattamente in due parti uguali, ciascuna di dimensione
- Caso reale: il pivot scelto non divide il nostro array in due array di dimensioni diverse Nel caso medio possiamo dire che: dove il parametro rappresenta la frazione di elementi che ricadono nella prima metà dopo la partizione (). Quando siamo nel caso bilanciato (il caso ideale), quando si avvicina a 0 o a 1 il costo peggiora fino al caso limite.
Analisi
L’esempio appena fatto ci mostra come occorre analizzare la ricorrenza caso per caso, e non sempre possibili applicare le formule standard.
Il metodo dell’albero di ricorsione
Il metodo dell’albero di ricorsione nasce dall’idea di visualizzare come vengono effettuate le chiamate ricorsive. In questo modo diventa possibili analizzare passo dopo passo come si distribuisce il lavoro complesso nei diversi livelli di ricorsione, tutto ciò viene fatto con la seguente notazione
Notazione
ricordiamo sempre l’equazione di ricorrenza generale:
- La radice corrisponde al problema iniziale di dimensione
- i nodi interni rappresentano le chiamate ricorsive generate a ciascun livello
- ogni nodo è etichettato con il costo del lavoro locale dove è la dimensione del sotto-problema corrispondente
- i figli di un nodo rappresentano le chiamate generate da quel nodo, ognuna di dimensione ridotta di un fattore
Analisi
La costruzione di questo albero permette di scomporre la ricorsione in livelli. A ogni livello il numero di nodi è di conseguenza la dimensione dei sotto-problemi è . Il costo totale associato al livello viene descritto come: cioè il numero di nodi di quel livello moltiplicato per il costo del lavoro svolto in ciascun nodo. Quindi il costo totale diventa: con che rappresenta la profondità dell’albero ossia il numero di livello fino a quando la dimensione del problema non si riduce a una costante
Questo approccio fornisce un modo intuitivo per stimare l’andamento del lavoro, ma è anche il modo migliore per averne una rappresentazione visiva. Il comportamento della somma può essere descritto come una serie geometrica, in cui ogni livello contribuisce con un costo proporzionale al precedente. Da cui distinguiamo tre casi:
- Primi livelli: somma dominata dai primi livelli quindi il costo è determinato dal lavoro iniziale
- Livelli intermedi: tutti i livelli hanno lo stesso ordine di grandezza quindi il costo aumenta con l’aumentare dei livelli
- Livelli finali: Somma dominata dai livelli inferiori quindi il costo dominante si sposta alla fine dell’albero
Esempi
Esempio 1 - Ricerca binaria: consideriamo l’equazione della ricerca binaria trovata prima: Possiamo immaginare l’albero della ricorsione come una catena di chiamate successive, in cui ogni nodo produce un unico figlio di dimensione dimezzata. Ad ogni livello il lavoro è constante (ovvero ). Il costo totale si ottiene sommando il contributi di tutti i livelli: dove il numero dei termini è pari a . Da qui risulta immediatamente che:
Il metodo della sostituzione
Un secondo approccio è il metodo della sostituzione, dove al posto di avere un’analisi attraverso una rappresentazione visiva abbiamo un’analisi più analitica
Definizione
Questo approccio consiste nel: formulare un’ipotesi sulla forma asintotica della soluzione e nel dimostrare che tale ipotesi è corretta attraverso un ragionamento induttivo.
Praticamente: Si parte dall’equazione di ricorrenza e, osservando la struttura del problema, si tenta di indovinare la crescita di ad esempio o . Una volta formulata questa ipotesi la si sostituisce nell’equazione e si verifica se l’uguaglianza risulta soddisfatta per valori sufficientemente grandi.
Step da seguire
- Si formula un’ipotesi sul comportamento asintotico di (spesso lo si fa attraverso metodi più intuitivi come l’albero di ricorsione)
- Si sostituisce questa ipotesi all’interno dell’equazione di ricorrenza e si verifica se l’uguaglianza risulta soddisfatta
- Se necessario si aggiusta l’ipotesi e si riparte dallo step 1
Ricordiamo che: questo metodo non si limita a fornire una soluzione numerica: esso insegna a riconoscere e controllare la correttezza delle ipotesi che emergono in modo intuitivo
Esempi
Esempio 1 - Ricerca binaria: consideriamo l’equazione della ricerca binaria trovata prima: L’intuizione (l’albero di ricorsione)n suggerisce una crescita logaritmica. Supponiamo quindi: sostituendo otteniamo che: Affinché la disuguaglianza sia rispettata, è sufficiente che: Anche in questo caso la nostra ipotesi è coerente ed è
Metodo basato sul teorema Master
Il teorema Master fornisce una regola generale per determinare in modo sistematico l’ordine di grandezza.
Definizione
Le equazioni che questo teorema risolve sono del tipo: dove:
- è il numero di sotto-problemi in cui viene suddiviso il problema
- è il fattore di riduzione della dimensione
- è il costo del lavoro non ricorsivo L’idea del teorema master è confrontare la funzione con la quantità , a seconda di quale dei due termini cresce più rapidamente, si individuano tre comportamenti distinti.
Enunciato del teorema Master
Sia Caso 1: Il lavoro ricorsivo domina Se esiste una costante tale che cioè il lavoro non ricorsivo è asintoticamente più piccolo del lavoro interno alla ricorsione (polinomialmente), allora la complessità è: In questo caso domina il costo generato dalla parte ricorsiva dell’algoritmo (le chiamate interne). Esempio tipico: Moltiplicazione di Strassen, dove , , .
Caso 2: I lavori sono equivalenti (a meno di un fattore logaritmico) Se ossia il lavoro non ricorsivo ha lo stesso ordine di grandezza del lavoro ricorsivo (a meno di un fattore logaritmico , con ), allora la complessità è: In questo caso, tutti i livelli dell’albero di ricorsione contribuiscono in modo equivalente al costo totale, e la moltiplicazione per un fattore nel termine si traduce in un incremento di un ordine logaritmico nel costo complessivo. (Generalizzato per ): Se , allora .
Caso 3: Il lavoro non ricorsivo domina Se esiste una costante tale che cioè il lavoro non ricorsivo cresce più velocemente del lavoro interno (polinomialmente), e se inoltre è verificata una condizione di regolarità (detta condizione di dominanza): per una costante e per sufficientemente grande, allora la complessità è: In questo caso, la parte ricorsiva diventa trascurabile rispetto al lavoro non ricorsivo.
Esempio tipico: Una ricorrenza come , dove il termine domina.
Interpretazione intuitiva
Il teorema Master può essere interpretato come un modo sintetico per stabilire quale parte dell’albero di ricorsione domina il costo complessivo:
- nel primo caso domina il livello inferiore, dove si accumula la maggior parte di lavoro ricorsivo
- nel secondo caso ogni livello contribuisce in egual misura, e il numero di livelli aggiunge un ulteriore fattore logaritmico
- nel terzo caso domina il livello superiore, dove il lavoro ricorsivo è prevalente Pur non essendo applicabile in tutti i casi (ad esempio quando i sotto-problemi hanno dimensioni diverse) rimare uno degli strumenti più rapidi per l’analisi asintotica
Confronto tra funzioni
Uno degli aspetti più delicati del teorema master consiste nel comprendere come confrontare la funzione non ricorsiva con la quantità . Ricordiamo che:
- descrive quanto grande diventa l’albero di ricorsione
- misura il costo aggiuntivo sostenuto a ciascun livello
Se cresce molto meno di , il termine ricorsivo domina, se cresce di più, prevale il termine non ricorsivo; se le due funzioni hanno crescita simile, i contributi si equilibrano. Viene introdotto il parametro per formalizzare questa differenza di crescita.
 In generale, il ruolo di non è quello di un valore da calcolare ma di un indicatore concettuale: serve a distinguere tra crescite molto piccole o molto più grandi rispetto a
In generale, il ruolo di non è quello di un valore da calcolare ma di un indicatore concettuale: serve a distinguere tra crescite molto piccole o molto più grandi rispetto a
Esempi
Esempio 1 - Ricerca binaria La ricerca binaria è descritta dalla ricorrenza In questo caso , e . Calcoliamo il termine di riferimento : poiché , si ottiene . Confrontiamo ora con questo valore:
Siamo dunque nel secondo caso del Teorema Master, quello in cui ha lo stesso ordine di grandezza del termine ricorsivo.
Applicando la formula corrispondente, otteniamo:
In ogni passo della ricerca binaria, il problema viene dimezzato, ma il lavoro svolto ad ogni livello (una sola comparazione) è costante. Poiché ci sono livelli fino a ridurre il problema a un singolo elemento, il costo totale cresce in modo logaritmico. Il Teorema Master, in questo caso, conferma in modo immediato ciò che l’intuizione suggerisce: ogni livello contribuisce in modo uniforme, e il numero di livelli determina la crescita complessiva.
Heap
Introduzione
Si usa l’heap per implementare efficientemente le code con priorità. Questo tipo di coda non serve gli elementi in base al momento di arrivo, ma in base a una caratteristica intrinseca chiamata chiave (o priorità). Spesso viene astratta come un albero (successivamente la implementiamo come array)
Caratteristiche principali
Lo heap è un albero con le seguenti caratteristiche:
- Binario: ogni nodo ha al massimo due figli.
- Posizionale: è possibile distinguere figlio destro e figlio sinistro
- Completo: In ogni livello dell’albero sono presenti nodi
- Parzialmente ordinato: Il valore di un nodo sarà sempre maggiore o uguale a quella dei suoi figli
Esempio - il pronto soccorso
Un esempio reale di coda con priorità è il triage ospedaliero. I codici colore rappresentano le priorità (chiavi):
- Bianco/Verde (codici bassi/meno urgenti).
- Giallo/Rosso (codici alti/urgenti). Se un paziente arriva in codice giallo, supera automaticamente tutti quelli in attesa con codice verde, indipendentemente da quanto tempo stiano aspettando. La fila viene rispettata solo tra pazienti con lo stesso codice.
Confronto con altre implementazioni delle code con priorità
Specifiche iniziali
Per capire perché nasce lo heap dobbiamo prima fare un’analisi di come le varie strutture dati si comportano (in termini di complessità algoritmica) quando si lavora con una coda con priorità. Un implementazione di una coda con priorità deve avere necessariamente i seguenti metodi:
- Inserimento: Aggiungere un nuovo elemento.
- Estrazione (del minimo): Rimuovere e restituire l’elemento prioritario.
- Decremento (Decrease Key): Aumentare la priorità di un elemento e quindi diminuire il valore della sua chiave
- Minimo: Consultare l’elemento prioritario senza estrarlo.
Le analisi successive verranno fatte supponendo nodi
Vs Array Disordinato
- Inserimento: . Basta mettere l’elemento nella prima posizione libera
- Estrazione/Minimo: . Bisogna scorrere tutto l’array per trovare il valore più piccolo.
- Decremento: se abbiamo il puntatore all’elemento, ma non aiuta l’estrazione successiva.
Vantaggio: Inserimento immediato. Svantaggio: Costo lineare per trovare il minimo, inaccettabile per code frequenti.
Vs Array Ordinato
- Minimo: . Il minimo è sempre in prima posizione (o ultima, a seconda dell’ordinamento).
- Inserimento: . Per inserire un valore e mantenere l’ordine, bisogna “shiftare” (spostare) tutti gli elementi successivi.
- Estrazione: . Anche togliendo il primo elemento, bisogna riorganizzare l’array (shift verso sinistra).
Vantaggio: Accesso rapido al minimo. Svantaggio: Inserimento ed estrazione costosi.
Vs Alberi Binari di Ricerca Bilanciati (BBST)
Utilizzando un BBST (Balanced Binary Search Tree), l’altezza dell’albero è garantita essere logaritmica ().
- Tutte le operazioni (Inserimento, Estrazione, Ricerca, Decremento): .
Sebbene sia ottimo i BBST sono strutture complesse da implementare e mantenere (richiedono puntatori e ribilanciamenti).
L’obiettivo dello Heap è ottenere le stesse prestazioni asintotiche dei BBST () ma con una struttura molto più semplice, gestibile tramite un array e senza l’uso esplicito di puntatori.
Come è fatto uno Heap
Introduzione
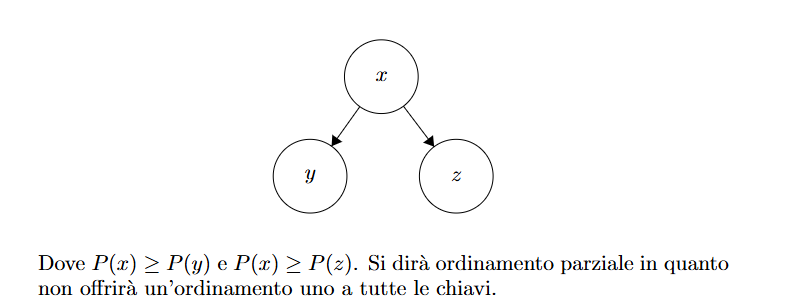
Un heap è un albero binario completo dove a differenza di un BST (dove tutto il sottoalbero sinistro è minore del nodo e tutto il destro è maggiore), nello Heap c’è solo una relazione verticale:
Non c’è alcuna relazione d’ordine specifica tra fratello destro e fratello sinistro. Questo è definito ordinamento parziale.
Tipi di Heap
Esistono due varianti di Heap, simmetriche tra loro:
- Min Heap: La chiave di un nodo è sempre minore o uguale a quella dei suoi figli. La radice contiene il minimo assoluto.
- Max Heap: La chiave di un nodo è sempre maggiore o uguale a quella dei suoi figli. La radice contiene il massimo.
Operazioni sullo Heap
Di seguito la complessità e le implementazioni delle varie funzionalità di uno heap.
Minimo
Poiché usiamo un Min Heap, il minimo si trova sempre alla radice. Costo: (Accesso diretto all’indice 1 dell’array). Nota: la stessa cosa vale per il massimo in un MaxHeap
Decrease Key (Decremento di una chiave)
Se riduciamo il valore di una chiave (es. un nodo passa da 7 a 1), potremmo violare la proprietà dello heap (il figlio diventa più piccolo del padre). Procedura:
- Si aggiorna il valore.
- Si confronta il nodo con il padre.
- Se il nodo è minore del padre, si scambiano (swap).
- Si ripete il procedimento risalendo verso la radice finché la proprietà non è ripristinata o si raggiunge la radice.
Costo: Nel caso peggiore si risale tutta l’altezza dell’albero. .
DECREASE-KEY(H,x,k)
key(x) = k
p = parent(x)
while(p != NULL and key(p)>key(x)) do
swap(x,p)
x = p
p = parent(x)
Inserimento
L’inserimento sfrutta la logica del Decrease Key:
- Inseriamo il nuovo nodo con valore nella prima posizione libera
- Poi facciamo una Decrease Key al nodo inserito con il suo valore reale.
- L’elemento “risale” (bubble-up) fino alla sua posizione corretta.
Costo: Proporzionale all’altezza dell’albero. .
INSERT(H,k)
x = new node(H)
key(x) = k
p = parent(x)
while(p != NULL and key(p)>key(x)) do
swap(x,p)
x = p
p = parent(x)
Procedura Heapify(i):
Si applica a un nodo assumendo che i sottoalberi sinistro e destro siano già heap validi.
- Confronto la chiave di con il figlio sinistro () e il figlio destro ().
- Individuo il più piccolo tra , e .
- Se il minimo non è , scambio con il figlio minore.
- Chiamo ricorsivamente Heapify sul figlio appena scambiato.
Analisi della complessità di Heapify: L’equazione di ricorrenza (nel caso peggiore su un albero quasi completo) è approssimabile dal Teorema Master (Caso 2): Il fattore deriva dal fatto che, in un albero non perfettamente bilanciato nell’ultimo livello, il sottoalbero più grande può contenere circa i 2/3 dei nodi totali. Tuttavia, la complessità rimane legata all’altezza: .
HEAPIFY(H,x)
y = left(x)
z = right(x)
min = x
IF y != NULL AND key(y)<key(x)
min = y
IF y \neq NULL AND key(z)<key(min)
min = z
IF min != x
swap(x, min)
heapify(H,min)
Estrazione del Minimo
Per estrarre il minimo (la radice), non possiamo lasciare un buco.
- Prendiamo l’ultimo elemento dell’array (quello più in basso a destra) e lo spostiamo alla radice al posto del minimo rimosso.
- Ora la struttura è integra, ma l’ordinamento è violato (un elemento grande è in testa).
- Bisogna far “scendere” questo elemento nella posizione corretta e lo facciamo usando la funzione heapify. Costo: richiamando heapify questa procedura costa .
Heap usando un array
Il vero segreto dello Heap è che può essere implementato facilmente usando un array, eliminando la necessità di puntatori. E lo si fa usando le seguenti convenzioni:
- La radice è all’indice (o , a seconda dell’implementazione; qui useremo l’indice 1 per semplificare le formule).
- Dato un nodo all’indice :
- Il figlio sinistro (Left) si trova a .
- Il figlio destro (Right) si trova a .
- Il genitore (Parent) si trova a .
Queste operazioni possono essere eseguite in modo estremamente efficiente tramite operazioni bitwise (shift dei bit):
- Moltiplicare per 2 corrisponde a uno shift a sinistra (
i << 1). - Dividere per 2 corrisponde a uno shift a destra (
i >> 1).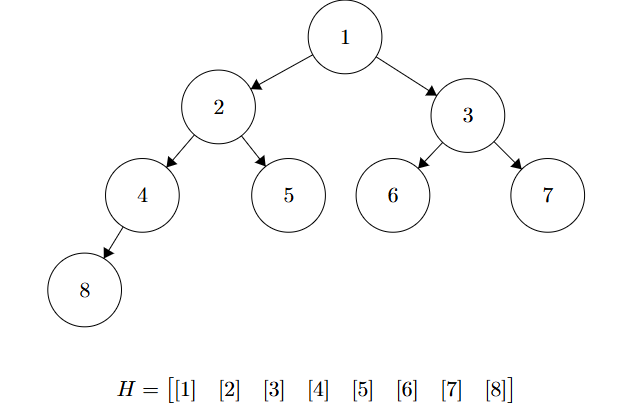 Di seguito tutte le funzioni ridefinite per l’implementazione sottoforma di array del heap
Di seguito tutte le funzioni ridefinite per l’implementazione sottoforma di array del heap
Funzioni left, right, parent
int left(int i){
return (2*i)+1; //Mettiamo +1 perché gli array partono da 0
}
int right(int i){
return (2*i)+2;
}
int parent(int i){
return (i-1)/2;
}Heapify
void min_heapify(int i){
int l = left(i);
int r = right(i);
int min = i;
if(l < size && array[l] < array[min]) min = l;
if(r < size && array[r] < array[min]) min = r;
if(min != i){
int scambio = array[i];
array[i] = array[min];
array[min] = scambio;
min_heapify(min);
}
}
void max_heapify(int i){
int l = left(i);
int r = right(i);
int max = i;
if(l < size && array[l] > array[max]) max = l;
if(r < size && array[r] > array[max]) max = r;
if(max != i){
int scambio = array[i];
array[i] = array[max];
array[max] = scambio;
heapify(max);
}
}
Insert
void insert(int k){
array[size++] = k;
int i = size - 1;
int p = parent(i);
//Questa insert mantiene una struttura max-heap, per min-heap modificare in: array[p]>array[i]
while(i>0 && array[p]<array[i]){
int scambio = array[i];
array[i] = array[p];
array[p] = scambio;
i = p;
p = parent(i);
}
}Extract-min
int extractMax(){
int max = array[0];
int scambio = array[0];
array[0] = array[size-1];
array[size-1] = scambio;
size--;
max_heapify(0);
return max;
}Costruzione dello Heap
Come si costruisce uno heap partendo da un array disordinato di elementi? di seguito due metodi per farlo
Metodo 1: Inserimenti successivi
Possiamo inserire gli elementi uno alla volta in uno heap vuoto (usando la funzione insert). Poiché ogni inserimento costa , per elementi il costo totale è:
Metodo 2: Procedura Build-Min-Heap (Ottimizzata)
Esiste un metodo più efficiente che sfrutta la struttura. Prendiamo l’array così com’è e chiamiamo Heapify a ritroso, partendo dall’ultimo nodo interno fino alla radice.
Algoritmo:
FOR i = floor(n/2) DOWN TO 1:
Min-Heapify(array, i)In pratica, sistemiamo prima i sottoalberi piccoli in basso, poi quelli medi, e infine la radice.
Analisi della complessità A prima vista potrebbe sembrare perché chiamiamo Heapify volte. Tuttavia, l’altezza dei nodi varia:
- La maggior parte dei nodi è vicino al fondo (altezza bassa, costo Heapify basso).
- Pochissimi nodi sono in alto (altezza ).
La somma dei costi è data dalla serie: Poiché la serie converge a una costante, il costo totale è: Costruire uno heap da zero quindi richiede tempo lineare.
Metodo 3: procedura Build-Max-Heap
Questa procedura è uguale a quella del min-heap ma richiamiamo max-heapify
void buildMaxHeap(){
for(int i = size/2-1; i >= 0; i--){
max_heapify(i);
}
}Heapsort
Analisi
Prendendo in esame il selection sort, capiamo subito che il problema principale di questo tipo di algoritmo è il tempo perso durante la ricerca del massimo, cosa che in un max-heap facciamo in tempo , da qui nasce l’heapsort
Algoritmo e implementazione
L’algoritmo heapsort inizia utilizzando Build-max-heap per costruire un max-heap nella array in input, l’elemento più grande è memorizzato nella radice, quindi ci basta scambiarlo con l’ultimo elemento nell’array per ordinarlo, poi richiamiamo max-heapify sull’array ma escludendo gli elementi ordinati, facendo questa cosa per ogni elemento otteniamo il nostro array ordinato.
void HeapSort(){
buildMaxHeap();
int len = size;
for(int i = len-1; i > 2; i--){
int scambio = array[i];
array[i] = array[0];
array[0] = scambio;
size--;
max_heapify(0);
}
size = len; //Nell'implementazione fatta serve per stampare il lo heap
}Questo algoritmo ha complessità
Esami
Nel file 6 - 29 ottobre 2025.pdf ci sono alla fine degli esempi di esercizi di esame:
- Effettuare 13 estrazioni del minimo e mostrare cosa succede al nostro array
- Scrivere la procedura HeapMerge
- Scrivere la procedura ListMerge che segua delle regole specifiche
- Top-ten di punteggi più alti
- ecc…
Limiti degli ordinamenti con confronti
Albero di decisione
Definizione
Gli ordinamenti per confronti possono essere visti in modo astratto come degli alberi di decisione. Un albero di decisione è un albero binario pieno che rappresenta i confronti fra elementi fatti in un particolare algoritmo preso in esame.
Esempio
Attraverso un esempio è abbastanza intuitivo capire come funziona un albero di decisione:
Con abbiamo un albero di decisione del tipo: 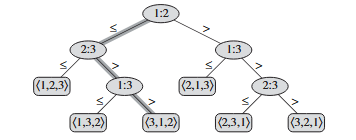 Notiamo subito che il caso peggiore nell’ordinamento corrisponde all’altezza di questo albero
Notiamo subito che il caso peggiore nell’ordinamento corrisponde all’altezza di questo albero
Teorema e dimostrazione
Teorema
Qualsiasi algoritmo di ordinamento per confronti richiede
Dimostrazione
Come abbiamo visto nell’esempio dell’albero di decisione ci basta determinare l’altezza di un albero ogni dove possibile permutazione degli elementi compare come foglia. Consideriamo quindi un albero di decisione:
- elementi da ordinare
- altezza
- numero di foglie ciascuna delle permutazioni dell’input compare in una foglia, si ha quindi . Dal momento che un albero binario di altezza non ha più di foglie si ha: da questo estraiamo: che ci indica una complessità di
Conclusioni
Da questo capiamo che algoritmi come heapSort e MergeSort sono ottimi algoritmi di ordinamento usando i confronti
Algoritmi di ordinamento senza confronti
Counting sort
Premesse
Per superare la barriera imposta dall’albero di decisione abbiamo bisogno di algoritmi di ordinamento che non fanno confronti, e quindi presentiamo il counting sort. Per fare questa cosa il counting sort suppone che ciascuno degli elementi in input sia un intero compreso tra e
Algoritmo
Per usare il counting sort abbiamo bisogno:
- un array in input di elementi interi che vanno da
- un array con celle i cui valori indicano il numero di occorrenze di in
- array di output
Counting-Sort(A, B, n):
k = max(A) // valore massimo in A
C = new Array(k+1)
// inizializza C a 0
for i = 0 to k:
C[i] = 0
// conta le occorrenze
for i = 0 to n-1:
C[A[i]] = C[A[i]] + 1
// calcola le posizioni cumulative
for i = 1 to k:
C[i] = C[i] + C[i-1]
// costruisci l'array ordinato B in maniera stabile
for i = n-1 downto 0:
B[C[A[i]] - 1] = A[i] // -1 perché B è 0-indexed
C[A[i]] = C[A[i]] - 1
Di seguito per step la spiegazione:
- Cerchiamo il nostro che sarebbe il massimo di
- Creiamo il nostro array con posizioni
- Primo FOR: inizializza a 0 l’array C
- Secondo FOR: controlliamo ogni elemento di e incrementiamo di uno l’indice corrispondente in
- Dopo questo passo contiene il numero di occorrenze di in
- Terzo FOR: contiamo il numero di elementi in minore o uguali
- Quarto FOR: Inseriamo ogni elemento di dentro usando come indice il valore calcolato nel terzo passaggio, la riduzione di serve per fare in modo che il successivo elemento con valore uguale ad venga inserito una posizione prima
Implementazione
void countingSort(int *A, int* B, int n){
int k = max(A, n);
int* C = new int[k+1];
for(int i = 0; i <= k; i++)
C[i] = 0;
for(int i = 0; i < n; i++)
C[A[i]] = C[A[i]] + 1;
for(int i = 1; i <= k; i++)
C[i] = C[i]+C[i-1];
for(int i = n-1; i >= 0; i--){
B[C[A[i]]-1] = A[i];
C[A[i]] = C[A[i]] - 1;
}
}Questa implementazione se avviata sull’array: da il seguente output:
Array di base: 2 - 6 - 1 - 7 - 8
Primo For: 0 - 0 - 0 - 0 - 0 - 0 - 0 - 0 - 0
Secondo For: 0 - 1 - 1 - 0 - 0 - 0 - 1 - 1 - 1
Terzo For: 0 - 1 - 2 - 2 - 2 - 2 - 3 - 4 - 5
Quarto For: 1 - 2 - 6 - 7 - 8
Complessità
- il primo ciclo impiega
- il secondo
- il terzo
- il quarto Quindi il tempo totale è Inoltre è stabile: ovvero i numeri con lo stesso valore si presentano nell’array di output nello stesso ordine in cui si trovano nell’array di input, questa cosa solitamente è importante solo quando abbiamo dati satellite, ma nel counting è sempre importante perché molte volte viene usato come subroutine per implementare il radix sort.
Radix sort
Premesse
Il radix sort è l’algoritmo di ordinamento usato in principio per ordinare le schede perforate, ma ai giorni nostri viene utilizzato per ordinare in base a più chiavi contemporaneamente (es: anno, mese e giorno)
Algoritmo
Dati:
- numeri
- ogni numero ha cifre
- ogni cifra può avere fino a valori
quello che fa questo algoritmo è ordinare rispetto considerando solo una cifra dei numeri, partendo da quella meno significativa. La sua implementazione tramite pseudocodice è molto semplice ma implica anche l’implementazione di un algoritmo di ordinamento stabile interno per ordinare rispetto ad una cifra (per noi sempre il counting sort)
RadixSort(A, n, h)
for i <= 0 to h do:
countingSort(A, n, i)
Implementazione
Ricordiamo che le cifre di un numero si estraggo facendo il modulo 10 nel nostro caso la formula per calcolare una cifra di un numero alle i-esima posizione diventa
int scegliCifra(int numero, int digit){
return (numero/(int)pow(10,digit))%10;
}
void countingSortConCifraSpecifica(int *A, int n, int cifra) {
const int k = 9;
int* B = new int[n];
int* C = new int[k + 1];
for(int j = 0; j <= k; j++)
C[j] = 0;
for(int j = 0; j < n; j++) {
C[scegliCifra(A[j], cifra)] = C[scegliCifra(A[j], cifra)] + 1;
}
for(int j = 1; j <= k; j++)
C[j] = C[j] + C[j-1];
for(int j = n - 1; j >= 0; j--) {
int d = scegliCifra(A[j], cifra);
B[C[d] - 1] = A[j];
C[d] = C[d] - 1;
}
for (int j = 0; j < n; j++) {
A[j] = B[j];
}
}
void radixSort(int* A, int len, int h){
for(int i = 0; i < h; i++){
countingSortConCifraSpecifica(A, len, i);
}
}Complessità
La sua complessità dipende dall’algoritmo di ordinamento usato al suo interno, nel nostro caso abbiamo usato il counting sort quindi abbiamo una complessità:
Tabelle Hash
Introduzione alle Hash table
Introdurremo il concetto di Tabella Hash partendo da un problema di implementazione: dobbiamo implementare un dizionario. Quale è il modo migliore di farlo?
Cos’è un dizionario?
Un dizionario è un insieme su cui possiamo effettuare operazioni di:
- inserimento
- cancellazione
- ricerca Questa struttura dati viene usata principalmente per la ricerca. La ricerca di un elemento in un dizionario può portare a due esiti differenti:
- Ricerca con successo: ricerca di un elemento presente nella tabella
- Ricerca senza successo: ricerca di un elemento non-presente nella tabella.
Possibili implementazioni e complessità con strutture già note
- Array non-ordinato:
- Inserimento:
- Cancellazione:
- Ricerca:
- Array ordinato:
- Inserimento:
- Cancellazione:
- Ricerca: Ricerca Binaria
- Lista non-ordinata:
- Inserimento:
- Cancellazione:
- Ricerca:
- Lista ordinata:
- Inserimento:
- Cancellazione:
- Ricerca:
- BST:
- Inserimento:
- Cancellazione:
- Ricerca:
- Tabella a Indirizzamento Diretto:
- Inserimento:
- Cancellazione:
- Ricerca:
Tabelle a Indirizzamento Diretto
Definizione
Una tabella a indirizzamento diretto è una soluzione molto conveniente, nei casi in cui l’insieme universo (l’insieme di tutti i numeri registrabili) è un insieme relativamente piccolo. Una tabella a indirizzamento diretto avrà uno slot per ogni elemento . Ad ogni elemento è associata una chiave , ovvero un indice della tabella a indirizzamento diretto.
Implementazione
Inserimento:
Insert(T,k)
T[k] = 1
Rimozione:
Insert(T,k)
T[k] = 0
Ricerca:
Search(T,k)
IF T[k]=1
RETURN true
ELSE RETURN false
Hanno tutte complessità
Svantaggi di questa struttura
Apparentemente, le tabelle a indirizzamento diretto sono perfette; tuttavia, esistono dei casi in cui non sono veramente consone, e in cui anzi, non possono essere proprio utilizzate:
- Insieme U molto grande rispetto a K: se l’insieme universo è molto grande, ma l’insieme delle chiavi da memorizzare è piccolo, la memoria da allocare sarà quasi del tutto sprecata.
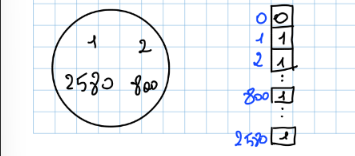
- L’insieme universo è infinito. Un calcolatore non ha memoria infinita, e una tabella a indirizzamento diretto ha bisogno di un numero finito di indici.
Per risolvere questi problemi e poter utilizzare le tabelle ad indirizzamento diretto e quindi i dizionari nascono le funzioni di hash, una funzione che assegna ad un valore una specifica chiave.
Funzione hashing
Definizione
Il ruolo della funzione hashing (detta ) è quello di associare ad un elemento dell’insieme , un indice della tabella hash. In questo modo lo spazio richiesto da una tabella Hash (una tabella ad indirizzamento diretto ma che usa l’hashing) sarà ridotto a , quindi sarà uguale al numero di chiavi da memorizzare, molto di meno rispetto a , riuscendo a conservare i vantaggi di una tabella ad indirizzamento diretto (ovvero la ricerca in )
Collisioni
La funzione , avendo solitamente un codominio di cardinalità inferiore al dominio, non è una funzione biunivoca. Per il pigeonhole principle, se gli elementi da inserire nella Hash Table sono più degli indirizzi, almeno due chiavi finiranno allo stesso indirizzo. Quando due chiavi finiscono nella stessa cella, abbiamo un fenomeno chiamato collisione, dall’evitare le collisioni nascono tutti modi per implementare una tabella hash.
Implementazioni delle tabelle hash
Data una chiave sono tanti i metodi che possiamo utilizzare per indirizzare, di seguito ne vediamo alcuni.
Metodo della divisione
Dati:
- ,
-
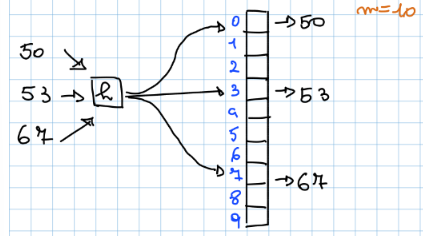 Quando utilizziamo questo metodo evitiamo certi valori di , per esempio non può essere una potenza di , perché se allora durante la creazione delle chiave si baserà solo sui meno significativi e non su tutto il valore creando poca uniformità.
Quando utilizziamo questo metodo evitiamo certi valori di , per esempio non può essere una potenza di , perché se allora durante la creazione delle chiave si baserà solo sui meno significativi e non su tutto il valore creando poca uniformità.

Metodo della moltiplicazione
Dati:
- e Spieghiamo il principio di di questo metodo:
- ci ritorna un valore compreso tra 0 e .
- Il resto della divisione per 1 con un numero reale, ritornerà il valore della parte decimale, ottenendo un valore compreso tra 0 e 1, 1 escluso.
- Moltiplicando per , otteniamo valori compresi tra 0 e , escluso.
- La funzione floor ci permette di prendere solo la parte intera In questo metodo il valore di non è critico come prima, solitamente scegliamo una potenza di perché rende più veloce l’implementazione nei calcolatori moderni
Risolviamo le collisioni usando l’hashing con concatenazione
Definizione
Nell’hashing con concatenazione poniamo tutti gli elementi che sono associati alla stessa cella in una lista concatenata. Praticamente la cella contiene un puntatore alla testa della list adi tutti gli elementi memorizzati che vengono mappati in ; se non c’è ne sono, la cella contiene la costante
Implementazioni
Inserimento:
Insert(T,k)
List-Insert(T[h(k)], k)
Costo: avrà come l’inserimento in lista.
Rimozione:
Insert(T,k)
List-Delete(T[h(k)], k)
Costo: avrà come la cancellazione dalla lista.
Ricerca:
Search(T,k)
RETURN List-Search(T[h(k)], k)
Costo: Il caso peggiore sarà quello in cui ogni elemento è inserito nella stessa posizione della tabella. , come la ricerca in una lista di elementi. Andiamo a studiare tuttavia il caso medio, introducendo il concetto di uniformità.
Analisi
Attention
Data una tavola hash con celle dove sono memorizzati elementi, definiamo fattore di carico della tavola il rapporto , ossia il numero medio di elementi che memorizzati in una lista, la nostra analisi sarà fatta in funzione di che può essere minore, uguale o maggiore di .
Caso peggiore: il comportamento nel caso peggiore dell’hashing con concatenamento è pessimo, tutte le chiavi vengono associate alla stessa cella, quindi stiamo lavorando praticamente con una lista, con tutte le inefficienze del caso ovvero: Ricerca in
Caso medio: il comportamento nel caso medio dipende dal modo in cui la funzione hash distribuisce mediamente l’insieme delle chiavi da memorizzare tra le celle. Per adesso supponiamo che qualsiasi elemento abbia la stessa probabilità di essere mandato in un qualsiasi posizione. Questa ipotesi si chiama Hashing uniforme semplice. Se indichiamo con la lunghezza della lista per avremo da questo possiamo dire che la lunghezza media delle liste è: per fare un’analisi della complessità dobbiamo necessariamente distinguere due casi:
- Ricerca senza successo: una ricerca senza successo richiede un tempo di nel caso medio Dimostrazione: Il tempo atteso per ricercare senza successo una chiave è il tempo atteso per svolgere ricerche fino alla fine della lista che ha lunghezza attesa di quindi il tempo totale richiesto (incluso quello per calcolare che ipotizziamo sia ) è
- Ricerca con successo: una ricerca con successo richiede un tempo di nel caso medio
Dimostrazione: il numero di elementi esaminati durante una ricerca con successo di un elemento è uno in più del numero di elementi che si trovano prima di nella lista di . Gli elementi prima di li troviamo facendo: Ricordiamo che . Dunque il numero atteso di elementi esaminati con successo è:Di seguito la risoluzione:
- Distribuiamo la sommatoria dentro la parentesi e sostituiamo :
- Riscrivo la prima sommatoria semplicemente come e sposto fuori la costante :
- Riscrivo la sommatoria con come :
- Riscrivo le sommatorie come differenza di sommatorie
- Risolvo le sommatorie
- Risolvo i calcoli rimanenti
Risolviamo le collisioni usando l’hashing a indirizzamento aperto
Definizione
Un altro metodo che permette di risolvere le collisioni, è l’indirizzamento aperto. Supponiamo di avere una tabella con un numero di slot. Se cercando di effettuare un inserimento nella tabella, la posizione calcolata dalla funzione di hashing risulta già occupata, verrà calcolato e ispezionato un altro slot. Ciò avverrà fino a quando non si troverà uno slot libero (contenente NULL o D, ne parleremo dopo), o fino a quando non si saranno controllati tutti gli slot della tabella.
Sequenza di ispezione
La funzione di hashing all’interno di una tabella con indirizzamento aperto al posto di ritornare una singola posizione, sarà così definita: Definiamo sequenza di ispezione di una chiave , la sequenza di indici che viene generata dalla funzione di hashing calcolata su , ovvero: La sequenza di ispezione conterrà tutti gli slot della tabella e rappresenta tutte le possibili posizioni che potrebbe prendere se non sono occupate.
Implementazioni funzioni di base
Inserimento
hash_insert(T, k)
IF n = m
RETURN // tabella piena
i = 0
WHILE (T[h(k, i)] != NULL AND T[h(k, i)] != D): //D spiegato in "Funzione di cancellazione"
i = i + 1
T[h(k, i)] = k
n = n + 1
Ricerca
hash_search(T, k)
i = 0
WHILE T[h(k, i)] != NULL AND i < m:
IF T[h(k, i)] = k
RETURN True
i++
RETURN False
Funzione di cancellazione
La funzione di cancellazione, all’interno di una tabella hash che risolve le collisioni tramite l’indirizzamento aperto, richiederà una modifica fondamentale per il funzionamento corretto della funzione di ricerca. Cancellato un elemento dalla tabella, esso non dovrà essere sostituito da NULL. Esso dovrà infatti essere contrassegnato come D di DELETED. L’esempio di seguito aiuta a capire perché usiamo
Esempio:
- Prendiamo una tabella hash con contiene i numeri .
- Eliminiamo il numero 3 dalla tabella, ottenendo .
- Calcoliamo la sequenza di ispezione della chiave 5 che sarebbe:
- Supponiamo adesso di usare la funzione di ricerca per verificare la presenza (evidente) del numero 5
La ricerca si interromperà a . Ciò non sarebbe avvenuto prima dell’eliminazione del numero 3, ed è causato proprio dal NULL in posizione 2.
Contrassegnare lo slot con DELETED espliciterà il fatto che lo slot è libero in caso di inserimento, ma anche che la ricerca non andrà interrotta nonostante lo slot vuoto.
hash_delete(T, k)
i <- 0
WHILE (T[h(k, i)] != NULL AND i < m):
IF T[h(k, i)] = k:
T[h(k, i)] = DELETED
RETURN True
i = i + 1
RETURN False
Essendo l’eliminazione abbastanza macchinosa usiamo l’indirizzamento aperto solo quando non dobbiamo eliminare elementi.
Requisiti di una funzioni hash per indirizzamento aperto
Dati:
- è l’insieme di tutte le permutazioni sull’insieme .
- La cardinalità di è . Sia una permutazione. La probabilità che deve essere la stessa per qualsiasi permutazione. Questa ipotesi si chiama hashing uniforme. Costruire funzioni hash per l’indirizzamento aperto che rispettino questa proprietà è piuttosto complesso. Successivamente vengono analizzate tre tecniche usate per creare la sequenza di ispezione
Analisi
La nostra analisi dell’indirizzamento aperto è espressa in termini del fattore di carico . Supponiamo venga applicata l’hashing uniforme quindi la sequenza utilizzata per inserire o ricercare una chiave ha la stessa probabilità di essere una qualsiasi permutazione di . Analizziamo di seguito il numero atteso di ispezioni dell’hashing con indirizzamento aperto, facendo differenza tra una ricerca con e senza successo:
Ricerca senza successo: data una tavola hash con un fattore di carico il numero atteso di ispezioni in una ricerca senza successo è al massimo
Dimostrazione: 
Ricerca con successo: data una tavola hash con un fattore di carico il numero atteso di ispezioni in una ricerca senza successo è al massimo
Dimostrazione: 
Tecniche per creare una sequenza di ispezione
Ispezione lineare
La funzione di hashing per la scansione lineare è definita in questo modo
Con . Le sequenze della nostra funzione di hashing saranno del tipo
Questa funzione di hashing non gode della proprietà di hashing uniforme, in quanto, le permutazioni ottenute non possono non iniziare con . Moltissime permutazioni avranno probabilità , e le restanti . Un’altro problema di questo tipo di ispezione è l’agglomerazione primaria. In breve, la probabilità che le chiavi siano inserite in slot successivi aumenta ad ogni inserimento, favorendo agglomerati di chiavi e allungando le tempistiche relative alle operazioni.
Ispezione quadratica
Cambia solo la funzione di hashing e diventa: Con e costanti scelte in modo tale che l’intera tabella venga scansionata dalla funzione ed evitare l’agglomerazione primaria.
Ispezione doppio hashing
In questa funzione vengono usate due funzione di hashing: Il numero totale di permutazioni totale è , in quanto la prima funzione di hashing da la prima posizione, la seconda le successive, e quindi possibili posizioni dopo altre .
Alberi rosso-neri
Alberi bilanciati
Lavorando con gli alberi ci capita di incappare in alberi sbilanciati, nel peggiore dei casi questi sono praticamente delle liste, dalla necessità di rendere l’albero autobilanciante nascono gli alberi rosso-neri
Definizione di albero bilanciato
Definiamo albero bilanciato quell’albero che ha entrambi i sottoalberi con una quantità di lavoro asintoticamente uguale. Dato questo albero: 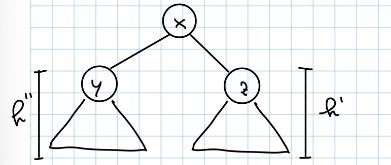 possiamo dire che:
possiamo dire che:
Ripasso proprietà del BST
Un albero binario di ricerca è costituito esclusivamente da nodi che rispettano la seguente proprietà:
- ogni nodo è maggiore o uguale a tutti i nodi del proprio sottoalbero sinistro
- ogni nodo è minore o uguale a tutti i nodi del proprio sottoalbero destro
Algoritmo di inserimento: inizia confrontando il valore da inserire con la radice, vado a sinistra o a destra in base alle proprietà di prima, ripeto questo passaggio fino a quando non trovo un posto libero.
Proprietà di una albero rosso-nero
Proprietà di un albero rosso-nero
Un albero rosso-nero è bilanciato questo è possibile grazie a queste regole:
- Ogni nodo è rosso o nero
- La radice è nera
- le foglie sono nere
- Questa proprietà può anche non essere rispettata se consideriamo foglie gli ultimi nodi dell’albero quelli NIL (l’altezza aumenta di e la dimensione diventa )
- I figli di un nodo rosso sono neri

- Per ogni nodo, tutti i cammini che vanno dal nodo alle foglie discendenti contengono lo stesso numero di nodi neri
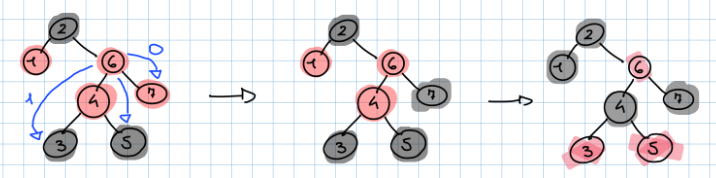 Ogni nodo dell’albero è formato da:
Ogni nodo dell’albero è formato da:
- color: il colore del nodo
- key: valore del nodo
- left: puntatore al figlio sinistro
- right: puntatore al figlio destro
- p: puntatore al padre Se manca un figlio o un padre di un nodo il suo valore sarà NIL, i nodi NIL sono considerati come nodi neri
Esistono diversi modi per colorare un albero, basta che le proprietà vengano rispettate
Rappresentazione di un albero rosso-nero
La rappresentazione di un albero rosso nero viene fatta in questo modo:
- Si decide di creare un nodo NIL ogni volta che è necessario
- Tutti i NIL si fanno corrispondere ad un singolo nodo detto sentinella NIL
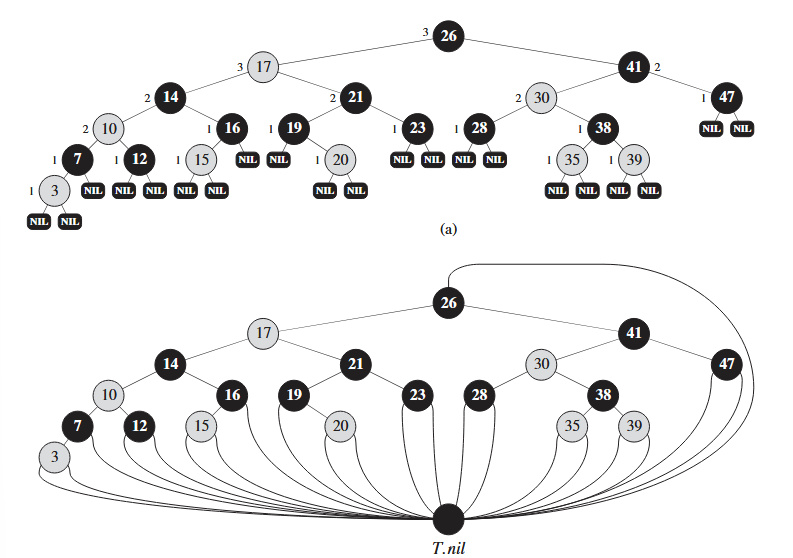 Il secondo approccio rispetto al primo risparmia della memoria ma è graficamente meno intuitivo.
Il secondo approccio rispetto al primo risparmia della memoria ma è graficamente meno intuitivo.
Definizione altezza nera lemma altezza massima
Definizione altezza nera: definiamo altezza nera di un nodo , indicata con il numero di nodi neri lungo un cammino semplice che inizia dal nodo (ma non lo include) e finisce in un foglia. L’altezza nera di un albero è .
Definizione altezza massima: l’altezza massima di un albero rosso-nero con nodi interni è
Dimostrazione: Iniziamo dimostrando che il sottoalbero con radice in un nodo qualsiasi contiene almeno nodi interni, lo faremo per induzione:
- caso base: Se l’altezza di è allora deve essere una foglia e il sottoalbero con radice in contiene:
- passo induttivo: consideriamo un nodo che ha un altezza positiva ed è quindi un nodo interno con due figli.
Possiamo dire che ogni figlio ha un altezza nera pari a:
- se rosso ha
- se nero ha (perché escludo il nodo stesso dal conteggio) Poiché l’altezza di un figlio di è minore dell’altezza di possiamo applicare l’ipotesi induttiva per concludere che ogni figlio ha almeno e quindi possiamo concludere che il sottoalbero con radice in contiene: $$ \underbrace{(2^{bh(x)-1}-1)}{\text{nodi interni albero sx}} + \underbrace{(2^{bh(x)-1}-1)}{\text{nodi interni albero dx}} + 1 = 2^{bh(x)} - 1 ;\text{nodi interni}
F_n = \begin{cases} 1 & \text{se } n \leq 2 \ F_{n-1} + F_{n-2} & \text{se } n > 2 \end{cases}
L'implementazione diretta che ne facciamo è: ``` F(n): if n <= 2 then return 1 else return F(n-2) + F(n-1) ``` ![[Pasted image 20251224100247.png|500]] Guardando l'albero di ricorsione si nota subito che alcuni sotto-problemi vengono risolti più volte, questo è ovviamente un problema che ci fa perdere tempo. Quello che facciamo è rendere un caso base ogni sotto-problema risolto ``` F(n) // Inizializzazione M = new Array(n) // array che contiene la soluzione M[1] = M[2] = 1 for i = 3 to n DO M[i] <- NULL // inizializzazione F(n) if M[n] != null then return M[n] if M[n-1] == null then M[n-1] <- F(n-1) if M[n-2] == null then M[n-2] <- F(n-2) return M[n-1] + M[n-2] ``` Entrambe le soluzioni sono *top-down*, ma la seconda risulta più efficiente. Di seguito una soluzione *bottom-up*: ``` F(n): M[1] <- M[2] <- 1 for i <- 3 to n do M[i] <- M[i-2] + M[i-1] return M[n] ``` ###### Analisi - L'approccio ricorsivo puro non ha senso se un sotto-problema deve essere risolto più volte per arrivare alla soluzione, in quel caso ha più senso fare uso della *memorizzazione*. - Se lo spazio delle soluzioni viene esplorato tutto per trovare la soluzione allora ha più senso un approccio iterativo (*bottom-up*) come nel caso della sequenza di Fibonacci ### Rod-cutting ###### Definzione *Il problema del taglio delle aste* può essere definito nel seguente modo: - Data un'asta di lunghezza $n$ pollici - Una tabella di prezzi $p_i$ con $i = 1,2,\dots,n$ - Bisogna determinare il ricavo massimo $r_n$ che si può ottenere tagliando l'asta e vendendone i pezzi. - Un'asta di lunghezza $n$ può essere tagliata in $2^{n-1}$ modi differenti Denotiamo una decomposizione in pezzi utilizzando la normale *notazione additiva* ovvero $7 = 2+2+3$ indica che un asta di lunghezza $7$ viene tagliata in tre pezzi. Se una soluzione ottima prevede il taglio dell'asta in $k$ pezzi, per $1\le k \le n$ allora la decomposizione: $$n = i_1+i_2+\dots+i_k$$dell'asta in pezzi di lunghezza $i_1,i_2,\dots, i_k$ fornisce il ricavo massimo ovvero: $$r_n = p_{i_1}+p_{i_2}+\dots+p_{i_k}$$ --- **Esempio**: di seguito mostriamo un esempio di ricavi massimi per ogni possibile lunghezza della rod ![[Pasted image 20251224103606.png|500]] --- ###### Generalizzando Generalizzando possiamo esprimere i valori di $r_n$ in funzione dei ricavi delle aste più corte ovvero:$$r_n = max(p_n, r_1+r_{n-1},r_2+r_{n-2}, \dots, r_{n-1}+r_{1})$$dove: - $p_n$ corrisponde alla vendita dell'asta di lunghezza $n$ senza tagli - Gli altri $n-1$ argomenti corrispondono al ricavo massimo ottenuto facendo un taglio iniziale in due pezzi di dimensione $i$ e $n-i$ (con $i = 1,2, \dots, n-1$) e poi tagliando in modo ottimale gli ulteriori pezzi ottenendo i ricavi $r_i$ e $r_{n-i}$ Poiché non sappiamo a priori quale valore di $i$ ottimizza i ricavi *dobbiamo considerare tutti i possibili valori di $i$* e selezionare quello che massimizza i ricavi. Per risolvere il problema originale stiamo risolvendo i problemi più piccoli dello stesso tipo questo lo possiamo fare perché il problema del taglio delle aste presenta una *sottostruttura ottima* ovvero le soluzioni ottime di un problema incorporano le soluzioni ottime dei sotto-problemi correlati. Se vediamo ciascuna decomposizione di un'asta come un primo pezzo seguito da un'eventuale decomposizione del pezzo restante, possiamo *riformulare $r_n$ come*: $$r_n = \max_{1\le i \le n}(p_i+r_{n-i})$$quindi possiamo definire il nostro problema come: $$ r(i) = \begin{cases} 0 & \text{se } i = 0 \\ \max_{1 \le k \le i} \{ p(k) + r(i - k) \} & \text{se } i \ge 1 \end{cases}CUT-ROD(p, n)
if n == 0
return 0
q = -infinity
for i = 1 to n
q = max(q, p[i] + CUT-ROD(p, n - i))
return q
Di seguito l’albero di ricorsione con
 Notiamo subito che ci sono dei sotto-problemi che si ripetono più volte, quindi dobbiamo fare uso della memorizzazione per rendere il tutto più efficiente.
Notiamo subito che ci sono dei sotto-problemi che si ripetono più volte, quindi dobbiamo fare uso della memorizzazione per rendere il tutto più efficiente.
Implementazione bottom-up del ROD-CUT con memorizzazione
Globalmente avremo definito:
- array con i valori rispetto alla lunghezza
- array con i valori dei casi già esaminati
ROD-CUT(n)
if n = 0 then
return 0
for i <- 1 to n
m <- P(i) // salviamo il valore senza aver tagliato
for k <- 1 to i-1 DO // proviamo tutti i possibili tagli
if R(k) + R(i-k) > m //vediamo con quale otteniamo il valore migliore
then m <- R(k) + R(i-k) // salviamo il valore migliore ottenuto
R[i] <- m // lo salviamo nei casi già esaminati
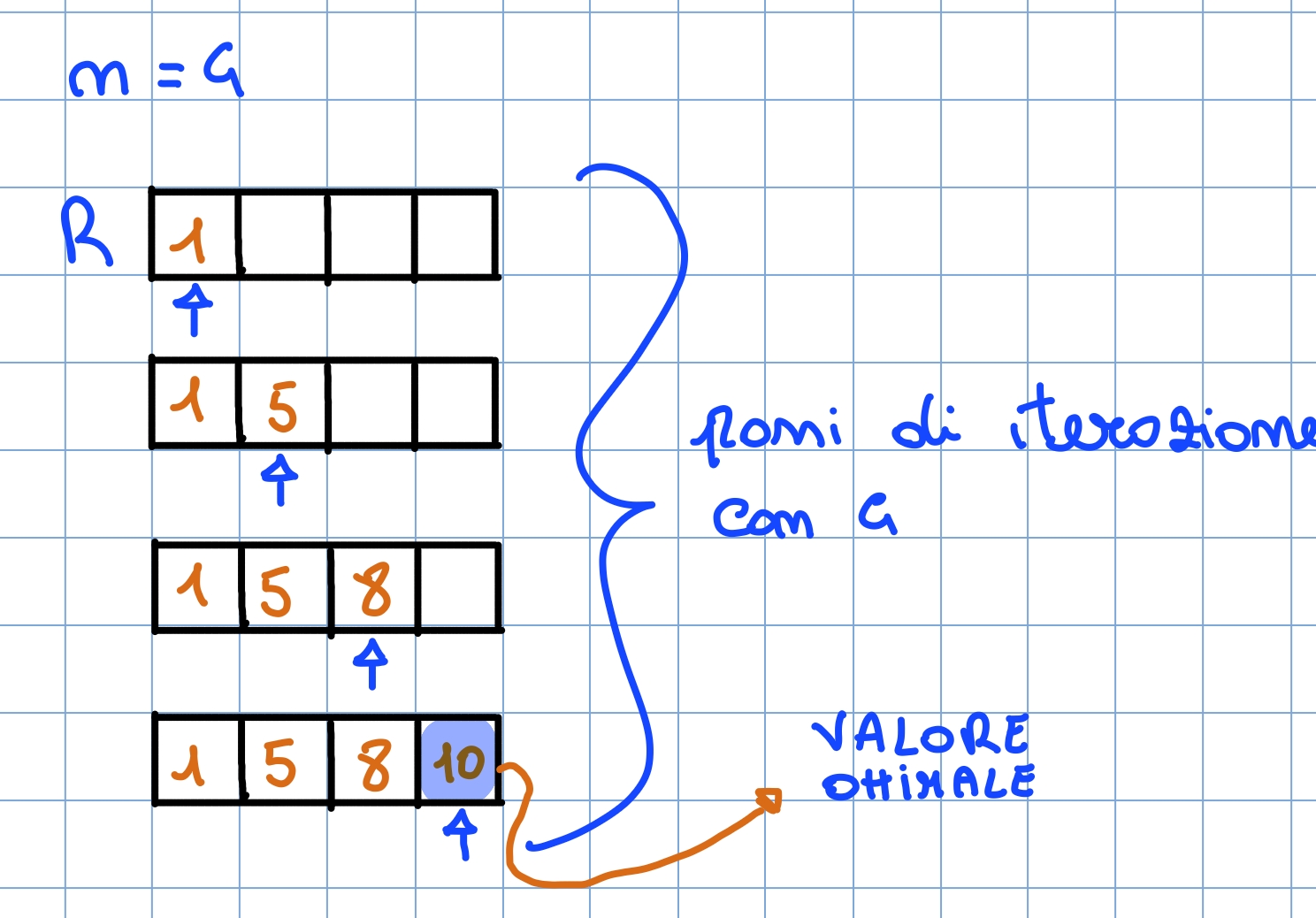 Oltre a memorizzare i casi già risolti ora vogliamo memorizzare il modo migliore per tagliare la rod di lunghezza e lo facciamo usando un array
Oltre a memorizzare i casi già risolti ora vogliamo memorizzare il modo migliore per tagliare la rod di lunghezza e lo facciamo usando un array
Esempio: con sappiamo che una rod di lunghezza deve essere tagliata nel punto per ottenere il taglio migliore
ROD-CUT(n)
R <- new Array(n)
K <- new Array(n)
if n == 0 then
return 0
for i <- 1 to n
m <- P(i)
K[i] <- i
for k <- 1 to i-1 DO
if R[k] + R[i-k] > m then
m <- R[k] + R[i-k]
K[i] <- k //Salviamo il taglio migliore
R[i] <- m
return K
PRINT-CUT(n, K) //Funzione che stampa il taglio migliore dato n
if K[n] == n
print(n)
else
PRINT-CUT(K[n], K)
PRINT-CUT(n - K[n], K)
Sottostruttura ottima
Il problema del rodcut gode della proprietà della sottostruttura ottima di seguito la dimostrazione:
- Prendiamo una soluzione ottima del problema
- Supponiamo che questa soluzione preveda il taglio dell’asta in due pezzi: uno di lunghezza e uno di lunghezza , il valore di questa soluzione quindi è definito come
- Supponendo per assurdo che non sia ottima, abbiamo quindi un’altra decomposizione con valore più alto
- Quindi otteniamo una nuova soluzione ottima definita in questo modo:
- Visto che allora , questo rappresenta una contraddizione in quanto era già ottima
Ottimizzazione della moltiplicazione tra matrici
Questo è un problema di ottimizzazione basato sul prodotto riga per colonna delle matrici, visto che questa operazione gode della proprietà associativa associando i prodotti in maniera diversa è possibile ottenere lo stesso risultato ma con un numero di operazioni scalari minori
Definizione della moltiplicazione tra matrici
Date due matrici e per poter effettuare il prodotto tra queste due dobbiamo rispettare la seguente condizione:
- Il numero delle colonne di deve essere uguale al numero di righe di L’implementazione della moltiplicazione è la seguente:
MATRIX-MULTIPLTY(A,B,p,q,w)
C = NEW MATRIX[p,w]
FOR i = 1 TO p DO
FOR j = 1 TO w DO
C[i,j] = 0
FOR k = 1 TO q DO
C[i,j] = C[i,j] + A[i,k]*B[k,j]
RETURN c
Analizziamo la complessità
Supponendo di voler moltiplicare una sequenza di tre matrici con:
- Il numero di operazioni scalari di sarà uguale a (ottenendo in output una matrice di dimensione ). Quindi la complessità di sarà uguale alla somma della complessità tra i vari prodotti riga per colonna, quindi la complessità cambia in base a quale operazione effettuiamo prima. Esempio Con
- La complessità della parentesizzazione sarà: La complessità della parentesizzazione sarà: Associazioni differenti creano complessità molto differenti, la domanda che adesso ci poniamo è: Come troviamo la parentesizzazione migliore per minimizzare il numero di operazioni scalari?
Fasi della programmazione dinamica
Premesse comuni a tutte le fasi
- Abbiamo una sequenza di matrici
- abbiamo un vettore di interi Le dimensioni della matrice sono
1. Ricerca della sottostruttura ottima Presa la nostra sequenza di matrici supponiamo che una parentesizzazione ottima di quest’ultima suddivida il prodotto in questo modoovviamente anche entrambe le sotto sequenze devono essere parentesizzate in modo ottimo e quindi avremo che: dove sono il numero di moltiplicazioni per .
Dimostrazione: Se ci fosse un modo meno costoso di parentesizzare sostituendo questa parentesizzazione in quella ottima otterremo un’altra parentesizzazione di il cui costo sarebbe minore di quella ottima: una contraddizione. Formalmente: Supponiamo che la sottostruttura non sia ottima. In particolare supponiamo che per la prima parte ( a ) esista una soluzione migliore di quella usata, esiste un tale che: se costruiamo la soluzione ottima con questa versione più economica otteniamo Visto che abbiamo ipotizzato che allora necessariamente Questo è un assurdo in quanto avevamo dichiarato che era già la soluzione ottimale
Usiamo la sottostruttura ottima per trovare una soluzione ricorsiva
2. Definizione ricorsiva di una soluzione ottima Abbiamo la nostra sequenza di matrici: preso un generico avremo che e su questo definiamo:
0 & \text{se } i = j \\ \min_{i \le k < j} (S_{i,k} + S_{k+1,j} + p_{i-1} p_k p_j) & \text{se } i < j \end{cases}$$ Segue l'implementazione: ``` MATRIX-CHAIN-ORDER(p, i, j): if i == j: return 0 sm = +infinity // elemento più grande for k from i to j-1: // Chiamate ricorsive per calcolare i costi dei sottoproblemi res_sinistro = MATRIX-CHAIN-ORDER(p, i, k) res_destro = MATRIX-CHAIN-ORDER(p, k+1, j) // Calcolo del costo attuale: costo sx + costo dx + costo moltiplicazione finale costo_attuale = res_sinistro + res_destro + p[i-1] * p[k] * p[j] if sm > costo_attuale: sm = costo_attuale return sm ``` Se eseguiamo questa funzione con $i = 1$ e $j = 4$ cerchiamo il modo ottimale di moltiplicare $A_1, A_2, A_3, A_4$ e otteniamo il seguente albero di ricorsione: ![[Pasted image 20251226111919.png|500]] dalla quale notiamo subito che ci sono dei sotto problemi che si ripetono quindi dobbiamo usare una approccio bottom-up per rendere più efficiente l'algoritmo **3. Ricerca di una soluzione ottima usando un approccio bottom-up** Per risolvere il problema dei sotto problemi che si ripetono dobbiamo fare uso della memorizzazione, in questo caso non attraverso un array ma attraverso una matrice, visto che abbiamo due indici. Data la matrice $S$ possiamo dire che: - $S[i,j]$ è il costo minimo per moltiplicare le matrici da $A_i$ fino ad $A_j$ - la diagonale principale contiene sempre $0$ perché moltiplicare una matrice per stesse non richiede alcuna operazione - Visto che l'algoritmo calcola il costo solo dove $i<j$ sarà sola il triangolo superiore alla diagonale ad essere riempito - Il risultato finale ovvero il costo minimo per moltiplicare la sequenza di $n$ matrici si trova in posizione $S[1,n]$ ``` MATRIX-CHAIN-ORDER(P, n) S = new matrix(n, n) // Inizializzazione diagonale: costo 0 per catene di lunghezza 1 for i = 1 to n do S[i, i] = 0 // Dim 1 // l è la lunghezza della catena for l = 2 to n do // Dim l > 1 for i = 1 to n - l + 1 do j = i + l - 1 S[i, j] = +∞ for k = i to j - 1 do // Calcolo del costo temporaneo costo = S[i, k] + S[k + 1, j] + P[i-1] * P[k] * P[j] // Se il nuovo costo è minore, aggiorna la matrice if S[i, j] > costo then S[i, j] = costo return S[1, n] ``` **ESEMPIO** ![[Screenshot_20251226_122108_Samsung capture.jpg|500]] Questo algoritmo calcola il *costo minimo della soluzione* ma non abbiamo modo di sapere quale sia l'ordine effettivo delle matrici da moltiplicare. Molti algoritmi richiedono di trovare il valore della soluzione ottima, quindi ci potremmo fermare al terzo step, in questo caso però abbiamo bisogno anche ricostruire la parentesizzazione della soluzione ottima in modo da poter effettuare la vera e propria moltiplicazione, da questa esigenza nasce lo step successivo, solitamente opzionale. **4. Costruzione della soluzione ottimale** ``` MATRIX-CHAIN-ORDER(p, n) S = new matrix(n, n) D = new matrix(n, n) for i = 1 to n do: S[i, i] = 0 for l = 2 to n do: for i = 1 to n - l + 1 do: j = i + l - 1 S[i, j] = +infinity for k = i to j - 1 do: # k è il punto di scissione q = S[i, k] + S[k+1, j] + p[i-1] * p[k] * p[j] if S[i, j] > q: S[i, j] = q D[i, j] = k # Memorizza il punto di scissione ottimale return S[1, n] PRINT-CHAIN(D, i, j) if i == j: print "A" + i else: k = D[i, j] print "(" PRINT-CHAIN(D, i, k) PRINT-CHAIN(D, k+1, j) print ")" ``` Mentre l'algoritmo che è rimasto essenzialmente lo stesso si occupa di esplorare e trovare tutti i possibili modi di parentesizzare la catena $k$, la matrice $D[i,j]$ salva esattamente quale indice $k$ ha prodotto la parentesizzazione migliore. La funzione print-chain serve per stampare la parentesizzazione migliore in base ai parametri passati. ###### Complessità Avendo tre cicli annidati la complessità è $O(n^3)$, è una complessità molto alta, infatti questo algoritmo viene utilizzando quando si devono moltiplicare matrici molto grandi dove c'è un vero e proprio guadagno. ### Distanza di Editing ###### Introduzione al Problema Il problema fondamentale analizzato riguarda il calcolo della distanza tra due stringhe, $X$ e $Y$. Esistono diverse metriche per valutare questa distanza, come la **Distanza di Hamming** (che considera solo sostituzioni su stringhe di uguale lunghezza) o la più generale **Distanza di Editing** (o distanza di Levenshtein). La Distanza di Editing definisce il numero minimo di operazioni necessarie per trasformare la stringa $X$ nella stringa $Y$. Le operazioni consentite, ciascuna con un costo unitario, sono: 1. **Inserimento** di un carattere. 2. **Cancellazione** di un carattere. 3. **Sostituzione** di un carattere. Consideriamo ad esempio la trasformazione dalla parola "CASA" alla parola "CHIESA". - _CASA_ $\to$ _CHASA_ (Inserimento 'H') - _CHASA_ $\to$ _CHESA_ (Sostituzione 'A' con 'E') - _CHESA_ $\to$ _CHIESA_ (Inserimento 'I') ###### Definizione Formale e Ricorsiva Date due stringhe: - $X$ di lunghezza $n$, dove $x_i = X[1 \dots i]$ è il prefisso di lunghezza $i$. - $Y$ di lunghezza $m$, dove $y_j = Y[1 \dots j]$ è il prefisso di lunghezza $j$. Definiamo $ED(i, j)$ come la distanza di editing tra i prefissi $x_i$ e $y_j$. La soluzione può essere espressa ricorsivamente: **Casi Base** Se una delle due stringhe è vuota, la distanza è pari alla lunghezza dell'altra stringa (tutti inserimenti o cancellazioni): - $ED(i, 0) = i$ - $ED(0, j) = j$ **Passo Ricorsivo** Per calcolare $ED(i, j)$ con $i, j > 0$, consideriamo i caratteri $x_i$ e $y_j$: 1. Se $x_i = y_j$ (Match): Non è necessaria alcuna operazione sui caratteri correnti. Il costo è ereditato dai prefissi precedenti: $$ED(i, j) = ED(i-1, j-1)$$ 2. Se $x_i \neq y_j$ (Mismatch): Dobbiamo scegliere l'operazione che minimizza il costo tra le tre possibili: - _Sostituzione:_ $ED(i-1, j-1) + 1$ - _Cancellazione (da X):_ $ED(i-1, j) + 1$ - _Inserimento (in Y):_ $ED(i, j-1) + 1$ La formula completa è: $$ED(i, j) = \min(ED(i-1, j) + 1, ED(i, j-1) + 1, ED(i-1, j-1) + \text{costo\_sostituzione})$$ (Nota: il costo di sostituzione è 1 se i caratteri sono diversi, 0 se uguali). ###### Programmazione Dinamica L'approccio ricorsivo puro ("top-down") è inefficiente a causa della ricalcolazione dei sottoproblemi sovrapposti. La soluzione ottimale utilizza la **Programmazione Dinamica** ("bottom-up"), costruendo una tabella (matrice) di dimensione $(n+1) \times (m+1)$. **Algoritmo per il calcolo della Distanza (EDT)** *Input*: Stringhe $X, Y$ di lunghezza $n, m$. *Complessità*: Tempo $O(n \times m)$, Spazio $O(n \times m)$ (ottimizzabile a $O(\min(n, m))$ se si memorizzano solo le ultime due righe). **Pseudocodice:** ``` EDT(X, Y, n, m) Dichiara matrice ED[0..n, 0..m] // Inizializzazione FOR i = 0 TO n DO ED[i, 0] = i FOR j = 0 TO m DO ED[0, j] = j // Riempimento Matrice FOR i = 1 TO n DO FOR j = 1 TO m DO IF X[i] == Y[j] THEN ED[i, j] = ED[i-1, j-1] ELSE ED[i, j] = min(ED[i, j-1], // Inserimento ED[i-1, j], // Cancellazione ED[i-1, j-1]) // Sostituzione + 1 ``` ###### Ricostruzione della Soluzione Ottima Una volta compilata la matrice, il valore in $ED[n, m]$ rappresenta il costo minimo. Per trovare la sequenza di operazioni, si esegue un "backtracking" dalla cella $(n, m)$ alla cella $(0, 0)$. **Pseudocodice Ricostruzione:** ``` PRINT-EDT(ED, X, Y, n, m) i = n, j = m WHILE (i > 0 OR j > 0) IF (i > 0 AND j > 0 AND X[i] == Y[j]) THEN // Match: nessun costo, ci spostiamo in diagonale i = i - 1 j = j - 1 ELSE // Determiniamo da quale cella proviene il minimo min_val = min(ED[i, j-1], ED[i-1, j], ED[i-1, j-1]) IF (j > 0 AND min_val == ED[i, j-1]) THEN STAMPA("Inserimento di " + Y[j]) j = j - 1 ELSE IF (i > 0 AND min_val == ED[i-1, j]) THEN STAMPA("Cancellazione di " + X[i]) i = i - 1 ELSE STAMPA("Sostituzione di " + X[i] + " con " + Y[j]) i = i - 1 j = j - 1 ``` --- ### Longest Common Substring Date due stringhe X e Y devo cercare la più lunga stringa di caratteri **consecutivi** comune a entrambe le stringhe. Vediamo se questo problema può essere risolto tramite la prog dinamica Ricordiamo che dobbiamo dimostrare 2 cose: 1) la soluzione ottima di un problema contiene al suo interno le soluzioni ottime dei suoi sotto problemi 2) definire un approccio ricorsivo per risolvere il problema ###### Sottostruttura ottima: **Definizione del sotto problema:** Definiamo $L(i, j)$ come la lunghezza della più lunga sottostringa comune che **termina esattamente** agli indici $i$ di $X$ e $j$ di $Y$ (ovvero il "suffisso comune"). **La Tesi:** Se i caratteri $X[i]$ e $Y[j]$ sono uguali, allora la lunghezza del suffisso comune che termina in $(i, j)$ dipende direttamente dalla lunghezza del suffisso comune che terminava in $(i-1, j-1)$. **La Dimostrazione (Logica):** Supponiamo che $X[i] == Y[j]$. Poiché stiamo cercando una **sottostringa** (caratteri _consecutivi_), il carattere corrente estende semplicemente ciò che c'era immediatamente prima. - Se la soluzione per $(i, j)$ è una stringa di lunghezza $K > 1$, significa che i caratteri $X[i]$ e $Y[j]$ sono l'ultimo carattere di questa stringa. - Se rimuoviamo questo ultimo carattere, rimaniamo con una sottostringa comune di lunghezza $K-1$ che termina agli indici $i-1$ e $j-1$. - Affinché la soluzione a $(i, j)$ sia **ottima** (massima), anche la soluzione a $(i-1, j-1)$ deve essere **ottima**. Se ci fosse un suffisso comune più lungo a $(i-1, j-1)$, potremmo aggiungerci $X[i]$ (che è uguale a $Y[j]$) ottenendo un risultato migliore per $(i, j)$, contraddicendo l'ipotesi iniziale. Longest ###### Definizione funzione ricorsiva: Dati due indici $i$ e $j$ (rispettivamente per le stringhe $X$ e $Y$) sfrutteremo una matrice per memorizzare i risultati e la soluzione sarà la casella con valore massimo della matrice: **Caso Base:** Se uno degli indici è 0 (stringa vuota o prima dell'inizio), non c'è nessuna stringa comune. $$L(i, 0) = 0, \quad L(0, j) = 0$$ **Caso 1: I caratteri corrispondono ($X[i] == Y[j]$)** Poiché i caratteri sono uguali, estendiamo la sottostringa comune trovata nel passo precedente (la "diagonale" precedente nella matrice). $$L(i, j) = 1 + L(i-1, j-1)$$ _Perché $i-1, j-1$?_ Perché per mantenere la **consecutività**, dobbiamo guardare i caratteri immediatamente precedenti in entrambe le stringhe. **Caso 2: I caratteri NON corrispondono ($X[i] \neq Y[j]$)** Poiché una sottostringa deve essere consecutiva, se i caratteri attuali sono diversi, la catena si **spezza**. Non possiamo "saltare" un carattere. $$L(i, j) = 0$$ Il suffisso comune che _termina_ in questi indici ha lunghezza 0. Se dopo che la catena si spezza il contatore di caratteri torna a 0 e si ripete la procedura fino a quando non si raggiungono i casi base. ###### Soluzione con programmazione dinamica: **Logica dell'algoritmo:** 1. Creiamo una matrice `dp` di dimensione $(m+1) \times (n+1)$. 2. Iteriamo sulle stringhe. 3. Se $X[i] == Y[j]$, incrementiamo il valore della diagonale precedente ($dp[i-1][j-1] + 1$). 4. Se $X[i] \neq Y[j]$, mettiamo $0$. 5. Teniamo traccia di una variabile `max_len` durante il processo. ``` dp[][]= new matrix(m+1,n+1) maxLength = 0 endIndex = 0 for i from 1 to m+1 do: for j from 1 to n+1 do: if X[i] == Y[j]: dp[i][j] = dp[i-1][j-1] +1 if dp[i][j] > maxLength: maxLength = dp[i][j] endIndex = i else: dp[i][j] = 0 LCS = X[endIndex - maxLenght : endIndex] return LCS ``` > [!TIP] > > $$endIndex - maxLenght : endIndex$$ > indica lo slicing della stringa da endIndex - maxLength a endIndex. > *Esempio*: endIndex = 5 maxLength = 2 ---> da 3 a 5 ### Longest Common Subsequence (LCS) Date due sequenze $X$ e $Y$, il problema consiste nel trovare la più lunga sottosequenza comune a entrambe. A differenza delle sottostringhe, una **sottosequenza** non richiede che gli elementi siano consecutivi nella sequenza originale, ma devono mantenere lo stesso ordine relativo. Ad esempio, data $X = \langle A, B, C, B, D, A, B \rangle$, la sequenza $\langle B, C, D, B \rangle$ è una sua sottosequenza. Vediamo come risolvere questo problema tramite la programmazione dinamica. ###### Sottostruttura ottima **Sottostruttura ottima di una LCS** Siano $X = \langle x_1, x_2, \dots, x_m \rangle$ e $Y = \langle y_1, y_2, \dots, y_n \rangle$ le sequenze; sia $Z = \langle z_1, z_2, \dots, z_k \rangle$ una qualsiasi LCS di $X$ e $Y$. 1. Se $x_m = y_n$, allora $z_k = x_m = y_n$ e $Z_{k-1}$ è una LCS di $X_{m-1}$ e $Y_{n-1}$. 2. Se $x_m \neq y_n$, allora $z_k \neq x_m$ implica che $Z$ è una LCS di $X_{m-1}$ e $Y$. 3. Se $x_m \neq y_n$, allora $z_k \neq y_n$ implica che $Z$ è una LCS di $X$ e $Y_{n-1}$. > [!TIP] > > In questa definizione partiamo dalla fine della nostra stringa, se le stringhe sono uguali allora quel carattere deve essere salvato nella sottostringa comune $z$ e quindi il problema si riduce di $1$, se le stringhe non sono uguali il problema resta quello di trovare la sottostringa comune ignorando quel carattere ecco perché: ($X_{m-1}$ e $Y$) o ($X$ e $Y_{n-1}$) **Dimostrazione** 1. Visto che deve essere $z_k = x_m = y_n$. Ora, il prefisso $Z_{k-1}$ è una sottosequenza comune di $X_{m-1}$ e $Y_{n-1}$ di lunghezza $k - 1$. Vogliamo dimostrare che questo prefisso è una LCS. Supponiamo per assurdo che ci sia una sottosequenza comune $W$ di $X_{m-1}$ e $Y_{n-1}$ di lunghezza maggiore di $k - 1$. Allora, accodando $x_m = y_n$ a $W$ si ottiene una sottosequenza comune di $X$ e $Y$ la cui lunghezza è maggiore di $k$, che è una contraddizione. 2. Se $z_k \neq x_m$, allora $Z$ è una sottosequenza comune di $X_{m-1}$ e $Y$. Se esistesse una sottosequenza comune $W$ di $X_{m-1}$ e $Y$ di lunghezza maggiore di $k$, allora $W$ sarebbe anche una sottosequenza comune di $X_m$ e $Y$, contraddicendo l’ipotesi che $Z$ sia una LCS di $X$ e $Y$. 3. La dimostrazione è simmetrica a quella del punto (2). ###### Definizione funzione ricorsiva Definiamo $c[i, j]$ come la lunghezza di una LCS delle sequenze $X_i$ e $Y_j$. **Caso Base:** Se una delle sequenze ha lunghezza 0, la lunghezza della LCS è 0. $$c[i, j] = 0 \quad \text{se } i=0 \text{ oppure } j=0$$ **Caso 1: I caratteri corrispondono ($x_i == y_j$):** Abbiamo trovato un elemento della LCS. Incrementiamo di 1 la lunghezza della LCS trovata nei prefissi precedenti ($i-1, j-1$). $$c[i, j] = c[i-1, j-1] + 1$$ **Caso 2: I caratteri NON corrispondono ($x_i \neq y_j$):** Non possiamo estendere la sottosequenza con l'attuale coppia. Dobbiamo cercare la soluzione migliore risolvendo i due sottoproblemi possibili (ignorando l'ultimo carattere di $X$ o ignorando l'ultimo carattere di $Y$) e prendendo il massimo. $$c[i, j] = \max(c[i, j-1], c[i-1, j])$$ ###### Soluzione con programmazione dinamica **Logica dell'algoritmo:** 1. Creiamo una tabella $c$ di dimensione $(m+1) \times (n+1)$ per memorizzare le lunghezze. 2. Creiamo una tabella $b$ per memorizzare le "frecce" che indicano quale sottoproblema ha generato la soluzione ottima ($\nwarrow, \uparrow, \leftarrow$) . 3. Inizializziamo la prima riga e la prima colonna a 0 . 4. Iteriamo attraverso la tabella riga per riga (bottom-up). 5. Se $x_i == y_j$, il valore deriva dalla diagonale in alto a sinistra + 1 (freccia $\nwarrow$). 6. Se $x_i \neq y_j$, il valore è il massimo tra il vicino in alto (freccia $\uparrow$) e il vicino a sinistra (freccia $\leftarrow$) . 7. Il valore in $c[m, n]$ è la lunghezza della LCS. Per ricostruire la stringa, seguiamo le frecce a ritroso partendo da $b[m, n]$ . ``` LCS-LENGTH(X, Y) m = X.length n = Y.length Siano b[1..m, 1..n] e c[0..m, 0..n] nuove tabelle // Inizializzazione casi base for i = 1 to m: c[i, 0] = 0 for j = 0 to n: c[0, j] = 0 // Calcolo Bottom-up for i = 1 to m: for j = 1 to n: if X[i] == Y[j]: c[i, j] = c[i-1, j-1] + 1 b[i, j] = "↖" // Corrisponde a diagonale elseif c[i-1, j] >= c[i, j-1]: c[i, j] = c[i-1, j] b[i, j] = "↑" // Corrisponde a 'su' else: c[i, j] = c[i, j-1] b[i, j] = "←" // Corrisponde a 'sinistra' return c, b ``` Per stampare la sequenza effettiva, si usa una procedura ricorsiva che segue la tabella $b$ a ritroso: ``` PRINT-LCS(b, X, i, j) if i == 0 or j == 0: return if b[i, j] == "↖": PRINT-LCS(b, X, i-1, j-1) print X[i] elseif b[i, j] == "↑": PRINT-LCS(b, X, i-1, j) else: PRINT-LCS(b, X, i, j-1) ``` # Algoritmi golosi ### Introduzione ###### Definizione Un'altra strategia che possiamo sfruttare per risolvere problemi di ottimizzazione è la strategia greedy, in italiano golosa. Un algoritmo goloso fa sempre la scelta che sembra ottima in un determinato momento, ovvero fa una scelta *localmente ottima*, nella speranza che tale scelta porterà a una soluzione globalmente ottima. La scelta greedy che viene fatta cambia da problema a problema. ### Problema dello zaino ###### Definizione Riprendendo il problema dello zaino presentato nella lezione 2, ricordiamo che: - $k$ capienza dello zaino - $A = \{a_1,a_2,\dots,a_n\}$ - $P(a_i) =$ peso dell'oggetto - $V(a_i) =$ valore dell'oggetto - *Obbiettivo*: massimizzare il guadagno in questo caso però ogni oggetto ha lo stesso valore ovvero: $$v(a) = 1 \; \forall a \in A$$ Banalmente ciò che dobbiamo massimizzare è il numero di oggetti. Un ottima strategia (greedy) è quella di scegliere l'oggetto con il peso minore. ###### Dimostrazione scelta greedya_w : P(a_w) = \min{\text{Peso}(a_j) : a_j \in A}
Ovvero $a_w$ scelta greedy. $S \subseteq A$ è una soluzione ottima. Allora $a_w \in S$. Ipotizziamo per assurdo che $a_w \notin S$.a_\phi \rightarrow P(a_\phi) = \min{P(a_j) : a_j \in S}
Ovvero $a_\phi$ elemento meno pesante della soluzione ottima. Allora consideriamo $S - \{a_\phi\}$ e consideroS’ = (S - {a_\phi}) \cup {a_w}
Per ipotesi, $S$ è una soluzione ottima, per cui\sum_{a \in S} P(a) \leq k
undefined\delta(u, v) = \begin{cases} \min { w(p) : u \stackrel{p}{\leadsto} v } & \text{se esiste un cammino da } u \text{ a } v \ \infty & \text{negli altri casi} \end{cases}
undefinedl_{i,j}^d = \begin{cases} w_{i,j} & \text{se } d = 1 \ \min_{1 \le k \le n} \left( l_{i,k}^{d/2} + l_{k,j}^{d/2} \right) & \text{se } d > 1 \end{cases}
Da questo nasce la una nuova implementazione della funzione $APSP$: ``` Fast-APSP(W) n = m // numero di vertici L^1 = W d = 1 while d < n - 1 do L^{2d} = EXTEND-APSP(L^d, L^d) d = 2d return L^d ``` Se inseriamo un iterazione in più otteniamo lo stesso risultato del ciclo finale di bellam-ford (la verifica di cicli negativi) ###### Complessità Il Fast-APSP ha complessità $O(V^3\log V)$ che è un miglioramento lieve rispetto a quello di bellam-ford ### Floyd-Warshall ###### Definizione D'ora in avanti indicheremo con $V_K$ il sottoinsieme di $V$ formato dai primi $K$ nodi\begin{aligned} V_k &= { v_1, v_2, v_3, \dots, v_k } \ V_0 &= { } \ V_1 &= { v_1 } \ V_2 &= { v_1, v_2 } \ &\vdots \ V_n &= V \end{aligned}
La dimensione del problema al passo k è definita *dalla possibilità di includere il k-esimo nodo come potenziale punto di passaggio per tutte le coppie (u,v).* ![[Pasted image 20260117105549.png]]considerando i due cammini evidenziati in blu ottengo un cammino che passa da $k$, ora bisogna capire quale dei due cammini è il migliore. E lo facciamo usando una matrice$$D^K[i,j] = \delta^K(i,j) = \begin{cases} w[i, j] & \text{se } k = 0 \\ \min \left( D^{k-1}[i, j], D^{k-1}[i, k] + D^{k-1}[k, j] \right) & \text{se } k > 0 \end{cases}$$ è molto simile al caso di programmazione dinamica che abbiamo fatto precedentemente, però in questo caso non dobbiamo provare tutte le $k$ ad ogni passaggio perché $k$ è già definita ###### Implementazione Dalla definizione di matrice precedentemente presentata otteniamo il seguente algoritmo: ``` FLOYD-WARSHALL(W) n = m // numero di vertici D^0 = W for k = 1 to n do D^k = new Matrix(n, n) for i = 1 to n do for j = 1 to n do // Se il cammino attraverso k è più breve, aggiorna if (D^{k-1}[i, j] > D^{k-1}[i, k] + D^{k-1}[k, j]) D^k[i, j] = D^{k-1}[i, k] + D^{k-1}[k, j] else D^k[i, j] = D^{k-1}[i, j] return D^n ``` Inoltre vogliamo creare un albero dei cammini minimi, per fare ciò dobbiamo tenere traccia dei predecessori dei nostri nodi, e lo facciamo usando una seconda matrice definita in questo modo:\pi^K[i, j] = \begin{cases} i & \text{se } [i, j] \in E \ \text{null} & \text{altrimenti} \end{cases}
![[Pasted image 20260117111058.png]] Di conseguenza il nostro algoritmo diventa: ``` Floyd-Warshall(W) n = m // numero di vertici D^0 = W // Inizializzazione della matrice dei predecessori Pi Pi^0 = new Matrix(n, n) for i = 1 to n do for j = 1 to n do if (i != j and W[i, j] < infinity) Pi^0[i, j] = i else Pi^0[i, j] = null // Ciclo principale dell'algoritmo for k = 1 to n do D^k = new Matrix(n, n) Pi^k = new Matrix(n, n) for i = 1 to n do for j = 1 to n do // Manteniamo i valori precedenti come base D^k[i, j] = D^{k-1}[i, j] Pi^k[i, j] = Pi^{k-1}[i, j] // Controllo se il passaggio per il nodo k migliora il cammino if (D^{k-1}[i, j] > D^{k-1}[i, k] + D^{k-1}[k, j]) D^k[i, j] = D^{k-1}[i, k] + D^{k-1}[k, j] Pi^k[i, j] = Pi^{k-1}[k, j] // Aggiorna il predecessore return D^n, Pi^n ``` ###### Esempio ![[Screenshot_20260117_112309_Samsung capture.jpg|500]] Ci sono delle euristiche da seguire per ridurre il carico di lavoro: *in generale devo fare len(V)+1 matrici (la prima è quella di adiacenza)* 1. Riscrivo la riga e la colonna $k$ perché sicuramente non cambia 2. Riscrivo la diagonale principale perché è sicuramente sempre 0 (non capita mai di avere dei cappi) 3. Prendo la colonna $k$ e se in una delle celle che la compongo ci trovo un $\infty$ riscrivo tutta la riga 4. Prendo la riga $k$ e se in una delle celle che la compongono ci trovo un $\infty$ riscrivo tutta la colonna ###### Complessità La complessità di questo algoritmo è $O(V^3)$ ottima rispetto a tutto quello che abbiamo trovato fino ad adesso. In generale si preferisce questo algoritmo anche quando servono i cammini minimi da una singola sorgente, perché ha la stessa complessità di bellam-ford.